
简介
hello world
- C语言的作者:
Dennis Ritchie(丹尼斯·里奇)在《C程序设计语言》中,第一次引入了打印hello world的案例,后面的其他语言争相效仿,以示敬意。
//main.c |
IDE
- 对于集成开发环境(IDE,Integrated Development Environment )而言,减少了环境配置,合并了流程,使其便于快速开发。c语言的编译器常用的vc++和qt。
Qt
- qt的发音为cute。
安装
| qt安装 | |
|---|---|
| 下载 | 下载地址选择最新版qt-opensource-windows-x86-5.14.2.exe |
| 勾选组件 | 建议全部勾选 |
| 环境变量 | 设置qt的目录...\qt\5.10.1\mingw53_32\bin和...\qt\Tools\mingw530_32\bin |
快捷键
| 快捷键 | |
|---|---|
ctrl+? |
注释选择的代码 |
ctrl+i |
格式化选择的代码 |
ctrl+b |
build,编译程序 |
ctrl+r |
run,直接编译并运行程序 |
vc++/visual stdio
vscode
从源程序到可执行程序
- 源程序就是一个.txt 的普通文本文件,是经历了哪些过程,变为可执行性文件的呢?大体上分为四个步骤: 预处理 -> 编译 -> 汇编 -> 链接 四个过程。
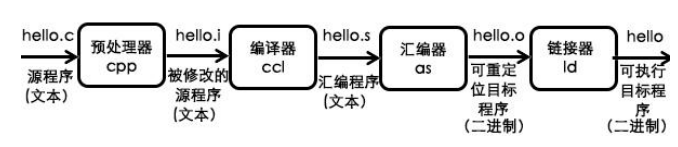
- 预处理:预处理相当于根据预处理命令组装成新的 C 程序,不过常以 i 为扩展名;把头文件声明的变量进行了汇总成一个文件,消除了注释(gcc -E main.c -o main.i);
- 编译:转为汇编语言;将得到的 i 文件翻译成汇编代码 .s 文件(gcc -S main.i -o main.s);
- 汇编:将汇编文件翻译成机器指令,并打包成可重定位目标程序的 O 文件。该文件是二进制文件,字节编码是机器指令(gcc -c main.s -o main.o);
- 链接:将二进制文件中用到的库进行链接,将引用的其他 O 文件并入到我们程序所在的 o 文件中,处理得到最终的可执行文件(gcc main.o -o hello);
常用语法
注释
| 注释 | |
|---|---|
| 单行注释 | // |
| 多行注释 | /**/ |
| 条件编译 | 使用条件编译的方式实现多行注释 #if 0 ... #endif |
内存模型
- 物理基础
- 对于 32 机而言,内存模型线性的,这是硬件基础。左边表示十六进制的访问地址,右边分别表示寻址的最小单位Byte和内存的最小单位 bit,1Byte = 8bit。32位机最大的寻址空间是4GB,64位机是16EB。
| 内存大小单位 |
|---|
| 1 B = 8 b |
| 1 KB = 1024 B |
| 1 MB = 1024 KB |
| 1 GB = 1024 MB |
| 1 TB = 1024 GB |
| 1 PB = 1024 TB |
| 1 EB = 1024 PB |
进程空间
- 程序,是经源码编译后的可执行文件,可执行文件可以多次被执行,比如我们可以多次打开 office。
- 进程,是程序加载到内存后开始执行,至执行结束,这样一段时间概念,多次打开的 wps,每打开一次都是一个进程,当我们每关闭一个 office,则表示该进程结束。
- 程序是静态概念,而进程动态/时间概念
栈内存
- 栈中存放任意类型的变量,但必须是
auto类型修饰的,即自动类型的局部变量,随用随开,用完即消。内存的分配和销毁系统自动完成,不需要人工干预。 - 栈的大小并不大,他的意义并不在于存储大数据,而在于数据交换。查看栈的大小:
ulimit -a
堆内存
- 堆内存可以存放任意类型的数据,但需要自己申请与释放。
- 堆大小,想像中的无穷大,对于栈来说,大空间申请,唯此,无它耳。但实际使用中,受限于实际内存的大小和内存是否连续性
堆内存的申请与释放
- 申请和初始化的最小单位是字节(char类型:00-FF)
| 函数 | 所在文件 | 说明 |
|---|---|---|
void * malloc(size_t _Size); |
stdlib.h | 申请堆内存空间并返回,所申请的空间并未初始化。常见的初始化方法是memset字节初始化。失败返回空指针NULL。 |
void memset() |
stdlib.h | 字节单位初始化 |
void *calloc(size_t nmemb, size_t size); |
stdlib.h | 申请堆内存空间并返回,所申请的空间,自动清零。 |
void *realloc(void *ptr, size_t size); |
stdlib.h | 扩容(缩小)原有内存的大小。通常用于扩容,缩小会会导致内存缩去的部分数据丢失。 |
void free(void *p); |
stdlib.h | 释放申请的堆内存 |
int * p = (int*)malloc(1024*1024*1024); //申请堆空间。1G完全无压力 |
堆与栈空间的返回
- 对于调用的函数,返回的要求:
- 数值是可以返回的
- 地址也是可以返回
- 栈上的空间不可以返回, 原因,随用随开,用完即消
- 堆上的空间,是可以返回的
常量与变量
常量
- 常量(Constant)量是程序中不可改变的量,常以字面量(Literal),或者宏(Macro)的方式出现。 主要用于赋值或是参与计算,并且常量也是用类型的。
常量的类型
-
整型常量的三种表形式
- 十进制表示:除表示整数 0 外,不以 0 开头(以 0 开头的数字串会被解释成八进制数)。负数在前面加负号’ - ‘,后缀’ l ‘或’ L ‘表示长整型,’ u ‘或’ U '表示无符号数。例:345 31684 0 -23456 459L 356l 56789u 567LU
- 八进制表示:以数字 0 开头的一个连续数字序列,序列中只能有 0-7 这八个数字。例:045 -076 06745l 0177777u
- 十六进制表示:以 0X 或 0x 开头的连续数字和字母序列,序列中只能有 0-9、A-F 和 a-f 这些数字和字母,字母 a、b、c、d、e、f 分别对应数字 10、11、12、13、14、15,大小写均可。例:0x10 0X255 0xd4ef 0X6a7bL
-
实型常量有两种表示形式:
- 小数形式:由数字和小数点组成,必须有小数点。例:4.23、0.15、.56、78.、0.0
- 指数形式:以幂的形式表示,以字母 e 或 E 后跟一个以 10 为底的幂数。
- 字母 e 或 E 之前后必须要有数字。
- 字母 e 或 E 后面的指数必须为整数,字母 e 或 E 的前后及数字之间不得有空格。
- 默认是 double 型,后缀为“f”或“F”即表示该数为 float 型,后缀“l”或“L”表示 long double 型。例:.5E3 4.5e0 34.2f .5F 12.56L 2.5E3L
-
字符常量的表现形式比较简单。以单引号引起来的一个字符。例:‘a’ ‘b’ ‘c’
-
字符串常量的表现形式比较简单。以双引号引起来的一串字符。例:“a” "abcdefg
变量
- 当我们用计算机语言来描述世界的时候,比如一个人的性别,身高,体重,收入,就需要变量来存储,变量之间不仅需要名字来识别,还需要类型来进行限定。
关键字
- C语言的32个保留关键字
char short int long float double if else return do while for switch case break continue default goto sizeof auto register static extern unsigned signed typedef struct enum union void const volatile |
变量的命名规则
- 驼峰命名法
变量作用域、生命周期、修饰符
作用域
- 某事物起作用或有效的区域,称之为作用域。{}是作用域的限定符。{}以内的区域称为局部作用域,{}以外的称为全局作用域。
- 局部变量:作用域起始于定义处,结束在右大括号。
- 全局变量/函数:全局量,在多文件编程中,可以通 extern 声明的方式,将作用域扩展到其它文件中去。
- 同一作用域内不能有重名标识符。
- 若未赋值 ,系统将其初始化为,零。
- 全局命名污染,全局变量是指同一工程内的所有c文件中的全局变量,在全局作用域内,如果有重名则会造成重定义。
生命周期
- 局部变量:局部变量的生命周期,同其所在的函数。局部变量随着函数的执行而有生命,随着函数的执行结束而生命截止。
- 全局变量:全局变量的生命周期同进程,或是 main()函数或进程。
修饰符
- 修饰符格式:
auto int a;
auto
- auto修饰的变量存储于栈上。它修饰的变量的特点是,随用随开,用完即消。
- 只能修饰局部变量,可以省略,局部变量若无其它的修饰,则默认为 auto。
register
- 只能修饰局部变量,
- 原则上,将内存中的变量升级到 CPU 寄存器中存储,这样访问速度会更快。但由于 CPU 寄存器数量相当有限,通常会在程序优化阶段,被优化为普通的 auto 类型变量。可以通过汇编代码来查看,优化过程(具体优化,与平台和编译相关)。
extern
- 只能用来修饰全局变量,全局变量本身是全局可用的,但是由于文件是单个完成编译,并且编译是自上而下的,所以说,对于不是在本范围内定义的全局变量,要想使用必须用 extern 进行声明,如果不加上 extern ,就会造成重定义。
- C 语言,是单文件编译的,然后再将编译的.o 文件同库一起链接成可执行文件。正是因为这一点,跨文件使用全局变量,需要声明。
- 注意,经 extern 声明的变量,不可以再初始化。
static
- 局部变量
- static 修饰局部变量,修改了局部变量的生命周期。使其生命周期同进程或是 main()函数。
- static 变量若未初始化,则系统初始化为零,并且只进行一次初始化。
- 全局变量
- static 修饰全局变量,限制了他的外延性。使其成为仅在本文件内部使用的全局变量。
- 我们在前面讲过,全局变量会带来全局空间的命名污染。 这样既保留了全局变量的使用便利性,又不会造成全局空间的命名污染。
- 函数
- 函数本身就是全局可调用的,在编译时,只需要声明,即可完成编译,在链接的时候才去链接实现体。
- static 修饰函数的意义,就在于将全局函数变成了,本文件内的全局函数。
volatile
- volatile设计用来修饰被不同线程访问和修改的变量;volatile的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值。
- volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份
int square(volatile int *ptr){ |
-
使用volatile变量的例子
- 并行设备的硬件寄存器(如:状态寄存器)
- 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
- 多线程应用中被几个任务共享的变量
-
这是区分C程序员和嵌入式系统程序员的最基本的问题:嵌入式系统程序员经常同硬件、中断、RTOS等等打交道,所有这些都要求使用volatile变量。不懂得volatile内容将会带来灾难。
-
注意点:
- 一个参数既可以是const还可以是volatile:一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
- 一个指针可以是volatile:一个例子是当一个中断服务子程序修改一个指向一个buffer的指针时。
数据类型
类型总览
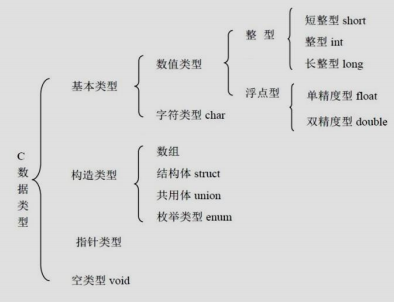
基本类型
整型
| 类型 | 位数(32 位机) | 符号 | 范围 | 科学计数 |
|---|---|---|---|---|
| char | 8 | unsigned | 0-255 | 0-28-1 |
| char | 8 | [signed] | -128-+127 | -27-+27-1 |
| short | 16 | unsigned | 0-65535 | 0-216-1 |
| short | 16 | [signed] | -32768-+32767 | -215-+215-1 |
| int | 32 | unsigned | 0-232-1 | |
| int | 32 | [signed] | -231-+231-1 | |
| long | 32 | unsigned | 0-232-1 | |
| long | 32 | [signed] | -231-+231-1 | |
| long long | 64 | unsigned | 0-264-1 | |
| long long | 64 | [signed] | -263-+263-1 |
浮点型
- 一个浮点数(Floating Point Number)由三个基本成分构成:符号(Sign)、阶码(Exponent)和尾数(Mantissa)。通常,可以用下面的格式来表示浮点数:

| 类型 | 位数(32 位机) | 范围简算 | 精算 | 有效位数 |
|---|---|---|---|---|
| float | 32 | [2-128,2127] | [10-38,10 38] | 6-7 |
| float | 32 | [-2127, -2-128] | [-1038,-10-38] | 6-7 |
| double | 64 | [2-2048,22047] | [10-308,10308] | 15-16 |
| double | 64 | [-22047, -2-2048] | [-10308,-10-308] | 15-16 |
| long double | ||||
| long double |
字符类型
- 计算机是不能存储字符的,只能在显示的时候进行转化。这种转化需要一张表,表里记载了转换规则,这张表,就是ASCII编码表。该表的本质就是一种对应关系。
转义字符
- 一些字符已经被语言征用代表了一些特定用途了,就可以用转义进行控制。
| 字符 | 意义 | ASCII 值 | 备注 |
|---|---|---|---|
| \b | 退格(BS)当前位置向后回退一个字符 | 8 | 转义后,值发生了改变,通常在 0-32 以内表示控制字符。 |
| \r | 回车(CR),将当前位置移至本行开头 | 13 | |
| \n | 换行(LF),将当前位置移至下一行开头 | 10 | |
| \t | 水平制表(HT),跳到下一个 TAB 位置 | 9 | |
| \0 | 用于表示字符串的结束标记 | 0 | 用作字符串结束标志 |
| \ | 代表一个反斜线字符 \ | 92 | 转义后,值并没有发生改变,解决了因被占用,又要作输出时引起的错误。 |
| " | 代表一个双引号字符" | 34 | |
| ’ | 代表一个单引号字符’ | 39 | |
| %% | 代表一个百分号% | 37 | |
| \ddd | 1 到 3 位八进制所代表的任意字符 | 八进制数制 | 可表示任意的字符。注意跟后续字符沾连的问题。 |
| \xhh | 1 到 2 位十六进制所代表的任意字符 | 十六进制数值 | \EA6number |
字符格式化
格式控制
% [标志][输出最小宽度][.精度][长度]类型- 类型:类型字符用以表示输出数据的类型
| 类型 | 语义 | Example |
|---|---|---|
| %d / %i | 有符号 10 进制整型 | 392 |
| %u | 无符号 10 进制整型 | 7235 |
| %o | 无符号 8 进制整型 | 610 |
| %x | 无符号 16 进制整型 | 7fa |
| %X | 无符号 16 进制整型(大写) | 7FA |
| %f | 单/双精度浮点型(默认打印六位小数) | 392.650000 |
| %e | 科学计数 e | 3.9265e+2 |
| %E | 科学计数 E | 3.9265E+2 |
| %g | %e or %f 的缩短版 | 392.65 |
| %G | %E or %F 的缩短版 | 392.65 |
| %c | 字符 | a |
| %s | 字符串 | sample |
| %p | 地址 | b8000000 |
- 宽度:用十进制整数来表示输出的最少位数。若实际位数多于定义的宽度,则按实际位数输出,若实际位数少于定义的宽度则补以空格或 0。
| 标志 | 意义 |
|---|---|
- |
左对齐;默认右对齐 |
+ |
当一个数为正数时,前面加上一个+号,默认不显示 |
0 |
右对齐时,用 0 填充左边未使用的列;默认用空格填充空格 输出值为正时冠以空格,为负时冠以负号 |
# |
对 o 类,在输出时加前缀 o;对 x 类,在输出时加前缀 0x;对 c、s、d、u 类无影响 |
- 精度:精度格式符以“.”开头,后跟十进制整数。本项的意义是:如果输出数字,则表示小数的位数;如果输出的是字符,则表示输出字符的个数;若实际位数大于所定义的精度数,则截去超过的部分。
- 长度:
| length | d i | u o x X | f F e E g G a | c | s | p |
|---|---|---|---|---|---|---|
| (none) | int | unsigned int | float/double | int | char* | void* |
| hh | signed char | unsigned char | ||||
| h | short int unsigned short int | |||||
| l | long int | unsigned long int | wint_t | wchar_t* | ||
| ll | long long、int | unsigned long long、int | ||||
| L | long double |
注意: hh Lf 的平台差异性
printf
- printf 函数称为格式输出函数,其关键字最末一个字母 f 即为“格式”(format)之意。其功能是按用户指定的格式,把指定的数据显示到显示器屏幕上。
- printf 函数调用的一般形式:
printf(“ 格式控制字符串“, [输出表列]);
scanf
- scanf 函数的一般形式为:
scanf(“格式控制字符串”, 地址表列); - 注意事项:
- 待输入变量,必是以其地址的方式呈现。
- 除格式字符,空格,回车,Tab 外,其它需要原样输入。
- 空格 ,Tab, 回车,均可作为输入间隔,以回车作为结束。
- scanf 函数中没有精度控制,如:scanf("%5.2f",&a); 是非法的。不能企图用此语句输入小数为 2 位的实数。
- 在输入字符数据时,若格式控制串中无非格式字符,则认为所有输入的字符均为有效字符。%d %c %c %c
- 如输入的数据与输出的类型不一致时,虽然编译能够通过,但结果将不正确。
- 用scanf函数输入字符时,要在输入控制符%c前面加空格。空格就是用来屏蔽空白符的,%c前没空格,scanf()将读取标准输入流中的第一个字符,%c前有空格,scanf()则读取标准输入流中第一个非空白字符。
putchar && getchar
- putchar形式为:
int putchar ( int character );向屏幕输出一个字符 - getchar形式为:
int getchar ( void );从键盘获得一个字符
puts
puts("");实现换行
构造类型
- 由基本类型组合而成
数组
- 数组,在内存中是一段连续的存储区域 。
一维数组
- 逻辑与声明:
int [10] array; => int array[10]; - 初始化共分五种情况:
- 不初始化 => 成员初始值未知
- 全初始化
- 部分初始化 => 未初始化的部分,自动初始化为零
- 满初始化 => 越界并不潇洒
- 不指定大小初始化 => 经常出没
二维数组
- 声明:
int[4] array[3] => int array[3][4]; - 初始化:
- 不初始化 =>成员初始值未知
- 全初始化
- 部分初始化(行,全局) =>未初始化成员,自动清零
- 满初始化 =>这样太过分了
- 不指定行大小初始化 =>新常态
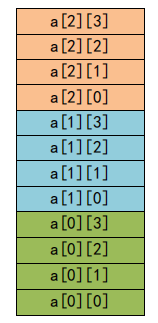
成员访问
- 所有学习过,C 语言的人,可能都会有一个疑问,数组的下标为什么从零开始。
- 因为 c 语言,脱胎于汇编语言,稍微懂点汇编的人,就知道
[ ]是一种基址变址运算符。基于起始位置偏移 0 个单位处,开始存放数据,故下标从 0 处开始。 arr = &arr[0];arr[0] = &arr[0][0],&:reference; * dereference- 一维数组的
arr+1跳跃一个int单位,二维数组的arr+1跳跃一个int[n]单位。
int arr[10]; |
变长数组
- C99 为了增加 c 语言的灵活性,提供了,变长数组的概念,(variable-length array),也简称 VLA。即数组的大小,可以是变量。
- 变长数组,只有一次改变大小的机会,之后不能改变大小。VLA也不能初始化。
int size; |
- 不设置数组长度的初始化,二维数组的省略行。
int array[] = {1,2,3,4,5,6,7,8,9,0,11,22}; |
数组名的二义性
-
数组名,是数组的唯一标识符,既表示一种构造数据类型的大小,也表示访问组中的成员的首地址用来访问数据成员使用。
-
结构体的类型与成员访问,是分开的,为此增加了成员运算符。而数组名,却是一身而兼二任的,这也是简洁的需要。
-
一维数组名,从总体来看,他是一种构造类型,同时他又承担了,访问每个数组元素的责任。所以数组名, 就有两重性。
-
数组名,是数组的唯一标识符。二维数组也是如此,二维数组本质是一种嵌套关系,其本质是一种一维数组,每个一维数组成员又是一个一维数组。
结构体
- struct 是构造新类型的关键字 ,有了它,就可以构造任意的构造类型了。
结构体定义
| 结构体 | 定义 | 声明 |
|---|---|---|
| 无名构造类型 | struct{char name[30];}stu,stu2,stu3; |
|
| 有名构造类型 | struct student{char name[30];}stu; |
struct student s1 |
| 别名构造体类型 | typedef struct student{char name[30];}STUDENT; |
STUDENT stu |
typedef
typedef对现有类型取别名,不能创造新的类型- 用现有类型生成变量;
- 在变量定义之前加
typedef; - 将定义的变量换成其他的别名;
typedef和#define区别#define是c语言的宏,在预处理阶段处理;#define N int #endiftypedef是c语言的语句,参与编译;
结构体变量初始化
//初始化 |
结构体变量成员访问和赋值
- 结构体成员内存分布:首成员在低地址,尾成员在高地址。
- 点成员运算符(.)
strcpy(stu.name,"zhangsan"); //通过strcpy进行赋值 |
- 指向成员运算符
->,(*).,常见有指向栈内存变量或指向堆内存变量的表示方法。
STUDENT stu s ; STUDENT stu * ps; //*ps等价于s |
STUDENT * ps = &stu; //栈内存的指针表示法 |
- 结构体之间的赋值,必须是同类型的:
STU s,s2;s=s2; - 成员运算符的本质,依然是通过计算偏移来实现的。此处不考虑内存对齐等原因。
结构体数组
STUDENT stu[4] = { |
结构体嵌套
struct person{ |
结构体大小
- 结构体类型,本身不占有内存空间,只有它生成的变量才占有内存空间的。
- 首成员在低地址,尾成员在高地址。
- 内存对齐
- 一个成员变量需要多个机器周期去读的现象,称为内存不对齐。为什么要对齐呢?本质是牺牲空间,换取时间的方法。
- 对齐规则
- x86(linux 默认
#pragma pack(4), window 默认#pragma pack(8))。linux 最大支持 4字节对齐。 - 方法:
- 取 pack(n)的值(n= 1 2 4 8…),取结构体中类型最大值 m。两者取小即为外对齐大小
Y= (m<n?m:n)。 - 将每一个结构体的成员大小依次与Y比较,取小者为 X,作为内对齐大小;
- 所谓按 X 对齐,即为地址(设起始地址为 0)能被 X 整除的地方开始存放数据;
- 外部对齐原则是依据 Y 的值(Y 的最小整数倍),进行补空操作。
- 取 pack(n)的值(n= 1 2 4 8…),取结构体中类型最大值 m。两者取小即为外对齐大小
- Y用来进行空间跳转,最后没有填满的补0,X用来定位起始地址。外对齐和内对齐结合,可以充分利用内存空间。
- x86(linux 默认
结构体易错的注意点
- 向结构体内未初始化的指针拷贝:结构体中,包含指针,注意指针的赋值,切不可向未知区域拷贝。
struct student |
struct student *ps = (struct student*)malloc(sizeof(struct student)); // 只为结构体在堆上开辟了空间,其成员指针的空间没有开辟,需要ps->name = (char*)malloc(100); |
- 未释放结构体内指针所指向的空间:从内向外依次释放空间。
int main() |
共用
-
Union,在 C 语言中,不同的成员使用共同的存储区域的数据构造类型称为共用体,简称共用,又称联合体。共用体在定义、说明和使用形式上与结构体相似。两者本质上的不同仅在于使用内存的方式上。
-
特点
- 共用体变量的地址和它的各成员的地址都是同一地址。
- 同一个内存段可以用来存放几种不同类型的成员,但在每一瞬时只能存放其中一种,而不是同时存放几种。
- 共用体变量中起作用的成员是最后一次存放的成员,在存入一个新的成员后原有的成员就失去作用。
- 共用体类型可以出现在结构体类型定义中,也可以定义共用体数组。反之,结构体也可以出现在共用体类型定义中,数组也可以作为共用体的成员。
定义
union untest |
内存分析
- 大小
- 共用体占用空间的大小取决于类型长度最大的成员。
- 而结构体变量不考虑内存对齐,所占内存长度是各成员占的内存长度之和。每个成员分别占有其自己的内存单元。
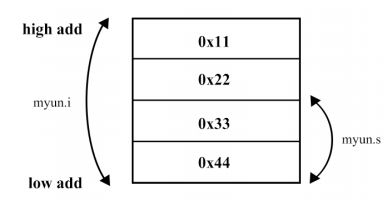
- 成员地址
- 共用体变量
myun的三个成员myun.c,myun.s和myun.i共用同一块内存(4个字节大小)。其中,myun.c只使用第一个字节,myun.s使用前两个字节而myun.i使用全部 4 个字节,三成员享有同一个起始地址。而结构体中每个成员均有自己的地址。 - 当我们给其中一个成员赋值时会影响到其他的成员。如
myun.i = 0x11223344,赋值后myun.c的值变成0x44,myun.s的值变成0x3344。
- 共用体变量
应用
- 当需要把不同类型的变量存放到同一段内存单元或对同一段内存单元的数据按不同类型处理则需要使用共用体数据结构。
- 例如:有若干个人员的数据,其中有学生和老师。学生的数据包括:姓名,编号,性别,职业,年级。老师的数据包括:姓名,编号,性别,职业,职务。
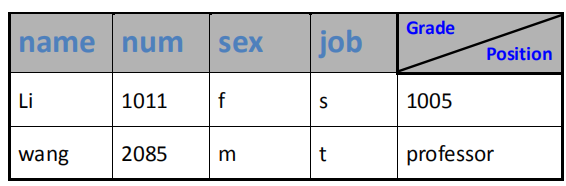
- union 在操作系统底层的代码中用的比较多,因为它在内存共享布局上方便且直观。所以网络编程,协议分析,内核代码上有一些用到 union,比较好懂,简化了设计。
枚举
- 枚举类型定义了一组整型常量的集合,目的是提高程序的可读性。它的语法跟结构体的语法相同。
枚举定义
- 枚举型是一个集合,集合中的元素(枚举成员)是一些命名的整型常量,元素之间用逗号(,)隔开。
- 第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1。
- 可以人为设定枚举成员的值,从而自定义某个范围内的整数。
- 枚举型是预处理指令#define 的替代。
enum DAY |
指针
- 他是天使,也是魔鬼。
内存
- 内存是以字节为单位进行编址的,内存中的每个字节都对应一个地址,通过地址才能找到每个字节。
变量的地址
- 变量对应内存中的一段存储空间,该段存储空间占用一定的字节数,用这段存储空间的第一个字节的地址表示变量的地址,即低位字节的地址。
- 变量的地址,可以通过
Reference (&)引用运算符取得,在此可以称为取地址运算符。 - 通过运算的方式,我们可以求得变量的地址。32 位机的情况下,无论是什么类型大小均是 4。而 64 位机大小均是 8。这是由当前机型的地址总线决定的。
间接访问内存
- 我们拿到的变量的地址,其实,就是指针了。除了变量,我们还可以通过指针的方式间接的访问内存。
dereference (*)解引用运算符,在此处我们可以称为,取内容运算符。
| 内容 | 指针 | 地址 | 取内容 | 取内容 |
|---|---|---|---|---|
char a |
&a |
0x0028FEBF |
*(&a) |
*((char*)0x0028FEBF) |
- 指针不是单纯的地址,而是有类型的地址。也就是说
&a进行取地址,取出来的地址是有类型的。 - 指针的类型,决定了该指针的寻址能力。即从指针所代表的地址处的寻址范围。
指针变量
- 定义:
type * variable;-
- 表示该变量是一个指针变量。
- type 表示该变量的内存放的地址的寻址能力。
-
- 初始化和简介访问
int main(void) |
- 如果直接赋给指针变量一个地址,对其访问是很危险的。因为,我们不知道此址处是否一块什么区域 ,有可能是一段内核区域 ,访问很可能会导致系统崩溃。
- 所以通常作法是,把一个己经开辟空间的变量的地址赋给指针变量。
null
野指针
- 一个指针变量,如果,指向一段无效的空间,则该指针称为野指针,是由
invalid pointer翻译过来,直译是无效指针。常见情型有两种,一种是未初化的指针,一种是指向一种己经被释放的空间。 - 对野指针的读或写崩溃尚可忍受,对野指针的写入成功,造成的后果是不可估量的。对野指针的读写操作,是危险而且是没有意义的。世上十之八九最难调的 bug皆跟它有关系。
int * p; |
NULL 指针(零值无类型指针)
- 如何避免野指针呢,NULL 是一个宏,俗称空指针,他等价于指针
(void*)0。(void*) 0是一个很特别的指针,因为他是一个计算机黑洞,既读不出东西,也不写进东西去。所以被赋值NULL的指针变量,进行读写操作,是不会有内存数据损坏的。 - c 标准中是这样定义的:
define NULL ((void *)0),故常用 NULL 来给临时不需要初初始化的指针变量来进行初始化。或对己经被释放指向内存空间的指针赋值。 - 可以理解为 C 专门拿出了
NULL(零值无类型指针),用于作标志位使用。
void 本质
- void 即无类型,可以赋给任意类型的指针,本质即代表内存的最小单位,在 32位机上地位等同于 char。
零所代表的意义
| 零值 | 意义 | 备注 |
|---|---|---|
| 0 | 整型数据的 0 | |
| 0.0 | 实型数据的 0 | |
| NULL | 指针型数据的 0 | 内存的 0 地址,用于初始化暂不用指针。或是标识己经被释放堆内存的指针。 |
| ‘\0’ | 转义字符型(ASCII 值为 0) | 非可打印字符,用于标识字符串结束标记。 |
| ‘0’ | 字符型(ASCII 值为 48) | 可打印字符,用于打印字符 0 |
| “0” | 字符串型 | 包含两个 ASCII 值 48 和 0 |
指针运算
赋值运算
- 区别初始化和赋值。不兼容类型赋值会发生类型丢失。为了避免隐式转化带来可能出现的错误,最好用强制转化显示的区别。
int data = 0x12345678; |
算术运算
- 指针的算术运算,不是简单的数值运算,而是一种数值加类型运算。将指针加上或者减去某个整数值(步长,以
n*sizeof(T)为单位进行操作的)。
| 运算符 | 示 例 |
|---|---|
+ |
p+5; |
- |
p-5; |
++ |
p++/++p; |
-- |
p--/--p; |
int *p = (int*)0x001; |
关系运算
- 比较的两个指针会判断指向的地址,不去校验指针类型。而c++不可以比较不同类型指针。
| 运算符 | 示 例 |
|---|---|
== |
p1==p2 |
> |
p2 > p2 |
< |
p1 < p2 |
数组和指针
一维数组
- 数组名是一个常量,不允许重新赋值
- 指针变量是一个变量,可以重新赋值
p+i和a+i均表示数组元素a[i]的地址,均指向a[i]*(p+i)和*(a+i)均表示p+i和a+i所指对象的内容a[i]*p++:等价于*(p++)。其作用:先得到*p,再使p=p+1(*p)++:表示将p所指向的变量(元素)的值加1。即等价于a[i]++- 指向数组元素的指针也可以表示成数组的形式,即允许指针变量带下标,如
*(p+i)可以表示成p[i]
- 数组名是数组的唯一标识符,数组名代表数组首元素的地址,并且携带了类型信息。
arr==&arr[0]其中int*隐含在数组名中。
int array[10] = {1,2,3,4,5,6,7,8,9,0}; |
- 数组除了可以用下标法和本质法访问以外,还可以用指针法访问。能用数组名解决的问题的,都可以用指针来解决,而能用指针来解决的问题,并一定能用数组名来解决。
//------访问方式一------- |
二维数组
- 数组元素的表示方法是:数组名称
[行][列],对于m行n列的二维数组,a[0][0]是数组的第一个元素,a[m-1][n-1]是最后一个元素。 - 二维数组名解引用,降维为一维数组名。
*(a+1) <==> a[1] - 对一维数组名引用,升级为二维数组名。
&a[1] <==> (a+1) &引用和*解引用互为逆向关系。- 二维数组名的本质是,数组指针。
a是数组首元素的地址,所以 a 的值和&a[0]的值相同,另一方面,a[0]本身是包含 4 个整数的数组,因此,a[0]的值同其首元素的地址&a[0][0]相同。简单的讲,a[0]是一个整数大小对象的地址,而a是 4 个整数大小对象的地址。因为整数和 4 个整数组成的数组开始于同一个地址,因此a和a[0]的值是相同的。a所指的对象大小是 4 个int,而a[0]所指的对象大小一个 int,因此,a+1和a[0]+1的结果是不同的。
指针数组
- 一个数组中的各个元素都是字符指针,我们称该数组为字符指针数组,或是指针数组。
- 本质是数组,同时数组中的成员,均是指针。 通常意义上的指针数组,指的是字符指针数组。
char a, b, c, d; |
字符串
引入
- C 语言提供了字符串,但是没有提供字符串类型。字符串常量,是双引号括起的任意字符序列。c语言将字符串处理为一个指向
data段的地址,包含了起始地址,步长,\0。
"Hello World"; //字符串常量 |

- 最后的字符
\0,我们称为字符串结束字符,是系统对双引号引起的字符串自动加设的,而非手动干预。
字符串与字符数组
- 字符数组跟字符串某些方面是完全等价的。要实现等价,字符数组的大小要比字符串的大小要大。
- 一个没有
\0结尾的字符串,不能称为一个合格的字符串。所以说,如果字符数组的大小比字符串的大小,要小。此时,字符串会被截断,拷贝到字符数组中去。此时字符串,和被拷贝到数组中的字符串之间不存在等价关系。
char *str = "1234"; //字符指针,用于指向字符串常量,但不能更改 |
字符串输入与输出
- 输出
- printf:遇到字符串结束标记则会停止打印输出.
printf("%s\n","abcdefg");//常见第二个参数:char* /字符数组名/常量字符串 - puts:
int puts(const char *_Str);//向屏幕输出,成功返回>0,失败返-1,特点,自动追加换行。
- printf:遇到字符串结束标记则会停止打印输出.
- 输入
- scanf:scanf 遇到空格会截止输入。但是要记得,不要输入的字符长度超过给定的空间大小。在不越界的情况下,scanf 会自动在字符串后面追加
\0。scanf("%s",name); //测试空格和越界 "%[^\n]s" ->fgets() - gets:gets 直到遇到回车,才停止输入,空格也作为字符输入,但是要记得,不要输入的字符长度超过给定的空间大小。在不越界的情况下,gets 会自动在字符串后面追加
\0。也存在越界风险。gets(name); // 测试空格和越界 - fgets:
fgets(arr,10,stdin);
- scanf:scanf 遇到空格会截止输入。但是要记得,不要输入的字符长度超过给定的空间大小。在不越界的情况下,scanf 会自动在字符串后面追加
字符串操作函数
| 函数 | 所在文件 | 说明 |
|---|---|---|
size_t strlen ( const char * str ); |
string.h | 获取长度 |
char * strcat ( char * dest, const char * src ); |
string.h | 追加 src 串到 dest 的末尾,dest 的末尾的’\0’字符,会被 src 的第一个字符所覆盖,追加完成后的新串会被在其末尾自动追加’\0’。 |
char * strcpy ( char * dest, const char * src ); |
string.h | 拷贝 src 所指向的字符串,到 dest 所指向空间中去,拷贝到 dest的内容包含 src 中的结束符’\0’。 |
int strcmp ( const char * str1, const char * str2 ); |
string.h | 比较字符串 str1 和字符串 str2 的大小。该函数从两字符串的第一个字符开始,如果相等,依次往下比较,直到遇到不相同的字符或其中一个遇到’\0’s。比较的依据,是两字符对应的 ASCII 值的大小。 |
数据类型转化
隐式转化
- 不需要人为参与而产生的默认转称为隐式转化。
- 隐式转化规则:从小到大转
char short->int->long->longlong->float->double
算术转化
- 整形提升:char short int 等类型在一起运算时,首先提升到 int,这种现象叫作整型提升。整型提升的原更换是符号扩充。
- 混合提升:在进行运算时,以表达式中最长类型为主,将其他类型位据均转换成该类型,如:
- 若运算中最大范围为 double,则转化为 double。(10308)
- 若运算中最大范围为 float 则转化为 float。(1038)
- 若运算中最大范围为 long long 则转化为 long long。(264)
- 若运算中最大范围为 int 则转化为 int。(232)
- 若运算中有 char short 则一并转化为 int。(28 / 216 / 232)
赋值转化
- 整型和实型之间是可以相互赋值的。赋值的原则是,一个是加零,一个是去小数位。
强制转化
- 隐式类型转化,是有缺陷的,当隐式类型转化不能满足我们的需求时,就需要强制类型转化。
- 格式:
(类型)待转表达式
运算符/表达式/位操作
- 要通过运算符就可以对常量与变量进行运算。
- 表达式是由操作数和运算符构成,操作数本身也可以是一个表达式。表达式再在其后加一个分号,即构成 C 语言语句。
运符符
c/c++语全部运算符
| Precedence | Operator | Description | Associativity |
|---|---|---|---|
| 1 | ++ – | Suffix/postfix increment and decrement | Left-to-right |
| () | Function call and subexpression | ||
[] |
Array subscripting | ||
. |
Structure and union member access | ||
-> |
Structure and union member access through pointer | ||
| 2 | ++ -- |
Prefix increment and decrement | Right-to-left |
+ - |
Unary plus and minus | ||
! ~ |
Logical NOT and bitwise NOT | ||
(type) |
Type cast | ||
* |
Indirection (dereference) | ||
& |
Address-of | ||
sizeof |
Size-of | ||
| 3 | * / % |
Multiplication, division, and remainder | Left-to-right |
| 4 | + - |
Addition and subtraction | |
| 5 | << >> |
Bitwise left shift and right shift | |
| 6 | < <= |
For relational operators < and ≤ respectively | |
> >= |
For relational operators > and ≥ respectively | ||
| 7 | == != |
For relational = and ≠ respectively | |
| 8 | & |
Bitwise AND | |
| 9 | ^| |
Bitwise XOR (exclusive or) | |
| 10 | | |
Bitwise OR (inclusive or) | |
| 11 | && |
Logical AND | |
| 12 | || |
Logical OR | |
| 13 | ?: |
Ternary conditional | Right-to-Left |
| 14 | = |
Simple assignment | |
+= -= |
Assignment by sum and difference | ||
*= /= %= |
Assignment by product, quotient, and remainder | ||
<<= >>= |
Assignment by bitwise left shift and right shift | ||
&= ^= |= |
Assignment by bitwise AND, XOR, and OR | ||
| 15 | , |
Comma | Left-to-right |
运符符分类
- 计算机中还按操作的数的个数将其分为 3 类,单目运算符,双目运算符和三目运算符。
a = 4 + 6; // 加号即为双目运算符。 |
表达式
- 任何表达式是有返回值的:
a=b=5,这里b=5的返回值赋值给了a。 - 使用常见运符算符就可以构成表达式。
位操作
- 位操作不同于逻辑操作,逻辑操作是一种整体的操作,而位操作是针对内部数据位补码的操作。逻辑操作的世界里,只有真与假(零和非零),而位操作的世界里按位论真假(1 和 0)。运算符也不同,如下。
| 位运算符 | 逻辑运算符 | 说明 |
|---|---|---|
| & | && | |
| |
|| |
|
~ |
! |
|
^| |
||
<< >> |
位数为非负整数,且默认对 32 求余 对无符号数和有符号中的正数补 0;有符号数中的负数,取决于所使用的系统:补0的称为“逻辑右移”,补1的称为“算术右移”。 |
|
&= |= ^= >>= <<= |
程序流程
选择
if
if后面的大括号可以省略,但是只有if后的第一行隶属于if,其他即使缩进一样也不会在判断的语句中。else也是如此,而且必须和if共同使用。
if(表达式) |
switch
- switch(表达式),中的表达式,必须为整型和字符型。
- case 只能为常量表达式。
- case 分支是互斥的。
- case 分支要同 break 连用,跳出 switch,不然匹配一次后,不再匹配。
- 两 case 块之间,可以用不大括号。
switch(表达式) |
循环
- 循环三要素:
- 循环变量初始化
- 循环变量的变化(趋向终止条件)
- 循环终止条件
while
int i=10; //循环变量初始化 |
do while
- 先执行循环体中的语句,然后再判断条件是否为真,如果为真则继续循环;如果为假,则终止循环。
do |
for
- 计算表达式 1 的值,通常为循环变量赋初值。
- 计算表达式 2 的值,即判断循环条件是否为真,若值为真则执行循环体一次,否则跳出循环。
- 计算表达式 3 的值,这里通常写更新循环变量的赋值表达式,然后转回第 2步重复执行。
for( 表达式 1 ; 表达式 2 ; 表达式 3 ) |
跳转
break
- 提前结束当前循环,break 只能跳出一重循环
continue
- 结束当前本轮循环,进入下一轮循环。
goto
- goto 会破坏结构化程序设计流程,它将使程序层次不清,且不易读,所以慎用。
- goto 语句,仅能在本函数内实现跳转,不能实现跨函数跳转(短跳转)。但是他在跳出多重循环的时候效率还是蛮高的,再者就是集中错误处理。
return
- 结束当前函数,返回调用。
函数
- 函数提高了代码的重用性,c中除了标准库的函数可以用外,我们还可以自定义函数。
c标准库
- 由C语言系统提供;用户无须定义,也不必在程序中作类型说明;只需在程序前包含有该函数定义的头文件(/usr/include/stdio.h),而不无关系库在哪里(/usr/lib/libc.so);标准库到底提供了哪些函数可以通过查表的方式获得。
随机函数
- 使用随机函数产生,某一范围内了随机数。比如生成[1,100]以内的随机数。srand和 rand()配合使用产生伪随机数序列。rand 函数在产生随机数前,需要系统提供的生成伪随机数序列的种子,rand 根据这个种子的值产生一系列随机数。如果系统提供的种子没有变化,每次调用 rand 函数生成的伪随机数序列都是一样的。
| 函数 | 所在文件 | 说明 |
|---|---|---|
int rand (void); |
stdlib.h |
产生一组[0,RAND_MAX]伪随机数 |
void srand (unsigned int seed); |
stdlib.h |
设置随机种子seed |
- 随机种子一般设置
srand(time(NULL));,但是在同一秒得出的随机数可能仍然是相同的。
时间函数
| 函数 | 所在文件 | 说明 |
|---|---|---|
struct tm * localtime (const time_t * timer); |
stdlib.h |
获取时间函数,转换时间戳为time结构体 |
- 返回值详细解析:
| variable | Meaning | Range |
|---|---|---|
| int tm_sec | seconds after the minute | 0-61* |
| int tm_min | minutes after the hour | 0-59 |
| int tm_hour | hours since midnight | 0-23 |
| int tm_mday | day of the month | 1-31 |
| int tm_mon | months since January | 0-11 |
| int tm_year | years since 1900 | |
| int tm_wday | days since Sunday | 0-6 |
| int tm_yday | days since January 1 | 0-365 |
| int tm_isdst | Daylight Saving Time flag |
数学函数
| 函数 | 所在文件 | 说明 |
|---|---|---|
double sqrt(double x) |
math.h | 计算 x 的平方根(squareroot) |
double pow(double x, double y) |
math.h | 计算 x 的 y 次幂(power) |
double ceil(double x) |
math.h | 求不小于 x 的最小整数,并以 double 形式显示 |
double floor(double x) |
math.h | 求不大于 x 的最大整数,并以 double 形式显示 |
double sin(double x) |
math.h | 正弦曲线 |
工具函数
| 函数 | 所在文件 | 说明 |
|---|---|---|
| int toupper(int x) | ctype.h | 如果 x 为小写字母,则返回对应的大写字母 |
| int tolower(int x) | ctype.h | 如果 x 为大写字母,则返回对应的小写字母 |
自定义函数
定义自定义函数
- 语法格式:
返回值 函数名(参数){函数体} - 定义和声明
- 定义在前,声明在后
- 定义在后,声明在前,此时需要前向声明
参数
形参和实参
- 形参:在定义或声明函数中指定的形参,在未出现函数调用时,它们并不占内存中的存储单元。只有在发生函数调用时,形参才被分配内存单元。在调用结束后,形参所占的内存单元也被释放。在声明时形参名可以省略。
- 实参:实参可以是常量、变量或表达式,但要求它们有确定的值。在调用时将实参的值赋给形参。
- 当入参中没有参数,可以使用
void表示无入参:int myMax(void);,通常可以省略。 - 没有返回值,返回值是
void,此时不可以省略,否则编译器会默认返回int。
传值与传址
- 函数被调用之前,函数内所有变量尚未开辟空间,函数调用时才开辟,函数结束空间释放。
- 传值:声明:
void func(int a);,调用:func(a); - 传址:声明:
void func(int* a);,调用:func(&a);
- 传值:声明:
- 传递一维数组
- 数组的传递不可能通过拷贝的方式,基于效率的原因,传递时数组名仅充当于地址使用。
void disArray(int arr[]); //本质传递的是指针 |
- 传递二维数组
//方式一 |
函数调用
- 所有函数都是平行的,即在定义函数时是分别进行的,是互相独立的。函数间可以互相调用。常见有,平行调用,嵌套调用。
- 其他函数可以调用main函数,或者递归不退出,这都会引起栈溢出。
预处理
宏(Macro)
宏常量
- #define 定义的宏,只能在一行内表达(换行符表示结束而非空格),如果想多行表达,则需要加续行符。
|
宏类型
- 宏可以给类型起别名,因其缺点,常被 typedef 取代
宏函数
- 我们常将短小精悍的函数进行宏化,这样可以嵌入到代码中,减少调用的开销。但是代价就是,编译出的文件可能会变大。
- define 是个演技高超的替身演员。 要搞定它其实很简单,别吝啬括号就行了。防止替换后使得结果错误
- 尽量少用宏函数,能看的懂别人写的宏函数即可。C++中的 inline 函数己经取代了宏函数作用。
取消宏
条件编译(Condition Compile)
- 依据条件,判断哪些程序段参与编译
单、双、多路(#if /#ifdef / #ifndef #elif #else #endif)
|
编译期指定宏 gcc -D
- -D name, Predefine name as a macro, with definition 1.
|
其他宏运算符
运算符——利用宏创建字符串
- 将替换符 字符串化,解决字符串中,不可被替换的参数问题。字符串如下的书写也是合理的。
char buf[] = "china ""is ""great"; |
//#define str(x) "aaaaaaaaxaaaaaaaaa" |
- 引号中的字符串中的 x 被看作普通的文本,而不是被看作一个可被替换的语言符号。#号用作一个预处理运算符,它可以把待替换符转化为字符串
运算符——预处理的粘和剂
- 解决了,参数变量与宏展开,无法一一对应的问题。
//#define sum(a,b) (aa+bb) |
预定义宏
| 宏名 | 说明 |
|---|---|
| DATE | 进行预处理的日期(“MMmm dd yyyy”形式的字符串文字) |
| FILE | 代表当前源代码文件名的字符串文字 |
| LINE | 代表当前源代码中的行号的整数常量 |
| TIME | 源文件编译时间,格式“hh:mm:ss” |
| func | 当前所在函数名 |
- 在打印调试信息时打印这两个宏
__FILE__,__LINE__可以给开发者非常有用的提示。
printf( "The file is%s.\n",__FILE__); // _ _ |
多文件编程
- 多文件编程可以至少有两大好处,一是,方便管理,协同开发。二是,便于分享与加密(作成函数库)。
- c 语言是以文件为单位进行编译的,编译期只需要函数声明即可。链接阶段提供实现就可以完成生成可执行文件。
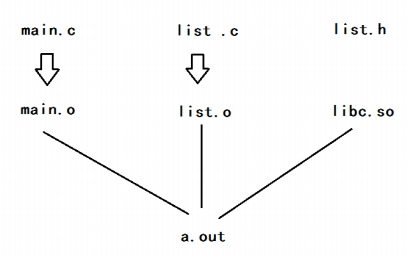
//-std=c99编译不连接,仅生成main.o、mystr.o |
函数声明(.h)
- .c 文件中存在相互调用的关系,自包含可以免去了多余的前向声明。
- 避免头文件的额重复包含的代码
|
函数实现(.c)
头文件包含#include
- 全写入,被包含的文件中。包含是支持嵌套的。
- 包含的方式
#include<stdio.h>,从系统指定路径中搜索包含头文件,linux 中的系统路径为/usr/include#include“myString.h”,从工程当前路径中搜索包含头文件,如果当前工程路径下没有的话,则到系统路径下搜索包含。
文件操作
- Unix 的设计哲学之一,就是 Everything is a file。
文件流
文件流概念
- C 语言把文件看作是一个字符的序列,即文件是由一个一个字符组成的字符流,因 此 c 语言将文件也称之为文件流。即,当读写一个文件时,可以不必关心文件的格式或结构。
文件类型
-
大家都知道计算机的存储,物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异。简单来说,文本文件是基于字符编码的文件,常见的编码有 ASCII 编码,二进制文件是基于值编码的文件。
- 文本文件:以 ASCII 码格式存放,一个字节存放一个字符。 文本文件的每一个字节存放一个 ASCII 码,代表一个字符。这便于对字符的逐个处理,但占用存储空间较多,而且要花费时间转换。
- 二进制文件:以值(补码)编码格式存放。二进制文件是把数据以二进制数的格式存放在文件中的,其占用存储空间较少。数据按其内存中的存储形式原样存放。
-
文本工具打开文件的过程:拿记事本来说,它首先读取文件物理上所对应的二进制比特流,然后按照你所选择的解码方式来解释这个流,然后将解释结果显示出来。一般来说,你选取的解码方式会是 ASCII 码形式(ASCII 码的一个字符是 8 个比特),接下来,每 8 个比特 8 个比特地来解释这个文件流。
-
二进制与文本转化查看工具
| windows | linux |
|---|---|
| UltraEdit | hexdump -c -C -x -o |
文件缓冲
- 有缓冲区(buffer)的原因:
- 从内存中读取数据比从文件中读取数据要快得多。
- 对文件的读写需要用到 open、read、write 等系统底层函数,而用户进程每调用一次系统函数都要从用户态切换到内核态,等执行完毕后再返回用户态,这种切换要花费一定时间成本(对于高并发程序而言,这种状态的切换会影响到程序性能)
文件的打开和关闭
FILE 结构体
- FILE 结构体是对缓冲区和文件读写状态的记录者,所有对文件的操作,都是通过FILE 结构体完成的。
typedef struct { |
- 在开始执行程序的时候,将自动打开 3 个文件和相关的流:标准输入流(stdin)、标准输出流(stdout)和标准错误(stderr),它们都是
FIEL*型的指针。流提供了文件和程序的通信通道。
| 函数 | 所在文件 | 功能 |
|---|---|---|
FILE * fopen ( const char * filename, const char * mode ); |
stdio.h | 以 mode 的方式,打开一个 filename 命名的文件,返回一个指向该文件缓冲的 FILE 结构体指针。 |
int fclose ( FILE * stream ); |
stdio.h | fclose()用来关闭先前 fopen()打开的文件. 此动作会让缓冲区内的数据写入文件中, 并释放系统所提供的文件资源。主动刷缓存,防止意外退出,系统未正确退出来不及刷新。 |
int fputc (int ch, FILE * stream ); |
stdio.h | 将 ch 字符,写入文件。写入失败返回EOF |
int fgetc ( FILE * stream ); |
stdio.h | 从文件流中读取一个字符并返回。 |
int feof( FILE * stream ); |
stdio.h | 判断文件是否读到文件结尾 |
int fputs(char *str,FILE *fp) |
stdio.h | 把 str 指向的字符串写入 fp 指向的文件中。 |
char *fgets(char *str,int length,FILE *fp) |
stdio.h | 从 fp 所指向的文件中,至多读 length-1 个字符,送入字符数组 str中, 如果在读入 length-1 个字符结束前遇\n 或 EOF,读入即结束,字符串读入后在最后加一个‘\0’字符。 fgets 函数返回有三个条件: 1-读 n-1 个字符前遇到\n,读取结束(\n 被读取) + \0。 2-读 n-1 个字符前遇到 EOF,读取结束 +\0。 3-读到 n-1 个符+\0。 |
int fwrite(void *buffer, int num_bytes, int count, FILE *fp) |
stdio.h | 把 buffer 指向的数据写入fp 指向的文件中 |
int fread(void *buffer, int num_bytes, int count, FILE *fp) |
stdio.h | 把 fp 指向的文件中的数据读到 buffer 中。 |
rewind() |
stdio.h | 文件指针回退文件开头 |
long ftell ( FILE * stream ); |
stdio.h | 得到流式文件的当前读写位置,其返回值是当前读写位置偏离文件头部的字节数. |
int fseek ( FILE * stream, long offset, int where); |
stdio.h | 偏移文件指针。 常见的起始位置有宏定义: #define SEEK_CUR 1 当前位置 #define SEEK_END 2 文件结尾 #define SEEK_SET 0 文件开头 |
| `` | stdio.h | |
| `` | stdio.h |
| mode值 | 处理方式 | 文件不存在时 | 文件存在时 | 向文件输入 | 向文件输出 |
|---|---|---|---|---|---|
| r | 读 取 | 出错 | 打开文件 | 不能 | 可以 |
| w | 写 入 | 新建 | 覆盖源文件 | 可以 | 不能 |
| a | 追 加 | 新建 | 源文件新加 | 可以 | 不能 |
| r+ | 读/写 | 出错 | 打开文件 | 可以 | 可以 |
| w+ | 写/读 | 新建 | 覆盖源文件 | 可以 | 可以 |
| a+ | 读/追 | 新建 | 源文件新加 | 可以 | 可以 |
- 如果读写的是二进制文件,则还要加b,比如rb, r+b等。unix/linux不区分文本和二进制文件。
|
- fread、fwrite可以按照二进制的方式,读取或者写入数据,而不会被EOF、0等符号影响。
|
- feof 这个函数,是去读标志位判断文件是否结束的。即在读到文件结尾的时候再去读一次,标志位才会置位,此时再来作判断文件处理结束状态,文件到结尾。如果用于打印,则会出现多打一次的的现象。
- EOF的值为-1。