
深度学习
简介
介绍
| 名称 | 说明 | 应用 |
|---|---|---|
| ANN | 人工神经网络 | 计算机神经科学 |
| CNN | 卷积神经网络 | 图像处理 |
| RNN | 递归神经网络 | 语音识别 |
| DNN | 深度神经网络 | 声学模型 |
| DBN | 深度信念网络 | 新药研发 |
卷积神经网络CNN
- 卷积神经网络CNN (Convolutional neural network),用于图像识别,分割
- 思想:局部连接、全局贡献
input -> (convolution+relu -> pooling)*n -> flatten -> full connect -> softmax -> output
卷积运算
- 连续形式:
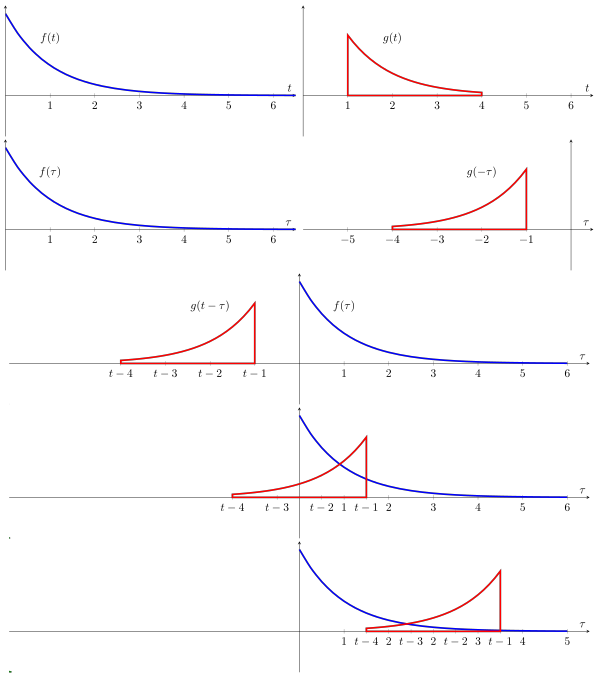
- 离散形式:
- 卷积和互相关运算非常相似,区别就是卷积进行了反转,实际中就用互相关就可以。
概念
- 感受野:卷积窗口的大小是CNN感受野(receptive field)的一个度量
- 输出特征矩阵size:
- O: the output height/length,
- 𝑊: the input height/length
- 𝐾: the filter size
- 𝑃: the padding 填充
- 𝑆: the stride 步幅
卷积核参数共享
- 卷积核在扫原图时,参数是共享的,所以对于两个平移图像是都能感知的。所以具有平移不变性。
im2col
- 以上我们已经知道了卷积是如何操作的,im2col的作用就是优化卷积运算
col2im
池化层
- 分为:平均池化,最大池化
- 没有要学习的参数,对微小偏差具有鲁棒性
CNN网络模型
图像分类
数据集
| 数据集 | 说明 |
|---|---|
| MNIST | 手写体识别0-9,28*28灰度图,训练样本数60000,测试样本数10000 |
| CIFAR | 10个类别,32*32彩色图像,训练样本数50000,测试样本数10000 |
| Fashion-MNIST | 德国Zalando公司提供的 |
衣物图像数据集,28*28灰度图,训练样本数60000,测试样本数10000
PASCAL VOC|PASCAL VOC竞赛提供的数据集,包含了20类的物体,主要任务是分类,检测,分割,人体布局,人体动作识别
ImageNet|计算机视觉数据集,包含14,197,122个张图片, 21,841个Synset索引。它一直是评估图像分类算法性能的基准。
WebVision|主要有Google和Flickr两个数据源,主要是利用ImageNet 1000个类的文本信息从网站上爬数据,所以它的数据类别与ImageNet完全一样,为1000类别,由240万幅图片构成训练数据。比ImageNet的两倍还多,分别由5万张图片构成验证集和测试集(均带有人工标注)
LeNet-5
- LeNet-5模型是Yann LeCun教授于1998年在论文Gradient-based learning applied to document recognition中提出。它是第一个成功应用于手写数字识别问题并产生实际商业价值的卷积神经网络

- 2个卷积层 (C1, C3), 2个下采样(池化) 层 (S2 and S4), 2个全连接层 (C5,F6), 随后是输出层
AlexNet
- AlexNet,2012Alex和Hinton在LeNet基础上进行了更宽更深的网络设计。
- 在ILSVRC2012图像分类竞赛第一名,标志着深度学习革命的开始。
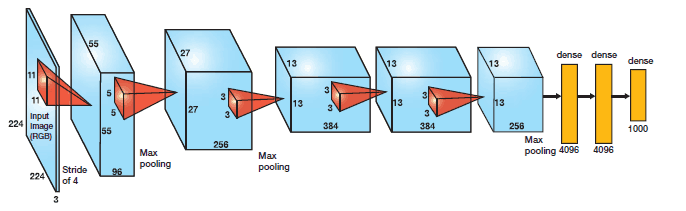
网络架构

- AlextNet网络采用卷积神经网络架构: 5个卷积层和3个全连接层,输出层为Softmax层(识别1000类别)
| id | 层 | 输入 | 结构 | 输出 | 参数个数 | 算力 |
|---|---|---|---|---|---|---|
| 1 | conv1 | 输入图像224*224*3 |
filter:96个11*11 ,stride=4,(224-11)/4+1=54.2,所以pad=3 |
55*55*96 |
(11*11*3+1)*96=35K |
55*55*96*(11*11*3+1)=105M |
| 2 | pool1 | 55*55*96 |
maxpool:3*3,stride=2,(55-3)/2+1=27 |
27*27*96 |
0 | 0 |
| 3 | conv2 | 27*27*96 |
256个5*5kernals,pad=2,(27-5+2*2)/1+1=27 |
27*27*256 |
(5*5*96+1)*256=307k |
233M |
| 4 | pool2 | 27*27*256 |
maxpool:3*3,stride=2,(27-3)/2+1=13 |
13*13*256 |
0 | 0 |
| 5 | conv3 | 13*13*256 |
filter:384个3*3,pad=1,(13-3+1*2)/1+1=13 |
13*13*384 |
(3*3*256+1)*384=884k |
149M |
| 6 | conv4 | 13*13*384 |
filter:384个3*3,pad=1,(13-3+1*2)/1+1=13 |
13*13*384 |
(3*3*384+1)*384=1.3M |
112M |
| 7 | conv5 | 13*13*384 |
filter:256个3*3,pad=1,(13-3+1*2)/1+1=13 |
13*13*256 |
(3*3*384+1)*256=442K |
74M |
| 8 | pool5 | 13*13*256 |
maxpool:3*3,stride=2,(13-3)/2+1=6 |
6*6*256 |
0 | 0 |
| 9 | fullconnect1 | 6*6*256=9216 |
layer:4096 | 4096 |
(9216+1)*4096=37M |
37M |
| 10 | fullconnect2 | 4096 |
layer:4096 | 4096 |
(4096+1)*4096=16M |
16M |
| 11 | fullconnect3 | 4096 |
layer:1000 | 1000 |
(4096+1)*1000=4M |
4M |
| 12 | softmax | 1000 |
网络改进
- 首次引入了ReLU作为CNN 的激活函数,并验证其效果在较深的网络超过了Sigmoid,解决了Sigmoid在网络较深时的梯度弥散问题,提高了网络的训练速率。
- 首次引入了Dropout随机忽略部分神经元,避免过拟合。随机系数0.5,也就是随机忽略一半的神经元。只在前两个全连接层使用。
- 利用数据增强减低过拟合。利用随机裁剪和翻转镜像操作增加训练数据量。
- 图像平移与水平反射(镜像):测试时,网络剪裁5个224×224图块(4个角图块和1个中心图块)以及它们的水平反射(总共10个)进行预测,并对网络的softmax层的预测求10个图块平均值。如果没有该方案, AlexNet网络会遭受严重的过拟合,这将迫使使用更小的网络
- 改变训练集RGB通道的图像像素强度(intensity):对每一RGB像素,加上,其中pi,λ是像素RGB的
3*3协方差矩阵的特征向量和特征值。α均值为0,标准差0.1的随机变量。该方法即增加了目标对光照强度和颜色变化的鲁棒性,把top-1错误率减少了1%.
- 使用重叠最大池化(Overlapping max pooling)。最大池化可以避免平均池化的模糊化效果,而采用重叠技巧可提升特征的丰富性。每次移动的步幅小于池化的边长。
- 提出了局部响应归一化(Local Response Normalization,LRN) 层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 双GPU并行计算,在第三个卷积层Conv3和全连接层做信息交互。利用GPU的并行计算能力加速网络训练过程,并采用GPU分块训练的方式解决显存对网络规模的限制
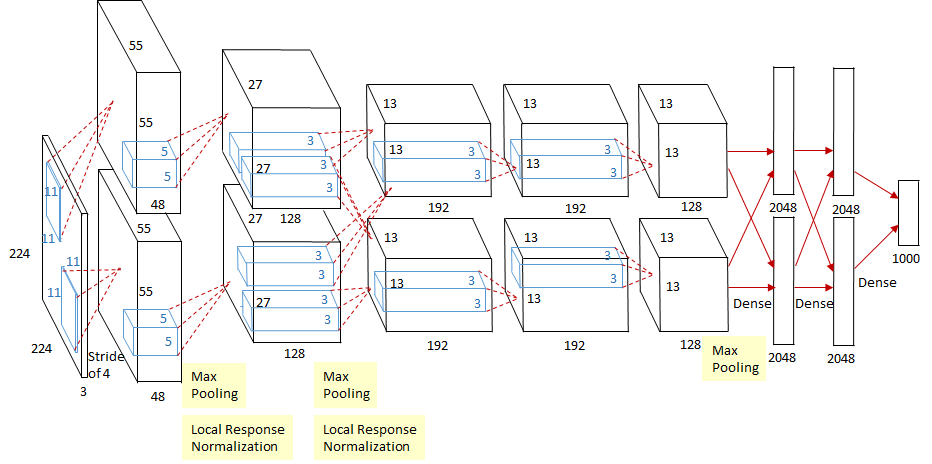
LRN
- 模拟在神经生物学中有一个概念叫做“ 侧抑制(Lateral inhibition)”。其含义是被激活的神经元会对相邻的神经元产生抑制作用。对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
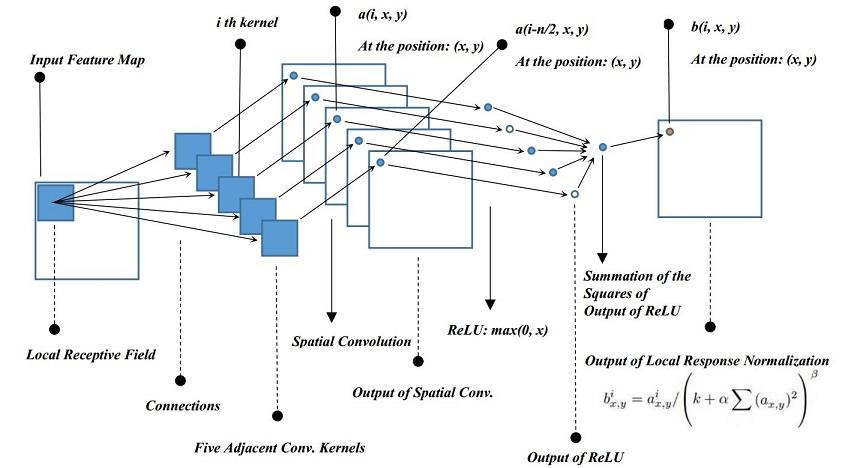
-
算法功能是在池化之后,对通道间的数据进行了距离相关函数的归一化。
-
- :第i个卷积核在位置(𝑥, 𝑦)运用ReLU后的特征图上的输出
- : LRN的输出,也是下一层的输入
- :同一位置上邻近深度卷积核的数目(沿通道方向); 自己决定; AlexNet选择5
- :卷积核的总数目
- :都是超参。 AlexNet选择 k = 2, α = 10e-4, β = 0.75
-
改变超参数可以实现其它归一化操作,如当k = 0, n=N, α = 1, β = 0.5便是经典的𝑙2归一化
-
2015年VGGNet论文Very Deep Convolutional Networks for Large-Scale Image Recognition提到LRN对VGGNet作用不大
损失函数
- Softmax回归:是逻辑回归对处理多个类别的情况的推广。优化目标,相当于在预测分布下最大化训练样本中正确标签的对数概率的平均值
- 采用独热One-hot标签编码时,目标误差函数等同于交叉熵损失
网络训练
- 改进随机梯度下降
动量=权重衰减-学习率*梯度下降- 学习率随梯度变化变缓而减小
VGGNet
- VGGNet2015,K. Simonyan and A. Zisserman提出,是2014 年ILSVRC竞赛分类任务的第二名(第一名是GoogLeNet)和定位任务的第一名。
- 泛化能力强,适合迁移学习
网络改进
- 对卷积核和池化大小进行了统一: 3×3卷积和2×2最大池化操作
- 采用卷积层堆叠的策略,将多个连续的卷积层构成卷积层组
- 采用小的卷积滤波器,网络更深(16/19层)
- 不采用LRN(Local Response Normalization)
网络结构
- VGG-16有16个卷积层或全连接层,包括五组卷积层和3个全连接层,即: 16=2+2+3+3+3+3。

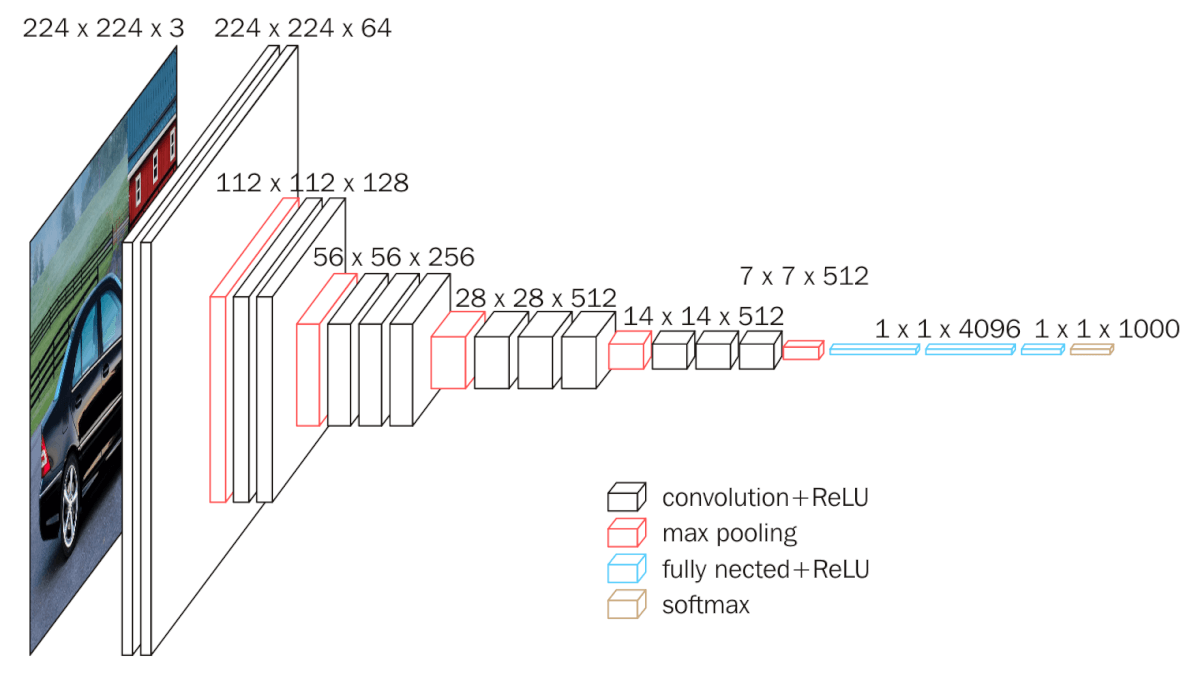
- 网络包含5组卷积操作,每组内的卷积层具有相同的结构,每组包含1~3个连续的卷积层,每两个卷积层之间为ReLU层。
- VGG的卷积层,特征图的空间分辨率单调递减,特征图的通道数单调递增。使得输入图像在维度上流畅地转换到分类向量。AlexNet的通道数无此规律,VGGNet后续的GoogLeNet和ResNet均遵循此维度变化的规律。
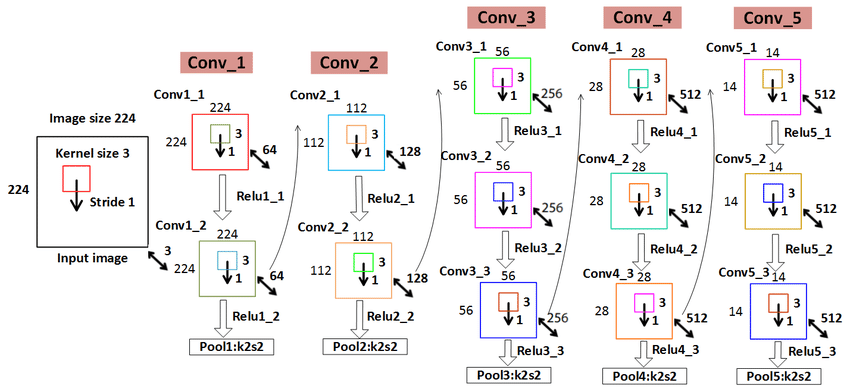
卷积堆叠
- 与单个卷积层相比,卷积堆叠可以增加感受野,增强网络的学习能力和特征表达能力
- 与具有较大核的卷积层相比,采用多个具有小卷积核的卷积层串联的方式能够减少网络参数
- 在每层卷积之后进行ReLU非线性操作可提升网络的特征学习能力

训练
-
训练是通过使用带有动量的小批次梯度下降的反向传播来优化多类别逻辑回归目标
-
批次大小设置为256,动量为0.9。 通过权重衰减正则化(L2惩罚因子设置为5 × 10−4)和前两个全连接层的丢弃(丢弃率设置为0.5)对训练进行正则化。
-
学习率初始设定为10−2, 然后当验证集准确率度停止改善时,学习率降低10倍
-
单尺度训练:训练图像大小裁剪为固定大小
224*224(s=224)或384*384(s=384) -
多尺度训练:尺度抖动,训练图像大小随机在
s∈[256,512]的范围中 -
训练时,将不同尺寸的s,随机裁剪为
224*224的训练样本 -
测试时,将图像缩放到固定尺寸Q=s或0.5(256+512),对网络最后的卷积层使用滑动窗口进行分类预测,对不同的窗口分类结果取平均。
多剪裁
- Multi-Crop evaluation: 从测试图像中剪切出一大批
224*224的小块图像,在输出时取平均得到一个1000维的平均结果。
密集评估
- Dense evaluation: 测试图像的尺寸不作任何变化,将最后一个卷积层和全连接层看成为一个卷积操作,然后对所作的结果进行平均。 全卷积网络因为没有全连接的限制,因而可以接收任意宽或高的输入
- 首先将全连接的层转换为卷积层(第一个FC层转换到7×7卷积层,最后两个FC层转换到1×1转换层)。 然后将得到的全卷积网络应用于整个(未剪切的)图像。
- 比如,对于训练图像其大小为
224*224,经过最后一个卷积得到7×7×m的特征图,然后输出为1000个结点。这是训练好的网络。 - 对于一个
448*448的测试图像,经过训练好的网络的映射,最后会输出2*2*1000大小的结果,将2*2里面的内容进行平均,即得到1000维向量
NiN
- NiN,2014,新加坡国立大学颜水成教授提出的,其中思想后续被普遍应用。他的思路是,用微小的神经网络代替卷积核,达到提升效率的目的。
Mlpconv
- 在网络中构建微型网络Mlpconv,它对conv特征进行了组合,提高了卷积的有效性
- 对单个像素, 1x1卷积等效于该像素点在所有特征上进行一次全连接计算
- Mlpconv中的全连接可以通过1×1卷积快速实现
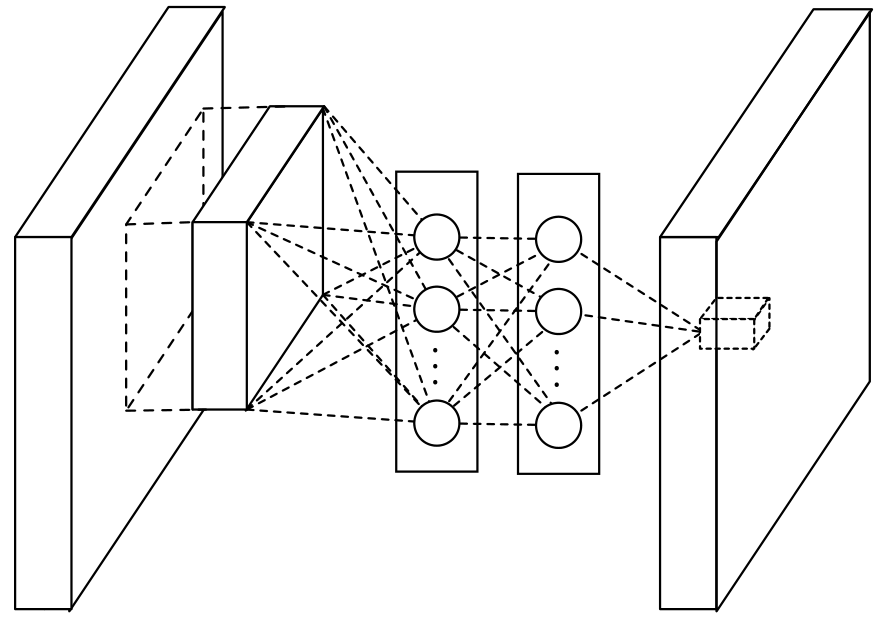
Mlpconv的作用
- 通过叠加更多的卷积结果,经过ReLU激励,能在相同的感受野范围中提取更强的非线性特征。即上层特征可以更复杂的映射到下层。
- 使用1×1卷积进行降维,降低了计算复杂度,并且保持图像大小
计算策略
- 传统卷积+relu可表达为:,ij为图块中心店的位置,k为特征图通道索引
- Mlpconv:,l为通道索引,
Mlpconv = convolution + 1×1 convolution +…+ 1×1 convolution
全局平局池化
- 用全局平均值池化代替全连接层,减小了参数数量,降低了网络复杂度和过拟合
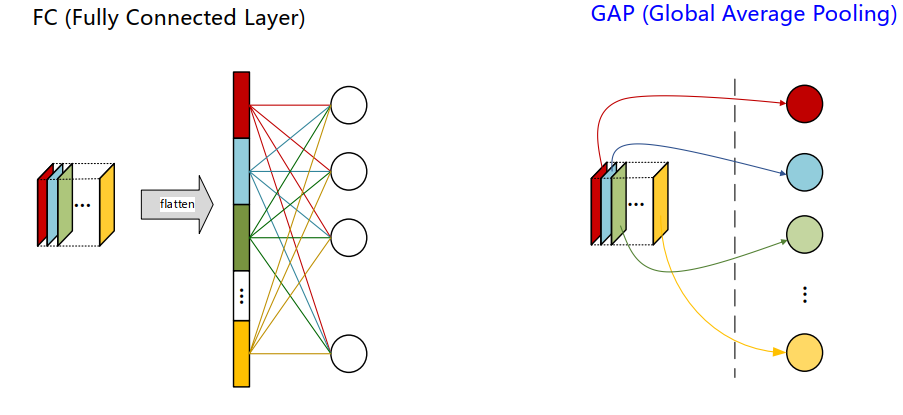
- 改变原先展平操作,而直接求平均
网络结构
- 在论文中, NIN网络模型堆叠了三个mlpconv层和一个全局平均池化层
GoogLeNet
- GoogLeNet,2015,由google开发人员开发,在ILSVRC2014竞赛图像分类任务第一名。
改进
- 深的网络:22层(包括池化层共27层)
- 引入了高效的 “Inception” 模块:设计良好的局部网络拓扑,然后将这些模块堆叠在一起。
- 无全连接层,使用平均池化代替,没有参数,不会过拟合。
- 参数数量仅为AlexNet的1/12
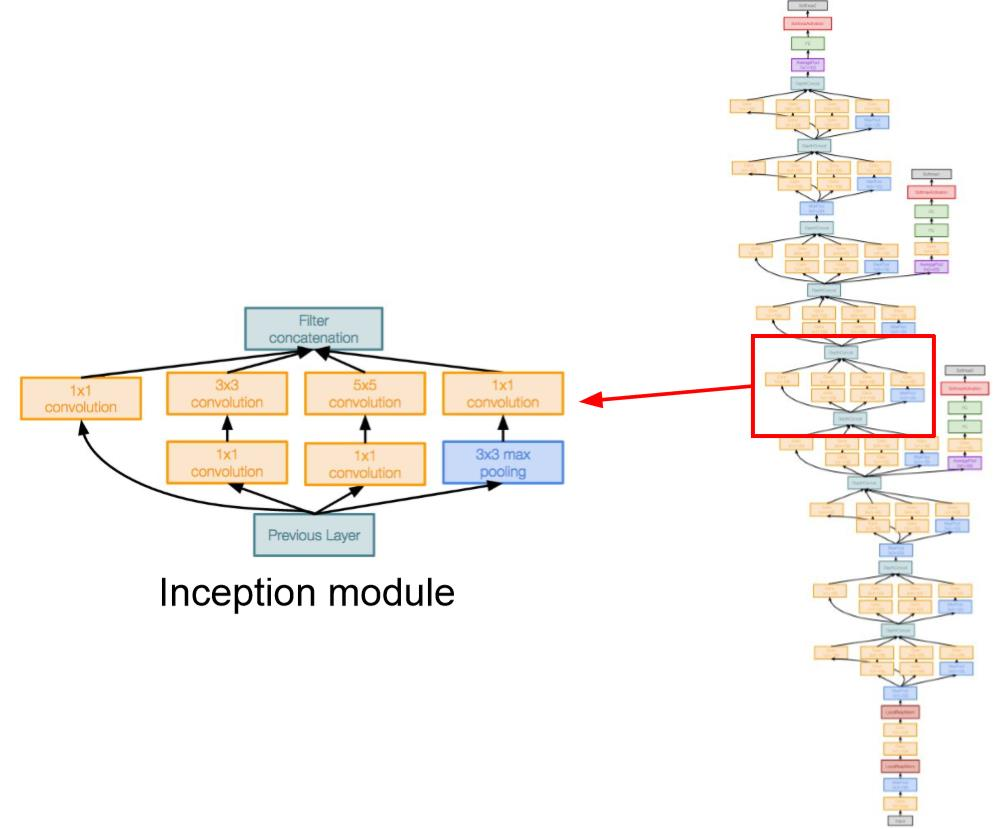
Naive Inception module
- 朴素Inception module
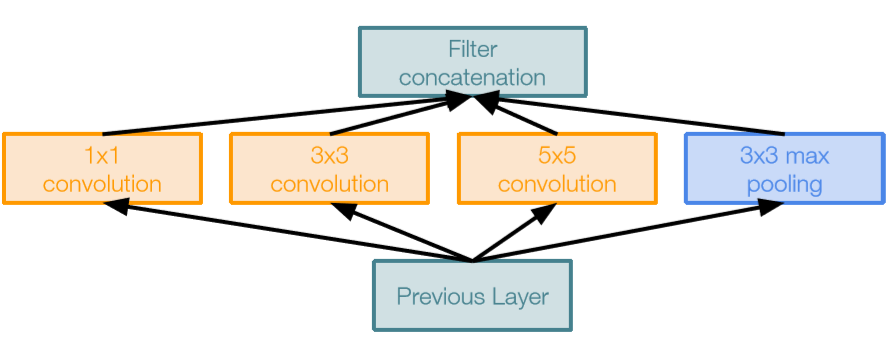
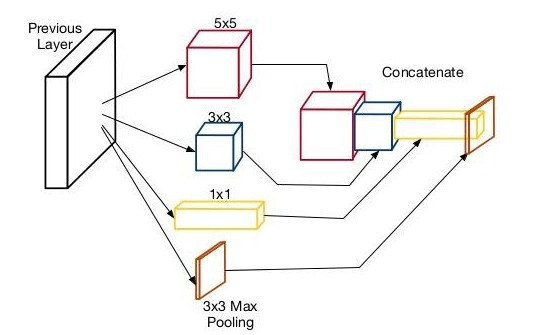
- 对前一层的输入进行并行滤波操作:
- 多个感受野大小(1x1,3x3,5x5)的卷积
- 池化操作(3x3)
- 所有滤波器输出沿深度(depth-wise)拼接在一起
设计理念
-
图像中的突出部分可能具有极大的尺寸变化,信息位置的这种巨大变化,卷积操作选择正确的核大小比较困难。
-
对于较全局分布的信息,首选较大的核,对于较局部分布的信息,首选较小的核。
-
非常深的网络容易过拟合。它也很难通过整个网络传递梯度更新。
-
简单地堆叠大卷积运算导致计算复杂度较高。
-
Naive Inception缺点:高计算复杂度
Conv Ops - [1x1 conv, 128] 28x28x128x1x1x256 [3x3 conv, 192] 28x28x192x3x3x256 [5x5 conv, 96] 28x28x96x5x5x256 Total: 854M ops
- 解决方案: 引入“bottleneck”瓶颈层,其使用 1x1 卷积来减小特征深度
Inception module with dimension reduction
- 具有降维的Inception Module

- Shortcut连接: 1×1卷积
- 多尺度滤波1: 1×1卷积+3×3卷积 (不同感受野结合)
- 多尺度滤波2: 1×1卷积+5×5卷积 (不同感受野结合)
- 池化分支 : 3×3 pooling + 1×1卷积
-
inception结构的主要贡献:一是使用1x1的卷积来进行降维;二是在多个尺寸上同时进行卷积再聚合
-
计算复杂度
Conv Ops - [1x1 conv, 64] 28x28x64x1x1x256 [1x1 conv, 64] 28x28x64x1x1x256 [1x1 conv, 128] 28x28x128x1x1x256 [3x3 conv, 192] 28x28x192x3x3x64 [5x5 conv, 96] 28x28x96x5x5x64 [1x1 conv, 64] 28x28x64x1x1x256 Total: 358M ops (<< 854M ops naive)
多尺度聚合的作用
- 多尺度:对输入特征图分别在3×3和5×5的卷积核上进行滤波,提高了所学特征的多样性,增强了网络对不同尺度的鲁棒性。
- 多层次:符合Hebbian原理(“fire togethter, wire together” ),即通过1×1卷积把具有高度相关性的不同通道的滤波结果进行组合汇聚一起,起到加速收敛的作用。
GooLeNet网络结构
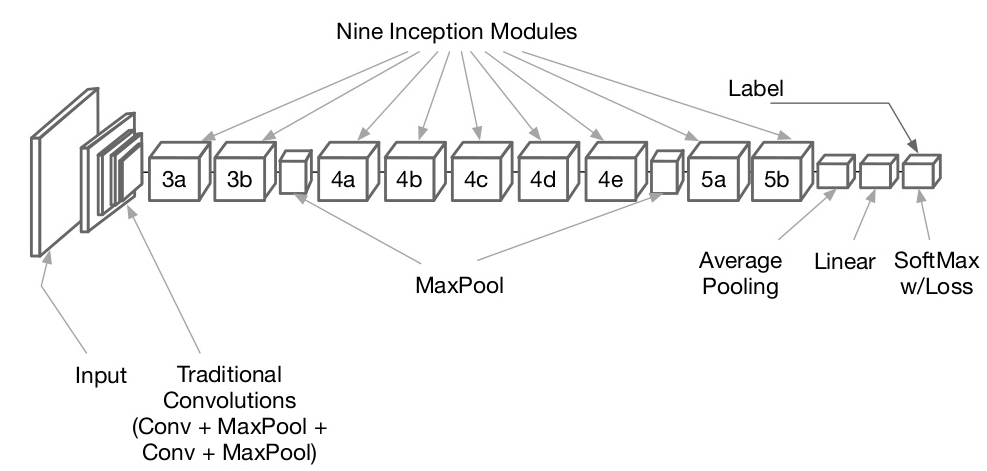
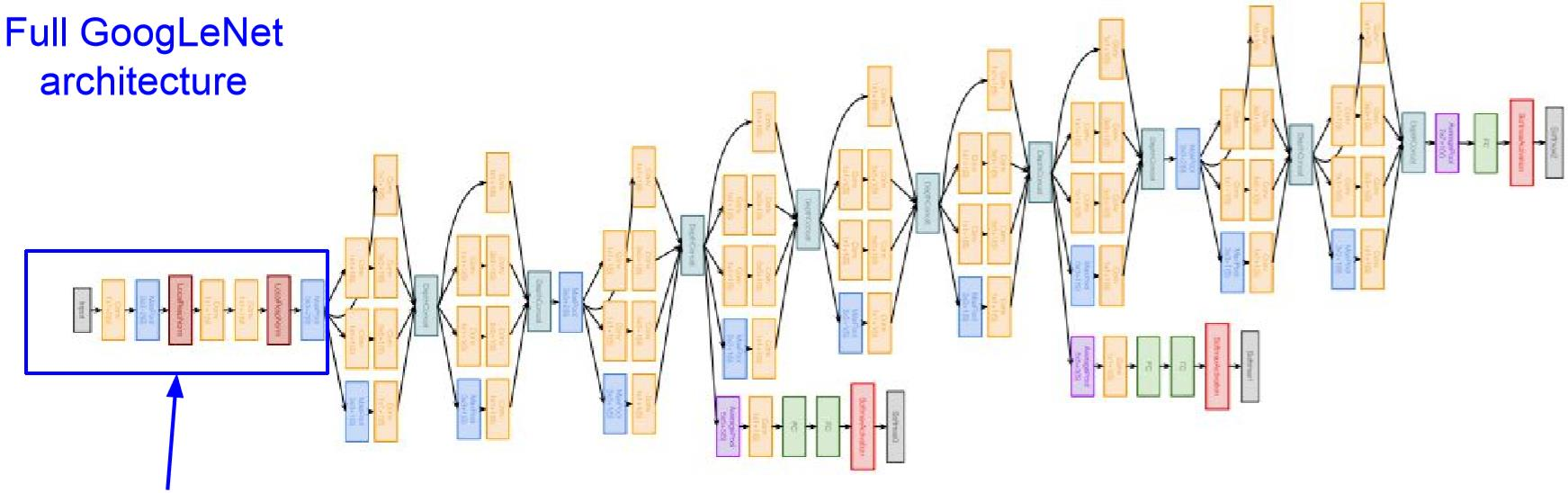
- 传统卷积操作:Conv-Pool-2x Conv-Pool
- 9个堆叠的Stacked Inception Modules
- 分类输出:Classifier output(removed expensive FC layers!),使用了最大平均池化,代替了全连接层,没有参数,不会产生过拟合问题
- 辅助分类器:辅助分类输出,用于在较低层注入额外的梯度(AvgPool-1x1Conv-FC-FC-Softmax),缓解梯度消失问题
损失函数
- 训练时的Inception net的总损失 :
- 2个附加的辅助损失纯粹用于训练目的,在推理(测试)过程中被忽略。
BN-Inception
- BN-Inception,2015,google提出对GoogLeNet Inception v1的改进
改进
- 引入Batch Normalization(批归一化):目前BN已经成为几乎所有卷积神经网络的标配技巧
- 5x5卷积核 -> 2个串联的3x3卷积核
Batch Normalization
- 内部协变量偏移(Internal Covariate Shift):训练时网络参数的变化引起的网络激活分布的变化
- 小的扰动会引起后续大的变化,网络训练变得复杂。
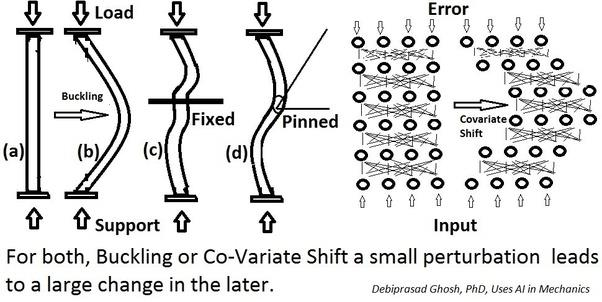

- 2018年的论文认为BN可以优化的原因,不是协变量偏移,而是BN使得优化地貌更平滑,使梯度更具预测性和稳定性,达到更快训练的目的。
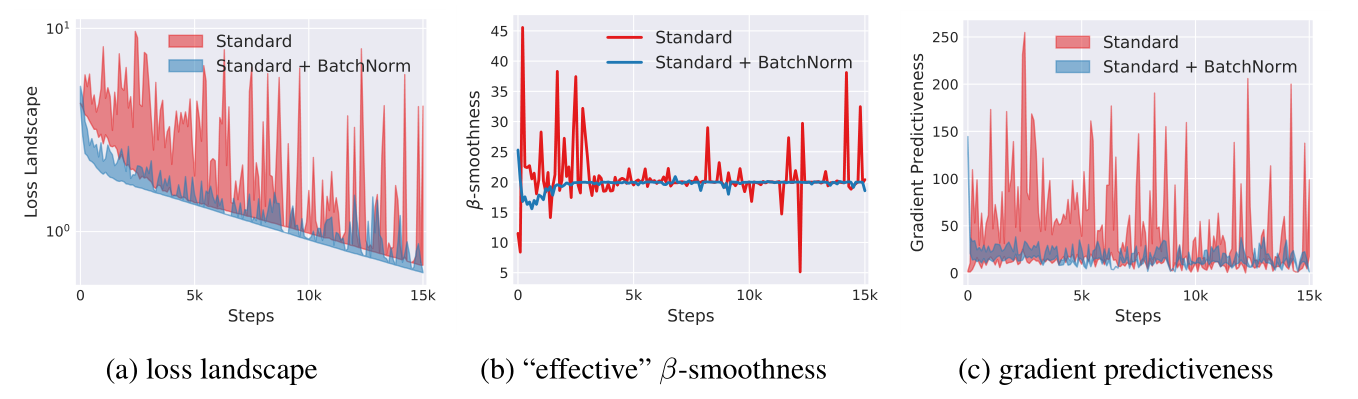
- BN调整的位置:卷积 -> BN -> ReLU
- 每一维度变为标准高斯分布:,ϵ防止分母为0。这样全部数据都为标准分布,又不能表达输入数据的真实分布
- 为了能使工作在激活的非线性区,再进行尺度缩放和平移:,利用γ(scale)和β(shift)做线型变换,做一个逆转操作。是mini-batch的样本空间,γ和β是习得的,利用小批量得到新的均值和方差替换整个训练集的均值和方差

- 预测时,均值方差不应该取决于随机小批量的数据,常用的方法是通过移动平均估算整个训练集的样本均值和方差,得到一个确定输出。
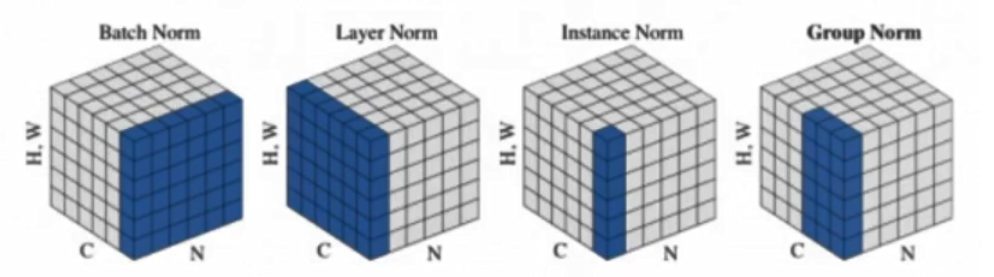
Group Normalization
- BatchNorm: batch方向做归一化,算
N*H*W的均值 - LayerNorm: channel方向做归一化,算
C*H*W的均值 - InstanceNorm: 一个channel内做归一化,算
H*W的均值 - GroupNorm: 将channel方向分group,然后每个group内做归一化,算
(C//G)*H*W的均值
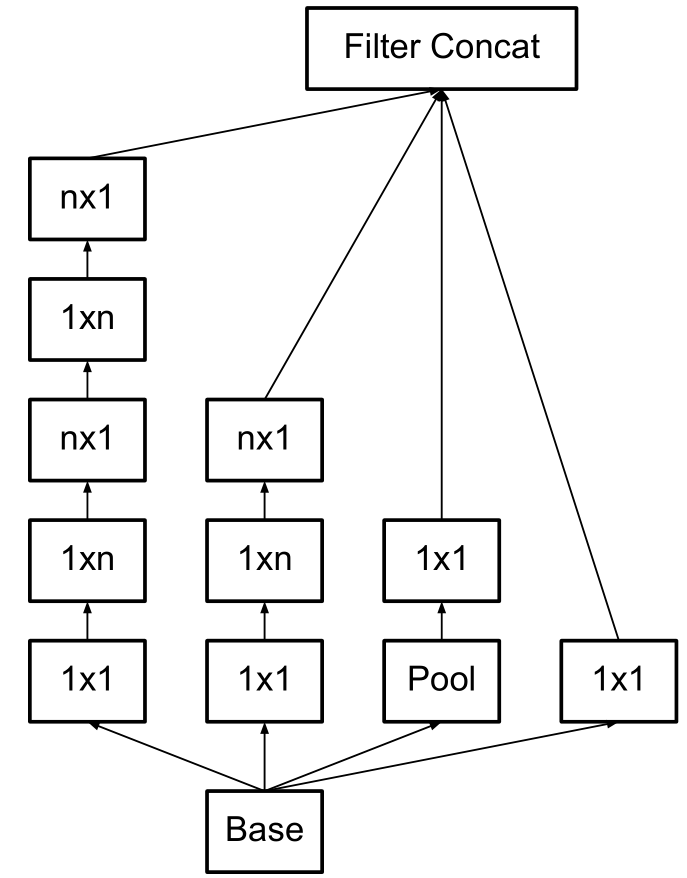
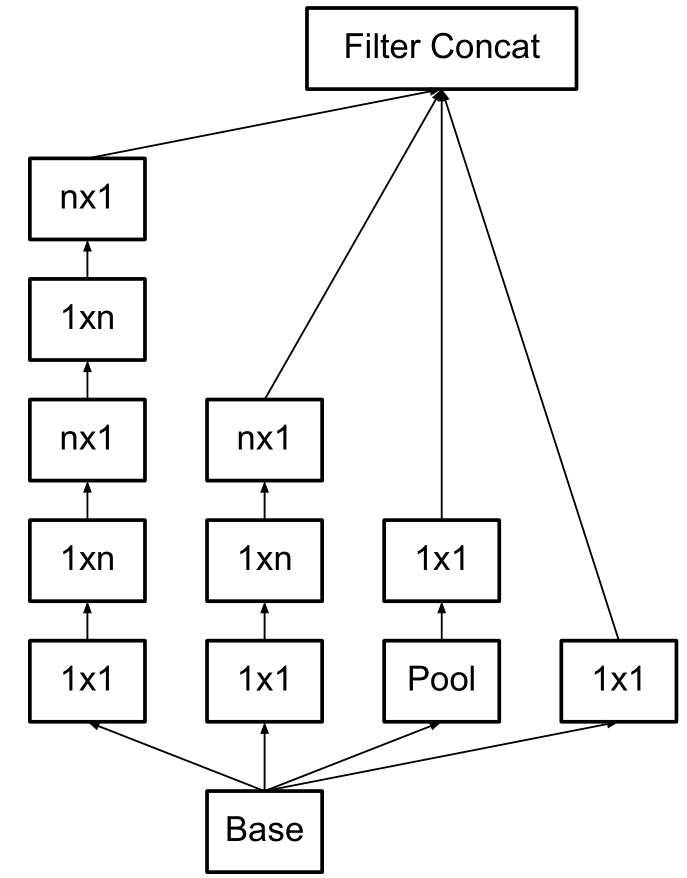
Inception-V2 V3
改进
- Inception-V2 V3优化了Inception Module的结构,有三种
- 5x5卷积由两个3x3替代,整个模块的处理后的特征图大小:35x35grid
- 3x3由1x3和3x1替代,整个模块经过1xn的替代后变为:17x17grid
- 这种模块更宽,特征图大小:8x8grid

-
辅助分类器的作用进行了研究
- 辅助分类器在训练过程即将结束、准确度接近饱和时才会有很大贡献, 并不会帮助更快收敛。
- 它们起到正则化作用,特别是具有BatchNorm或Dropout操作时。
- 两个辅助分类器中较低层的那个可以去掉
-
引入了标签平滑正则化(label-smoothing regularization, or LSR),可以避免过拟合,防止网络对于某一个类别预测过于自信。
- 软标签定义: ,
ϵ是极小数,这样ground truth对应标签有大部分的概率,而其他类别也有一小部分概率。 - 新的交叉熵损失变为:,类别K=1000,u(k)=1/1000,ϵ=0.1
- 软标签定义: ,
网络配置
-
v2中有10个inception的堆叠,3个35x35的module,5个17x17的module,2个8x8的module
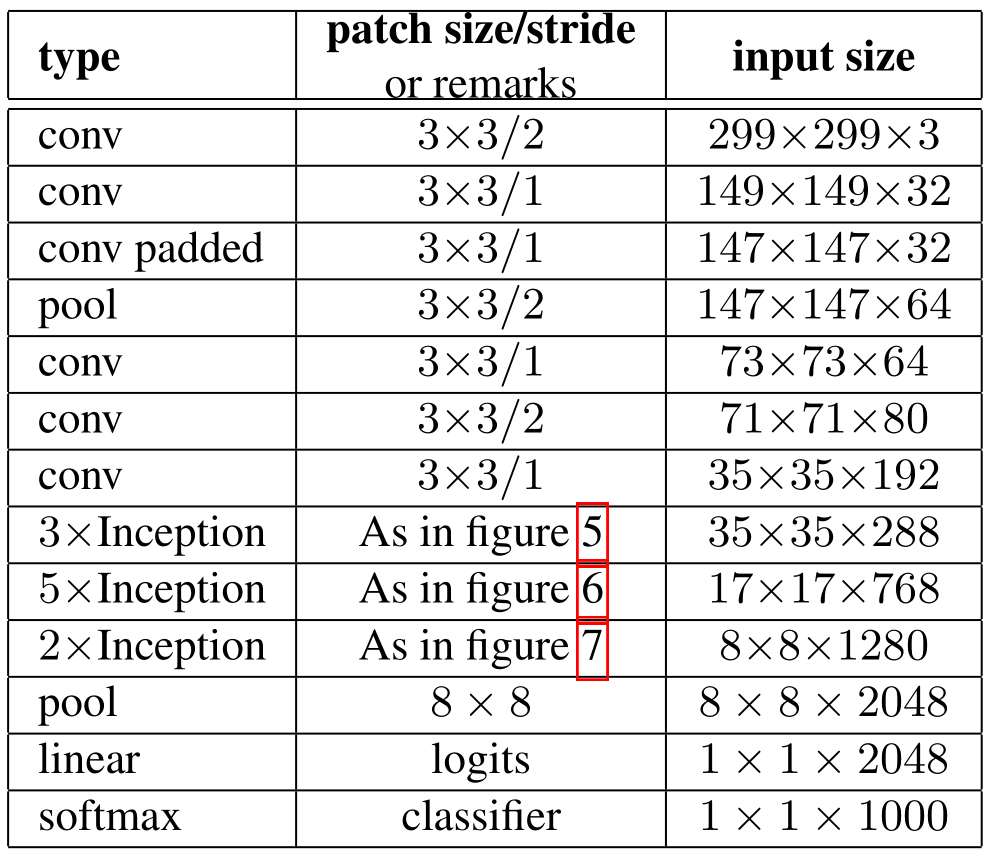
-
v3的结构就是在v2的基础上,加上标签平滑和辅助分类器
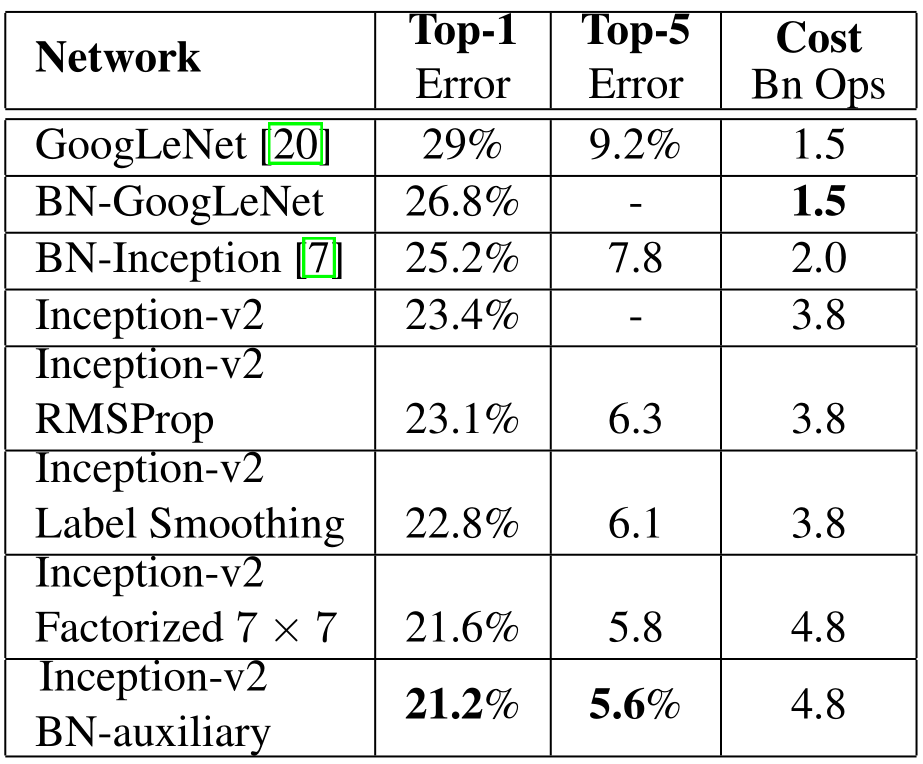
ResNet
- ResNet2016,在多项比赛中取得了第一,并且指标远远超过第二
改进
- 更深的网络:152层
- 残差映射
残差映射
- 作者发现简单堆叠更深的CNN网络并不会提升学习能力,反而减弱了模型学习能力。
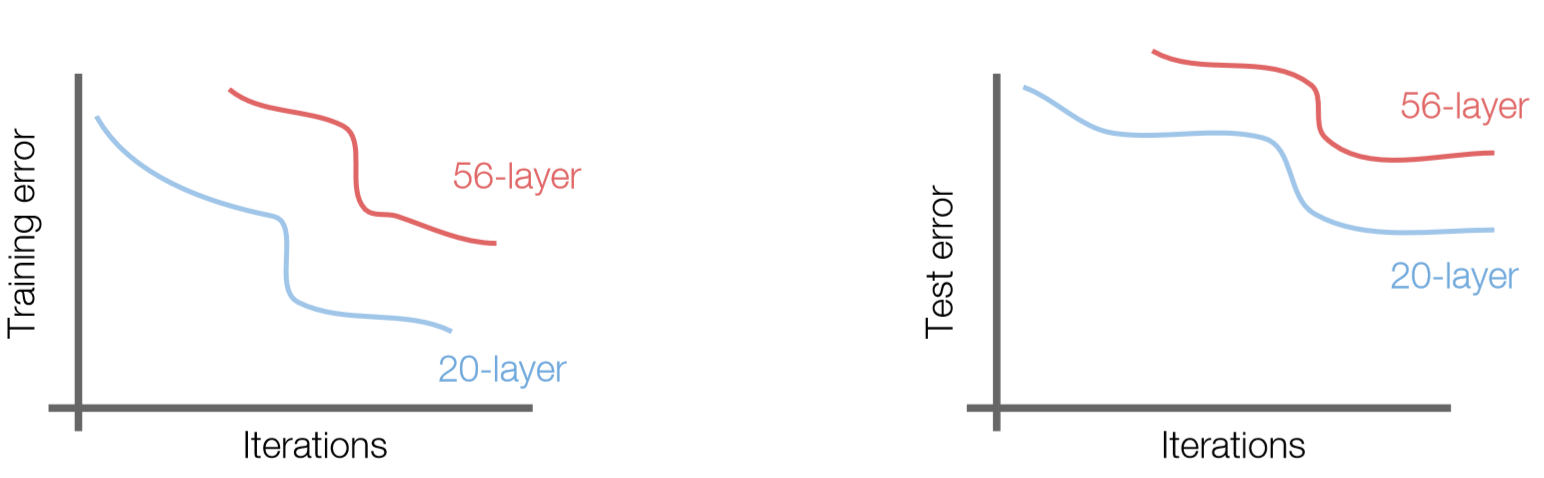
- 解决方法:使用网络层来学习残差映射(residual mapping )而不是直接学习期望映射
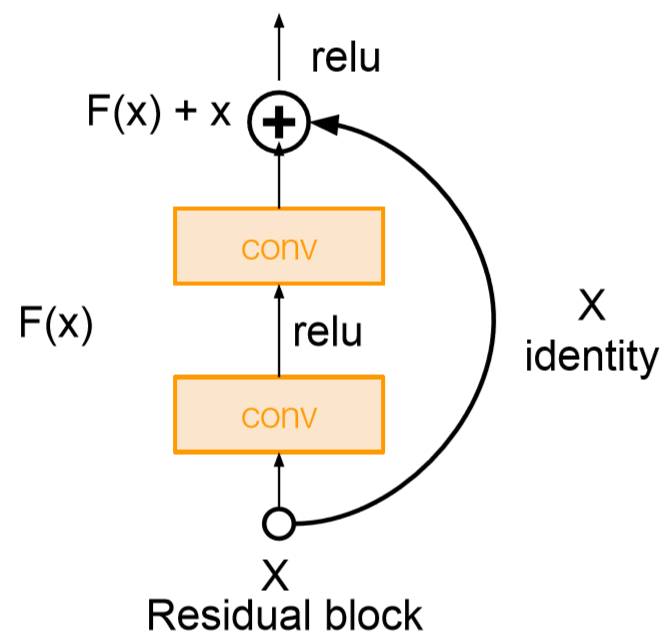
- ResNet增加了“短路”连接(shortcut connection)或称为跳跃连接(skip connection),残差的引入去掉了主体部分,从而突出了微小的变化,模型只需要学习微小变化即可,使得网络更容易学习。
不同网络结构直连
- 当𝐹和𝑥相同维度时,直接相加(element-wise addition),
- 当𝐹和𝑥维度不同时,需要先将𝑥做一个变换(linear projection),然后再相加,,𝑊𝑠仅仅用于维度匹配上。
- 对于𝑥的维度变换,一种是zero-padding,另一种是通过1x1的卷积。
网络结构
基准网络
- 基于VGG19的架构,首先把网络增加到34层,增加过后的网络叫做plain network,在此基础上,增加残差模块,得到Residual Network
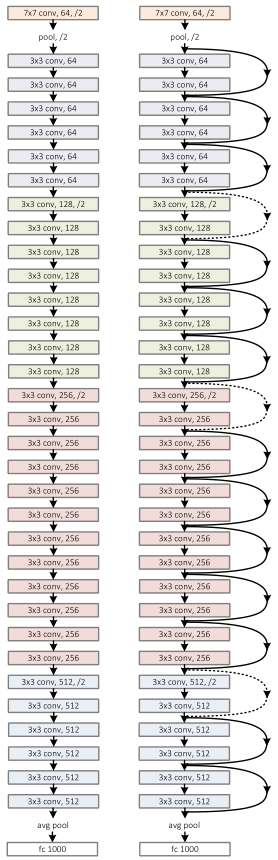
- 把网络增加到34层, 采用两个设计原则, 1)对于有相同的输出特征图尺寸,滤波器的个数相同; 2)当特征图尺寸减半时,滤波器的数量加倍。
- 下采样的策略是直接用stride=2的卷积核。网络最后末尾是一个全局卷积平均池化层和一个1000的全连接层(后面接softmax)。
残差网络
- 在基准网络的基础上,插入了shortcut connections。
- 当输入输出具有相同尺寸时, identity shortcuts可以直接使用(实线部分),就是公式1;
- 当维度增加时(虚线部分),有以下两种选择:
- A:仍然采用恒等映射,超出部分的维度使用0填充;
- B:利用1x1卷积核来匹配维度。
- 对于上面两种方案,当shortcuts通过两种不同大小的特征图时,采取A或B方案的同时, stride=2。
残差模块
- 两种残差模块
- 两个3x3的卷积核
- 输入是256维,两个1x1的卷积核,通道数不一样,一个3x3卷积核。也叫做瓶颈残差模块
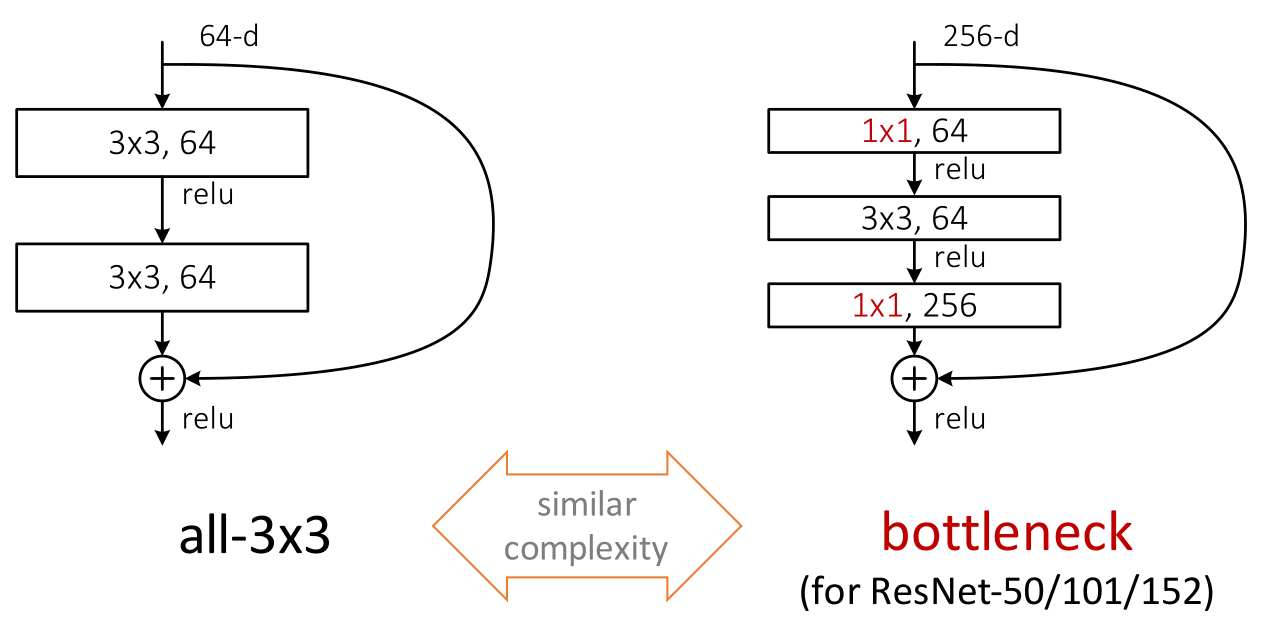
- 在训练浅层网络的时候,选用前面这种
- 而如果网络较深(大于50层)时,会考虑使用后面这种(bottleneck)来提高效率。网络的参数减少了很多,训练也就相对容易一些
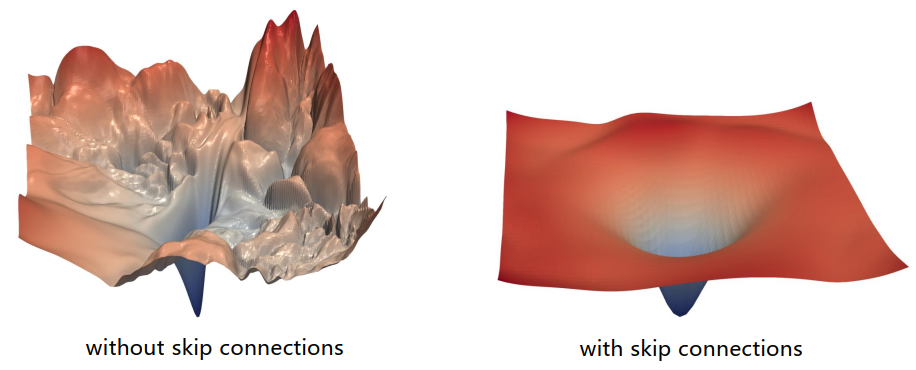
对残差模块提高效率的研究
- 残差模块平滑了损失地貌
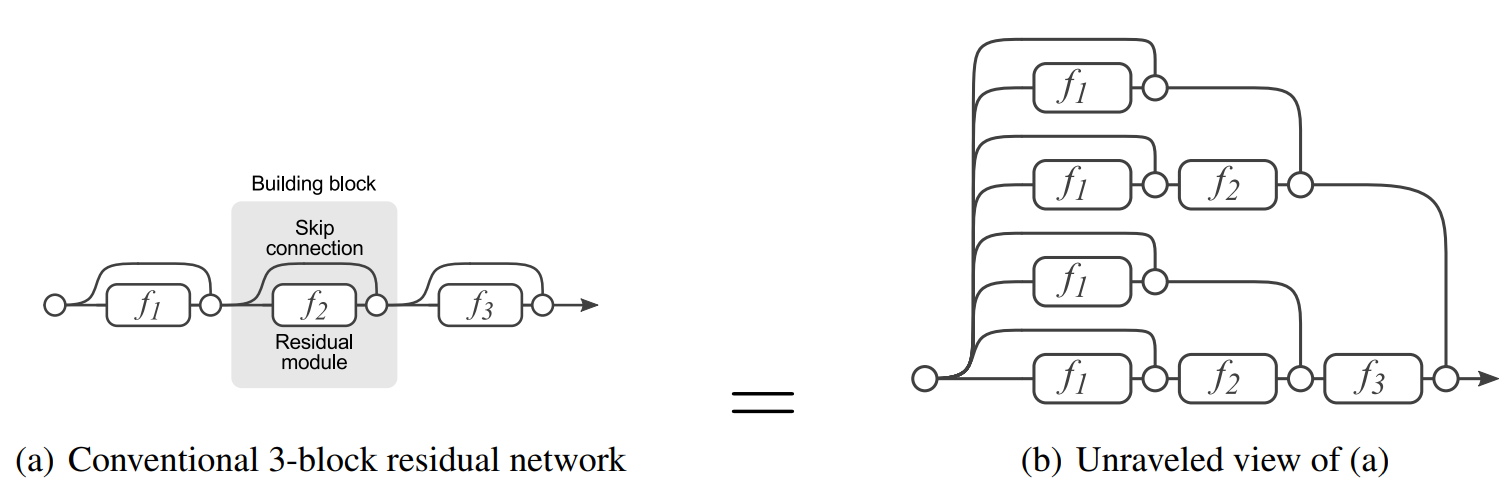
- 有残差的模块等效于多个网络并联
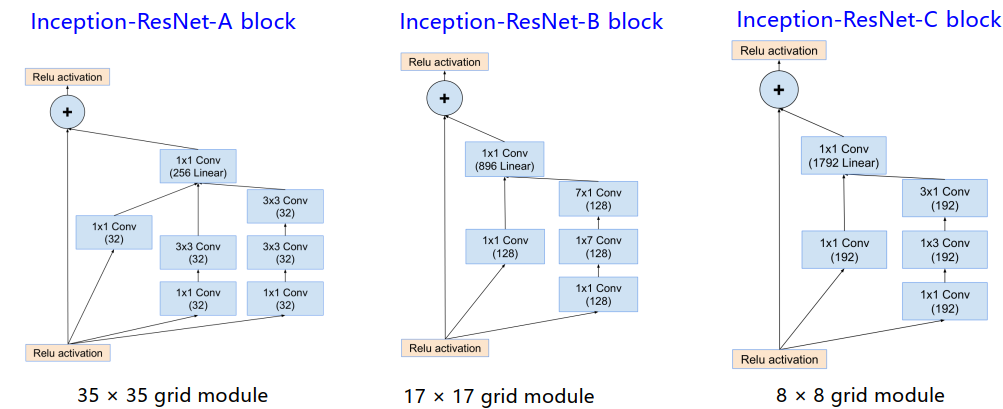
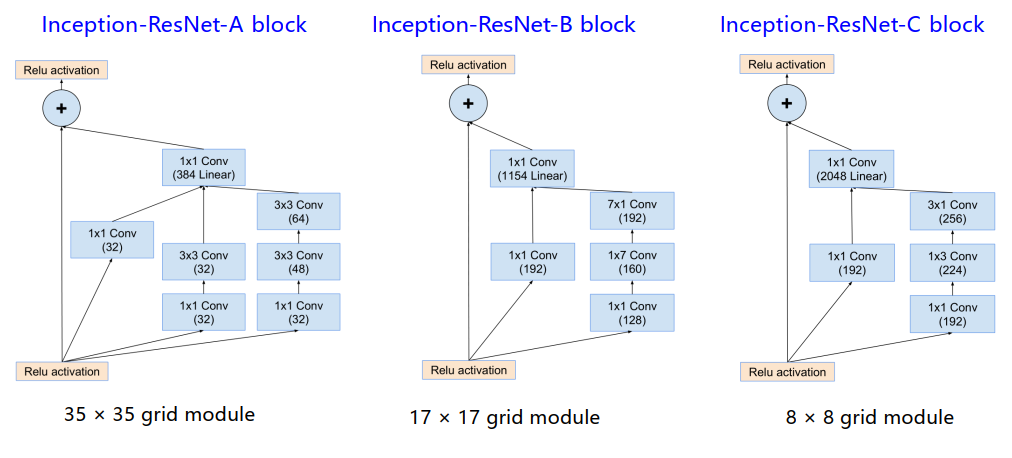
Inception-V4 ResNet
改进
Inception-v4
- 更深、更宽、更规整的网络架构
Inception-ResNet
- 改进的Inception模块和残差连接的结合
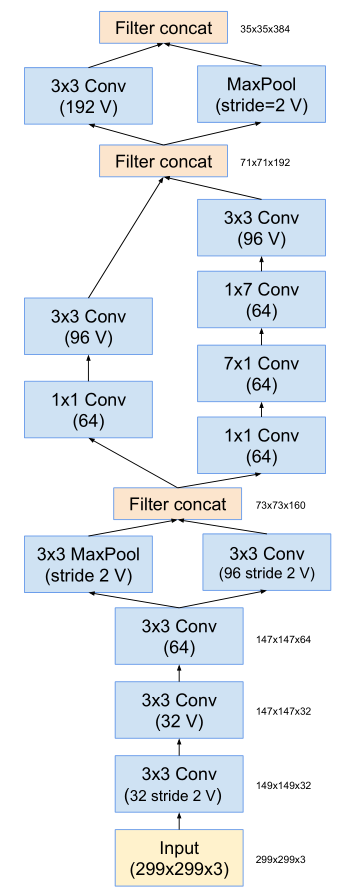
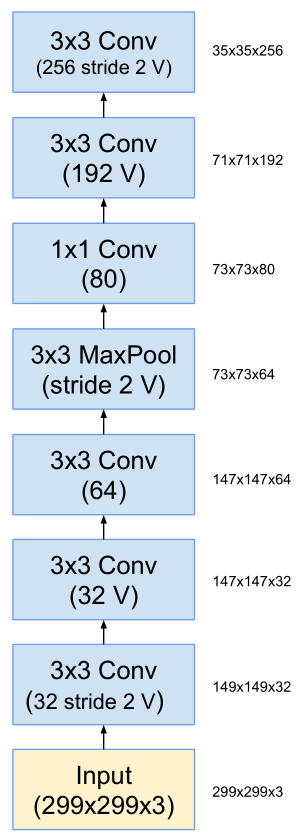
Inception-v4网络结构
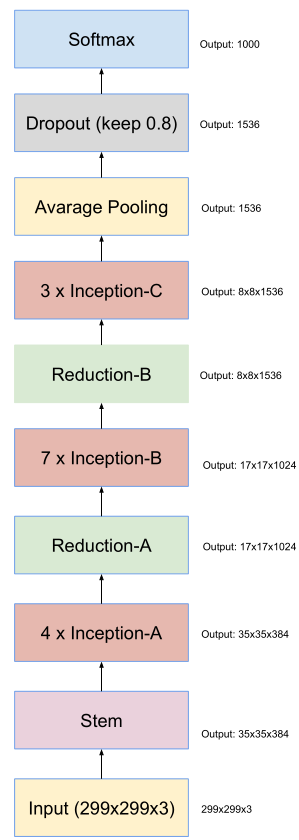
-
stem层包括:卷积、池化、聚合,没有标记“V” 的卷积使用same的填充原则,
即其输出网格与输入的尺寸正好匹配。标记“V” 的卷积输出激活图(output activation map)的网格尺寸也相应会减少。
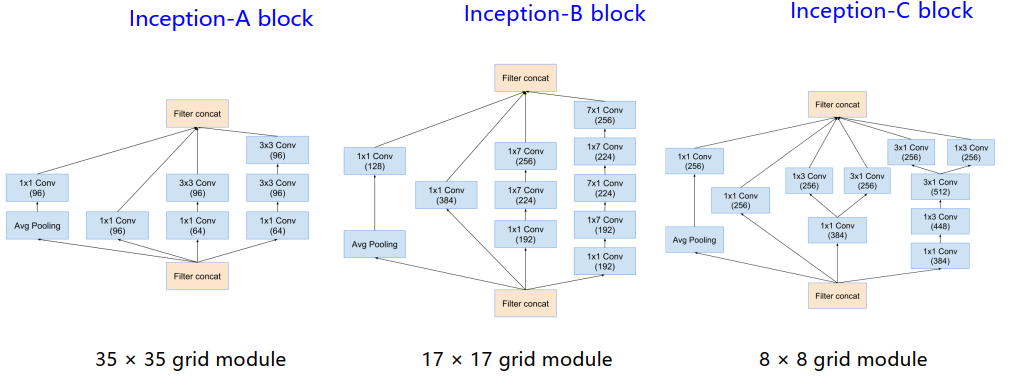
-
Inception-v4的ABC block也进行了一些更改
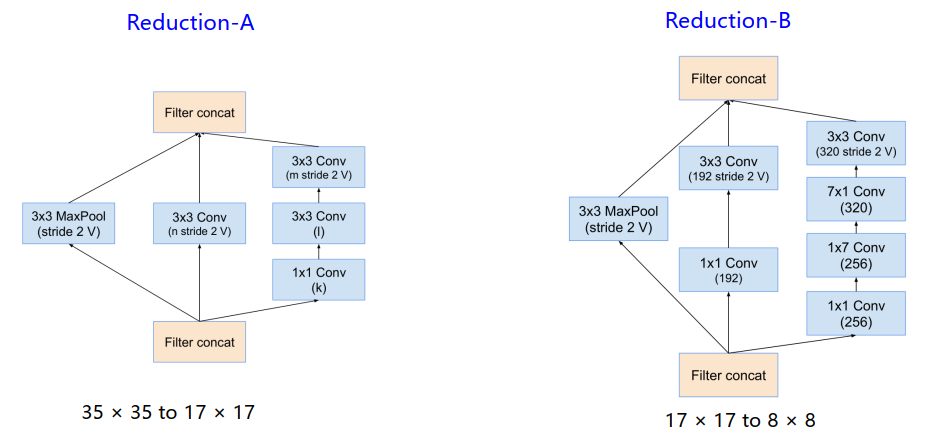
- 不同Inception连接时,使用了Reduction模块,减少了feature map,却增加了filter bank
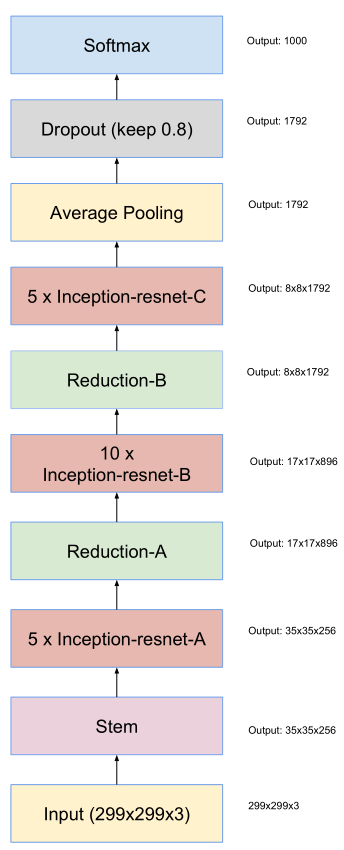
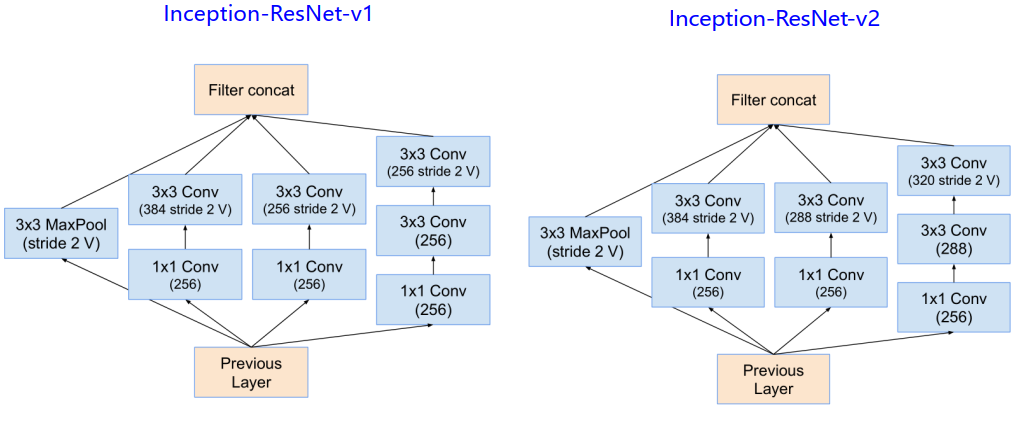
Inception-ResNet网络结构
- 引入直连,与ResNet结合,让网络又宽又深
ResNeXt
- ResNeXt2017,Inception借鉴ResNet提出Inception-ResNet,ResNet也借鉴Inception提出ResNeXt,主要就是单路卷积变成多个支路的多路卷积,进行分组卷积。
Inception改进
- Inception卷积范式:将多个不同的卷积视野融合,缺点就是太复杂,人工设计痕迹过重
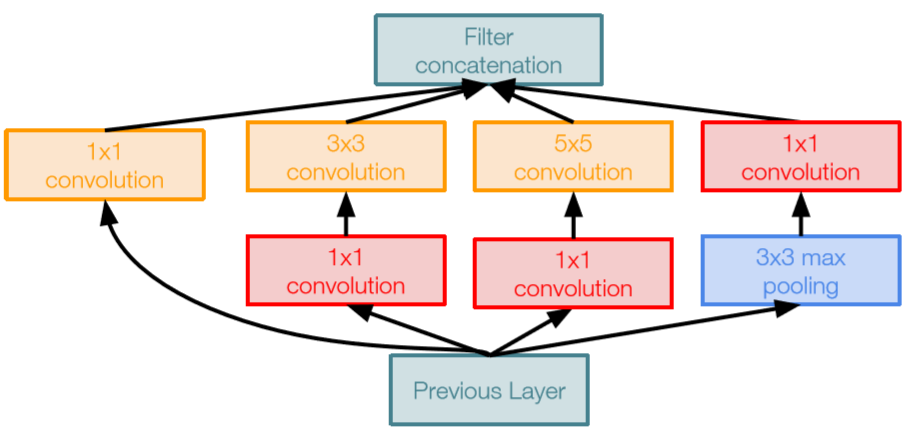
- 分析了神经网络的标准范式,就是先对输入的m个元素,分配到m个分支(split),进行权重加权(transform),然后求和(merge),最后经过一个激活:。
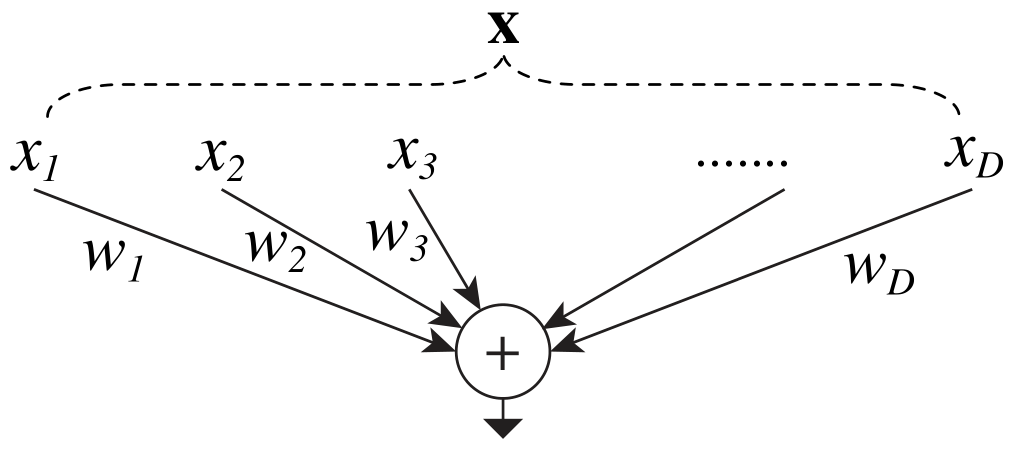
-
由此归纳出神经网络的一个通用的单元可以用如下公式表示:
-
聚合变换:变换𝑇可以是任意形式。类似于一个简单的神经元, 𝑇𝑖将𝑥投射到一个低维嵌入中,然后对其进行转换。
-
一共有C个独立的变换,作者将C称之为Cadinality(基数),并且指出,基数C对于结果的影响比宽度和深度更加重要。
-
Network-in-Neuron: expands along a new dimension扩展新的维度
-
Network-in-Network (NIN): increases the dimension of depth增加或者减少深度方向的维度
网络结构
- 与ResNet相比,模块更加复杂,增加了Cadinality,通过多个并行路径(“cardinality” ) 增加残差块的宽度。并行路径在精神上与Inception模块类似
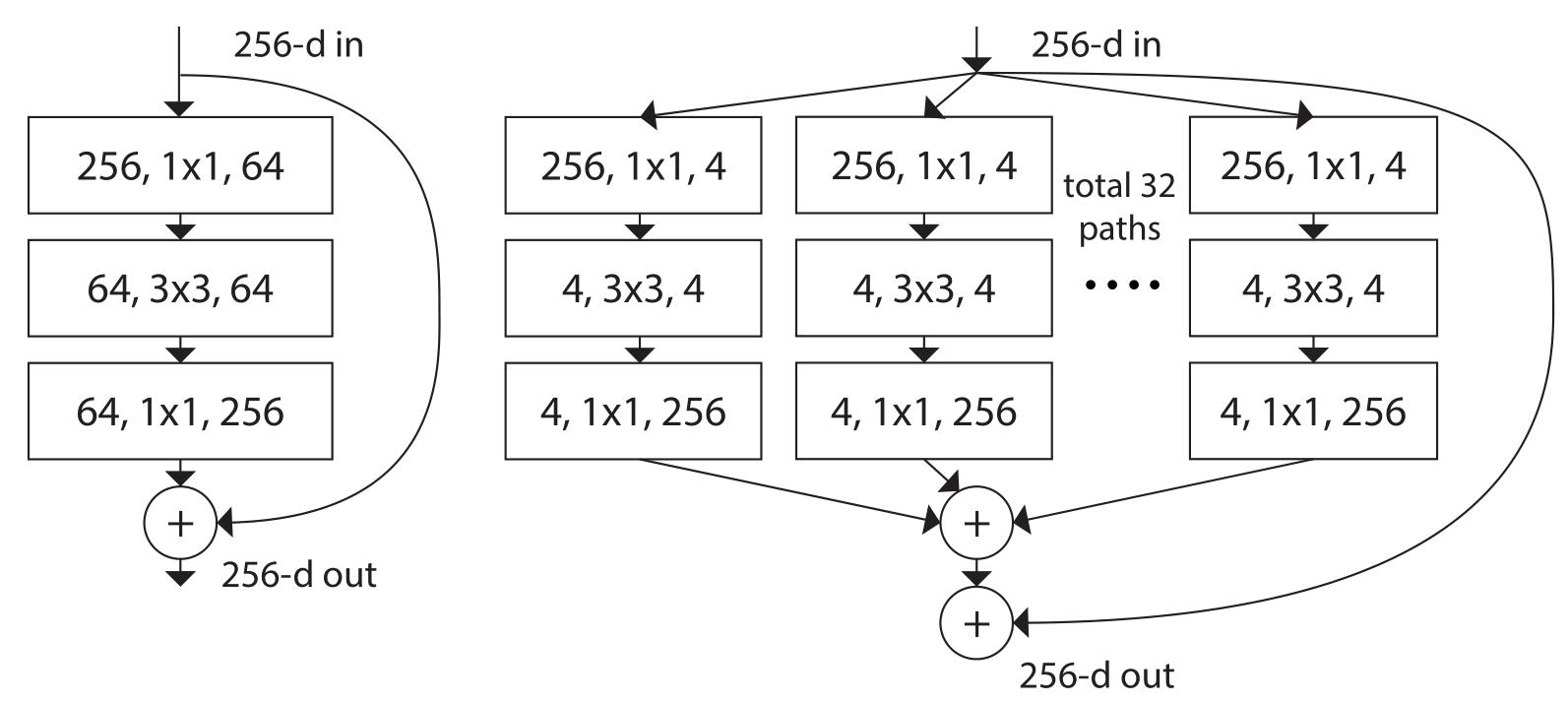
DenseNet
- DenseNet2017,借鉴了ResNet的思想
改进

-
在dense block中,每一层以前馈方式连接到每一个其它的层
-
减轻梯度消失,加强特征传播,鼓励特征重用
-
每一层均直接与前面的所有层相连,实现特征的重复利用;同时把网络的每一层设计得特别“窄”,即只学习非常少的特征图,达到减少参数的作用。
-
传统卷积网路的前向公式:
-
ResNet网路的前向公式:
-
DenseNet网路的前向公式:
网络结构
DenseNet-A
- 输入经过BN、ReLU、Conv,变为k通道的输出
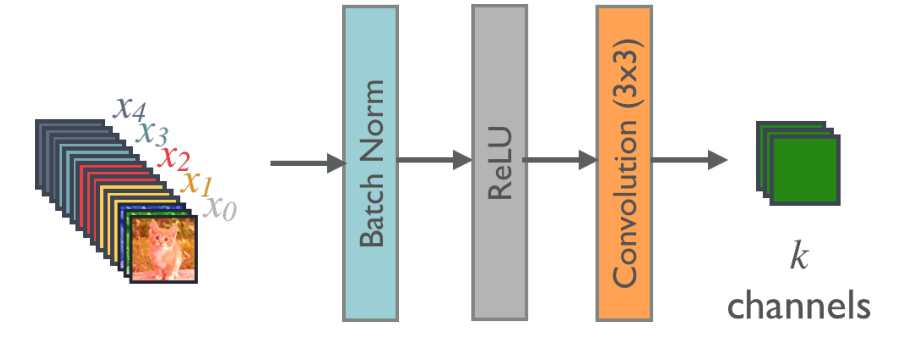
DenseNet-B
- 引入了1x1的瓶颈层,减少输入特征图的数量,提高计算效率
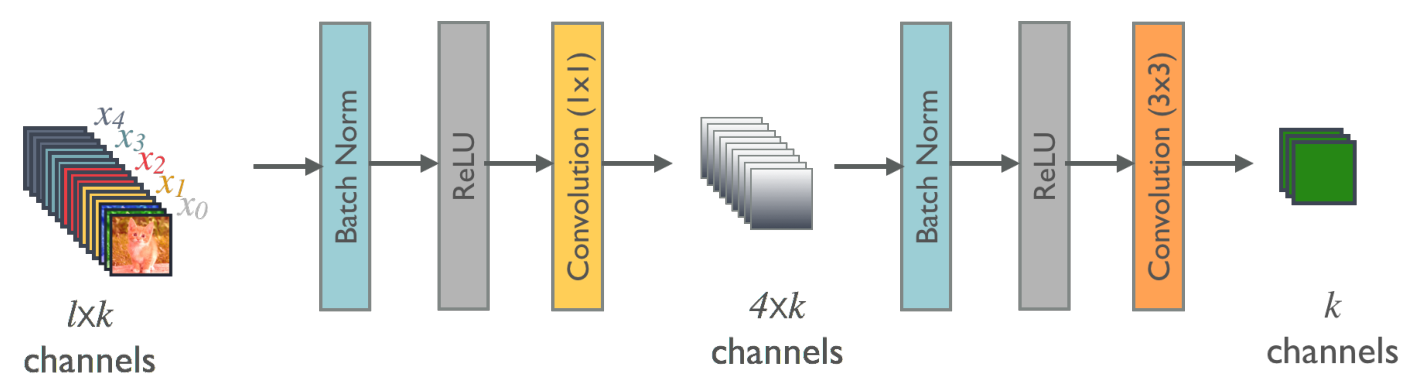
增长率growth rate
- 每个函数𝐻产生𝑘个特征图。DenseNet可以具有非常窄的层,例如, 𝑘 = 12。将超参数𝑘称为网络的增长率(growth rate)。
- 一种解释是,每个层都可以访问其块中的所有前面的特征图,因此可以访问网络的“集体知识”(collective knowledge)。 可以将特征图视为网络的全局状态。 每个层都将自己的𝑘个特征图添加到此状态。
- 增长率规定了每层为全局状态贡献了做出多少新信息。 一旦写入,全局状态可以从网络中的任何地方访问,并且与传统网络体系结构不同,不需要在层与层之间复制它。
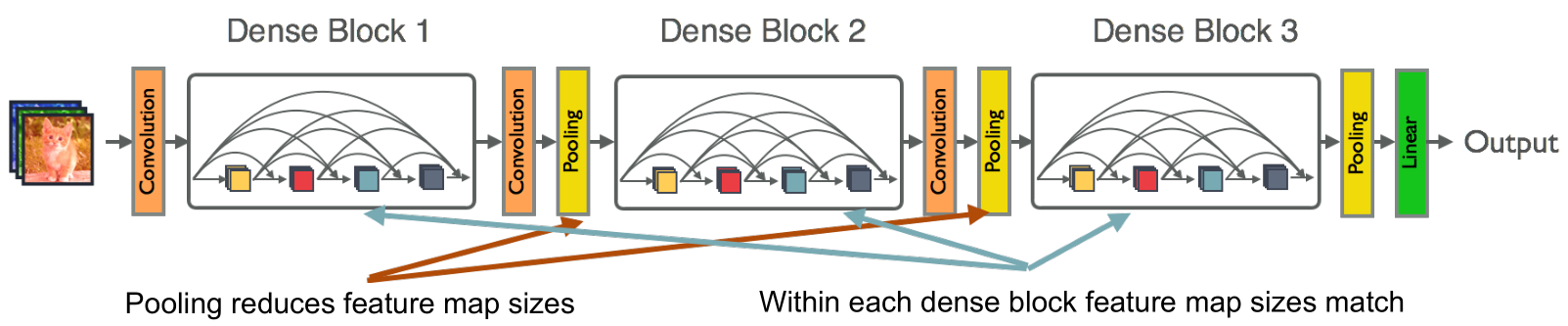
- 两个相邻块之间的层称为过渡层(transition layers),通过卷积和池化来改变特征图大小。为了进一步提高模型的紧凑性,可以减少过渡层的特征图数量。 如果密集块包含𝑚个特征图,让下面的过渡层生成θm个输出特征图,其中0<𝜃≤1被称为压缩因子
目标检测
数据集
| 名称 | 说明 |
|---|---|
| PASCAL VOC | PASCAL VOC竞赛提供的数据集,包含了20类的物体,主要任务是分类,检测,分割,人体布局,人体动作识别 |
| ImageNet | 计算机视觉数据集,包含14,197,122个张图片, 21,841个Synset索引。它一直是评估图像分类算法性能的基准。 |
| COCO | 全称是Microsoft Common Objects in Context,起源于是微软于2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。 |
基于建议框的方法:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、FPN
免建议框方法YOLO、SSD、DSSD、RetinaNet
two-stage:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN
one-stage:YOLO、SSD、DSSD、RetinaNet
R-CNN
R-CNN2014,是使用CNN目标检测的开山之作。
区域建议的方法
- 滑动窗口:窗口大小进行穷举扫描整图
- 选择性搜索(selective search):自底向上,像素级别的提取,相同则合并,逐步扩大区域,合并到不同尺度
主要流程
输入图像->获取候选区域推荐列表,并将区域大小统一变换->卷积神经网络训练->区域内目标分类
区域建议
- 使用Selective Search方法选择约2000个置信度最高的区域建议
区域变换

- A:原始区域建议
- B:有背景
- C:没有背景
- D:没有背景直接变换固定大小
提取特征
- R-CNN中的CNN使用AlexNet, softmax层改成(N+1)-way,其余不变
- 由于CNN的参数量巨大,训练CNN需要大量的样本。
- 提取过程
- 提取所有图像的区域建议
- 对于每个区域:转换为CNN输入大小,CNN前向计算,将Pool5特征保存到磁盘
- 大硬盘存储要求: PASCAL数据集的功能大约为200GB
- Pool5特征也将用于Bounding Box Regression边界框回归的计算
- 对比Pool5层以及FC层,可以看出FC7层相对的mAP要高很多,尤其是经过预训练后的网络。一方面原因是Pool5层的特征尺寸比较大,另一方面是全连接层特征更加符合类别信息
分类训练
- 使用SVM分类器训练,采用hard negative mining方法提升SVM分类器的准确度
- R-CNN利用FC7得到的特征,SVM训练将IoU<0.3的样本作为负样本
- 作者发现: CNN的IoU阈值大一点时,定位精度更准确。SVM的IoU阈值小一点可以增加样本数目,提高泛化能力。
Hard Negative Mining (困难负样本挖掘)
- SVM训练完成后,如果完全分类正确,所有正样本的输出概率都大于0.5,而所有负样本的输出概率都小于0.3
- 但常见的情况是有一部分的负样本的输出概率也大于0.5的, 这些样本就称之为“False Positives”
- 如果把产生“False Positives” 的样本收集起来,对SVM进行二次训练,一般可提升SVM的分类准确度
目标检测
- 目标检测流水线(pipeline),产生proposal后使用分类网络给出每个框的每个类别的置信度,使用回归网络修正位置,最终应用NMS(非极大值抑制, non-maximum suppression)

非极大值抑制(non-maximum suppression)
- 由于有多达2K个区域候选,如何筛选得到最后的区域呢?目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框
- 滤除低置信度的选择框,选择最高置信度的候选框,计算其余候选框的IoU,删除大于阈值的候选框,对下一个最高阈值的候选框重复操作,直到无候选框可以被抑制
边界框回归
- 对于每个类别,训练一个线性回归模型,利用缓存的Pool5层特征使错位的建议框向标定的GT(Ground Truth)框做偏移修正。与GT的 IoU大于0.6的才会考虑。重叠较大才会适合线性回归
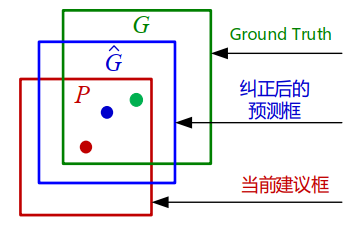
- R-CNN是利用Pool5层特征进行回归。 Bounding Box是类别相关的,即不同类的bbox回归的参数不同。
- 假设区域位置,真实位置,定义转换函数
- 转换公式:平移: 缩放:
- 假设每个偏移量是Pool5特征的一个线性映射,也就是:,w为可学习矢量。
- 通过最优化正则化的最小平方目标函数(岭回归,l2范数)学习w:,目标t:
RNN的训练
- 有监督的预训练(Supervised pre-training)
- 利用有分类标签但无Bbox的ILSVRC2012数据集(ImageNet)进行训练
- 特定领域的微调(Domain-specific fine-tuning)
- 对特定数据集( 如PACAL VOC )进行fine-tuning训练。 PACAL VOC, N = 20;
- 将网络最后的1000类的分类层换成21的分类层(20个VOC中的类别+1个背景类)
- 为保证训练只对网络微调,设置较小的SGD学习率(0.001)
- 计算每个region proposal与人工标注GT框的IoU。IoU阈值设为0.5,大于这个阈值则为正样本,否则为负样本。将正样本定义的很宽松,为了尽可能获取尽量多的正样本
- 在迭代训练中,使用32个正样本(包括所有类别)和96个背景样本组成的128张图片,构成一个mini batch训练组
缺点
- 将网络最后的1000类的分类层换成21的分类层(20个VOC中的类别+1个背景类)
- 训练在空间和时间上都很昂贵
- 目标检测很慢
SPP-Net
- SPP-Net2014,可用于分类和检测在ILSVRC 2014竞赛中检测取得第2,识别第3
改进
-
与RNN不同,直接对图片进行裁剪和放缩,会导致信息丢失和变形,减低识别准确率。真正需要固定长度的是最后的全连接层
-
具体步骤:image->conv layers->spatial pyramid pooling->fc layers->output
-
在图像卷积后,经过固定大小的空间金字塔池化层(spatial pyramid pooling),再全连接输出。这样,input可以是任意尺寸大小的图片
-
相比于R-CNN,SPP-Net不需要提取边界框,可利用网络提取目标区域的特征。
-
特征图:卷积层使用滑动滤波器,其输出具有与输入大致相同的宽高比。这些输出称为特征图: 涉及响应的强度和它们的空间位置
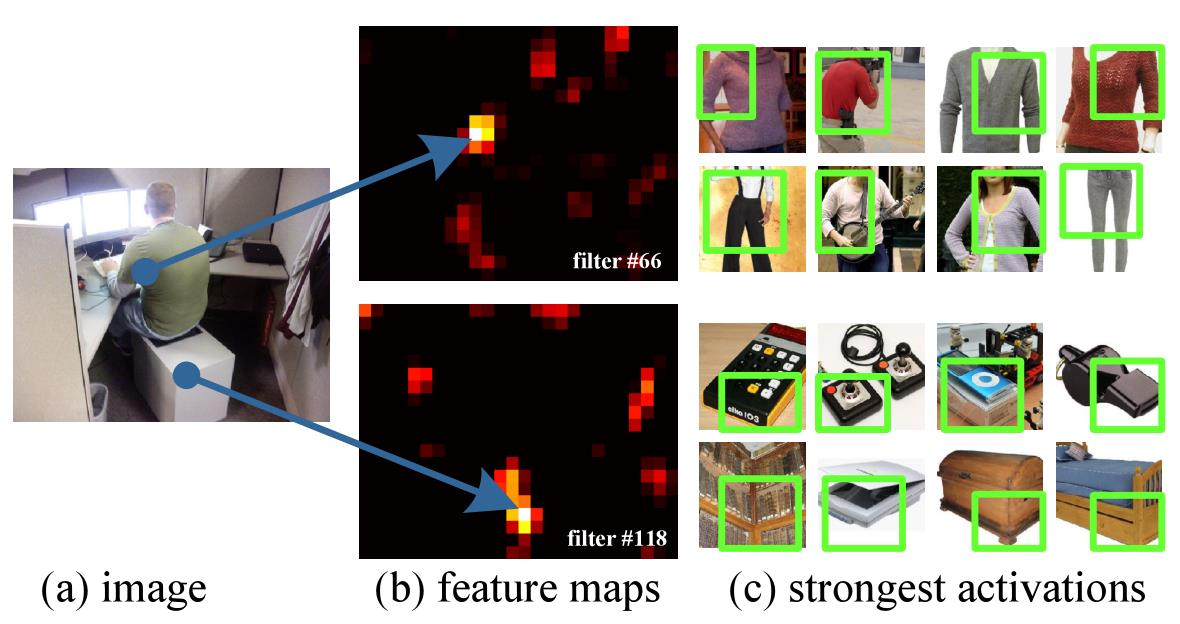
- 输入图片的某个位置的特征反应在特征图上也是在相同位置
- 对某个区域的特征提取只需要在特征图上的相应位置提取
空间金字塔池化层
- 全连接层的输入大小是固定的,所以任意图像大小卷积后,需要通过空间金字塔池化层处理。
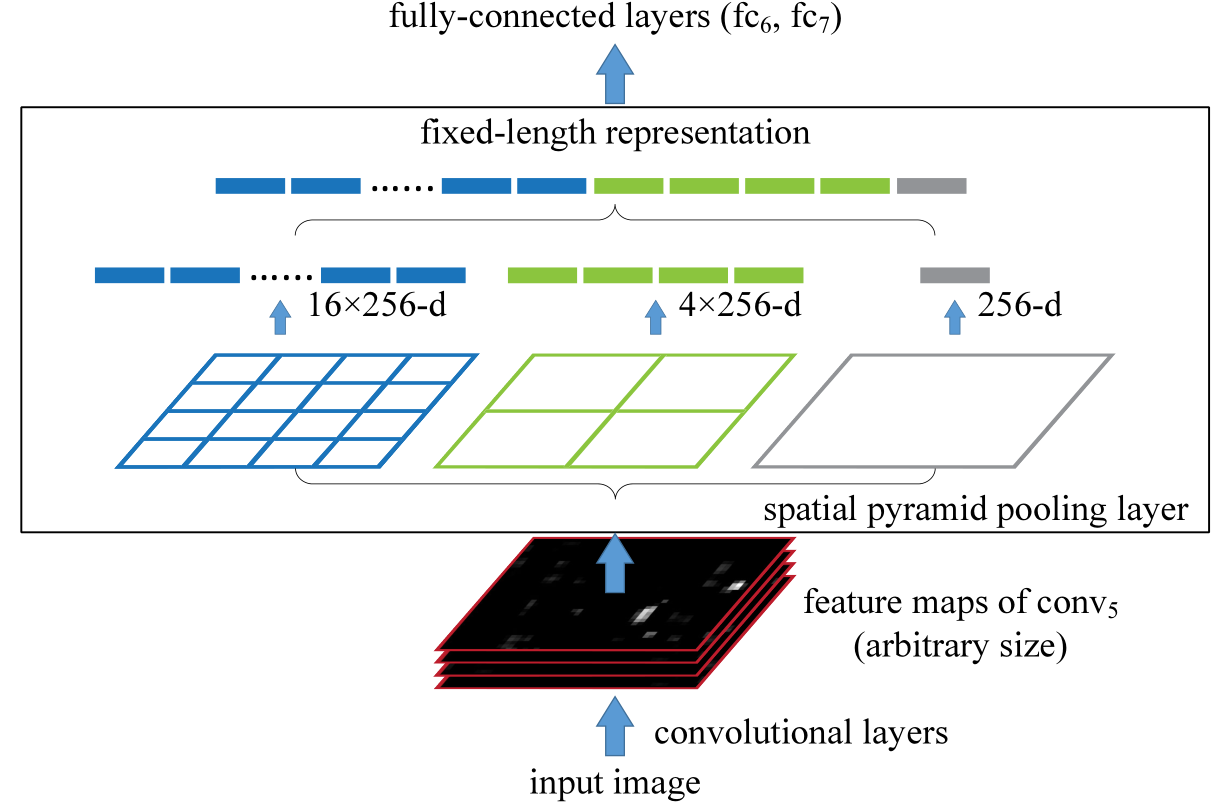
- 将conv5的特征图池化成4x4, 2x2,1x1三张子图,做max pooling后,出来的特征就是固定长度:(16+4+1)x256的维度,256是conv5最后一层滤波器数目
- 子图可以是任意的形状
网络训练
- 由于GPU优选在固定尺寸的输入图像运行,SPP-Net支持不同大小的图像,所以开发了一种简单多尺寸训练(Multi-size training)
- 对于一个可接受可变输入尺寸的网络,可以通过共享所有参数的多个网络来近似,而使用固定的输入尺寸训练这些网络中的每一个。
- 在每个epoch,使用给定的输入尺寸训练网络,下一个epoch切换到另一个输入尺寸。 这种多尺寸训练可以提高测试的准确性。
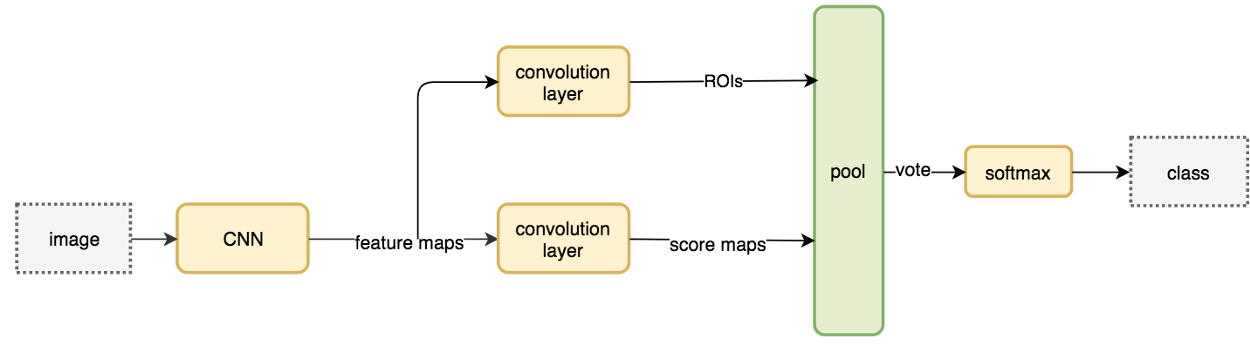
Fast R-CNN
改进
- 使用CNN直接提取特征区域
- 训练是单阶段的,可以更新网络所有层
- 多任务的损失学习:分类、边界框识别
- 不需要磁盘存储
流程
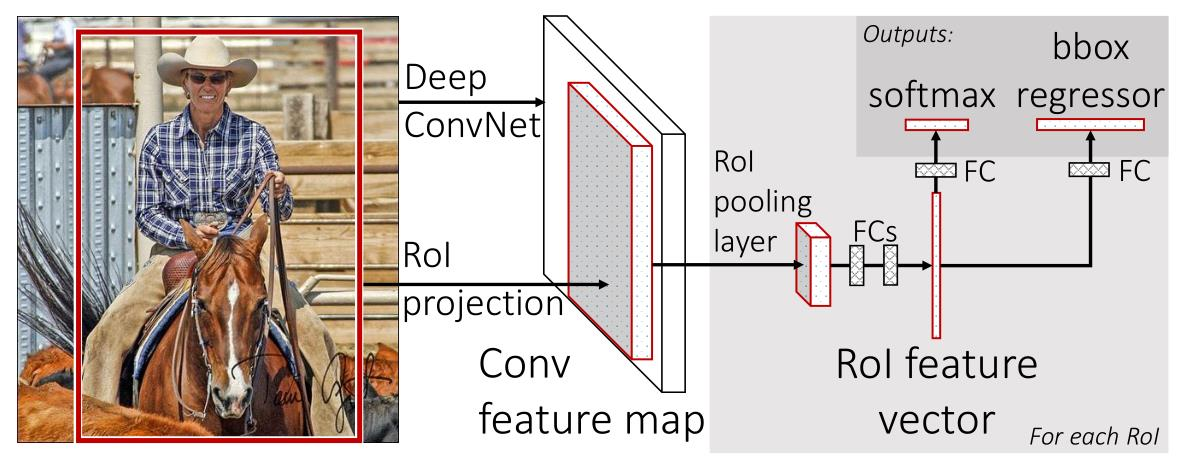
- 输入图像和多个感兴趣区域(RoI)被输入到全卷积网络中
- 每个RoI池化到固定大小的特征图中,然后通过FC 层映射到一个特征向量
- 网络每个RoI有两个输出向量:softmax概率和每个类别的边界框回归偏移
- 该架构通过多任务损失进行端到端的训练
ROI Pooling
- 原始图片经过多层卷积与池化后,得到整图的特征图。
- 而由selective search产生的大量proposal经过映射可以得到其在特征图上的映射区域RoIs,作为RoIPooling层的输入
- RoI池化层使用最大池化将任何有效感兴趣区域RoI内的特征转换为具有固定空间大小H×W(例如, 7×7)大小的特征图。方法使用SPP layer,而只用一个固定大小的bin。
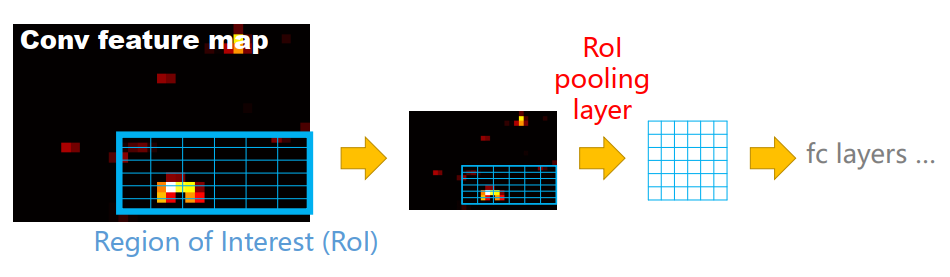
-
RoI池化层的输入将是区域建议和最后的卷积层激活。
-
ROI Pooling的问题:misalignment problem,两次精度丢失,导致物体检测框的偏移量变化被放大
- CNN之后的特征图尺寸变化,selective search尺寸需要进行放缩;
- 池化层操作时,尺寸不为偶数时,也会切的不均匀
-
解决方法:ROI Align(双线性插值)
分类、回归层
- 网络具有两个sibling输出,每个RoI的分类的离散概率分布:,和每个目标类别的边界框回归偏移。每次训练ROI会标记为类别u,和边界框v
- 损失函数:
- 交叉熵损失:
- 对outlier不敏感:
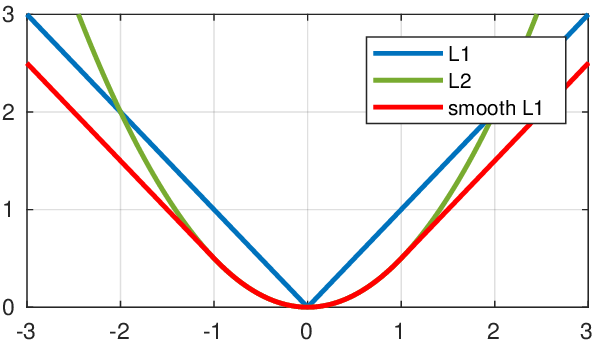
- smoothL1保持了L1在error比较大时的稳定性,L2在error比较小时的梯度
SVD加速计算
- 在检测过程中,因为要处理的RoIs较多,几乎过半的时间都耗费在FC层的计算上了,这里是用SVD分解加速FC层的计算。
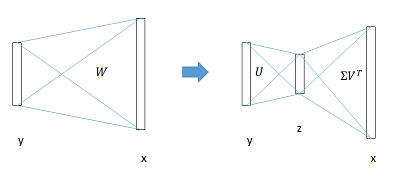
- 在加速实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。参数数量从uv减小到t(u + v),t远远小于min(u,v)
联合训练
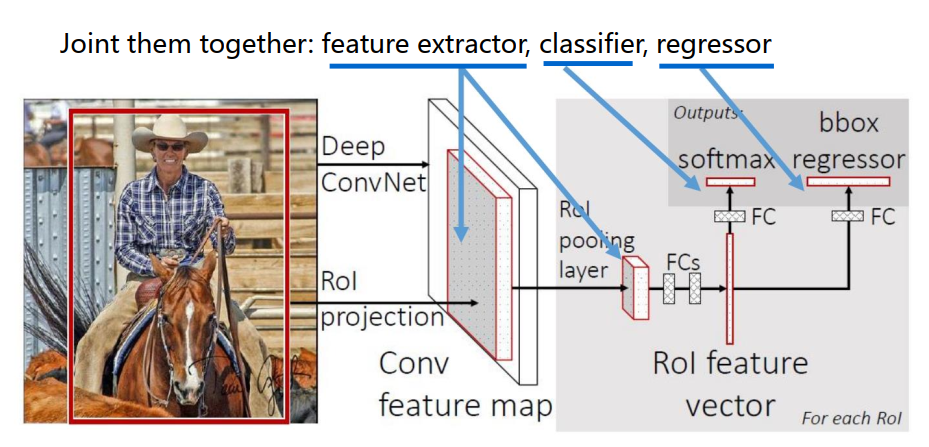
端到端训练
- 图像经过卷积神经网络得到特征图,通过选择性搜索得到区域建议ROI,做ROI池化到全连接层。
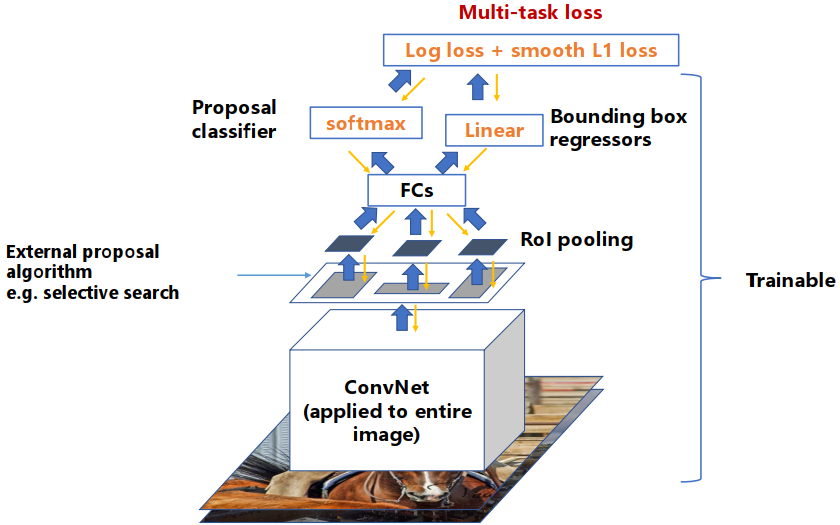
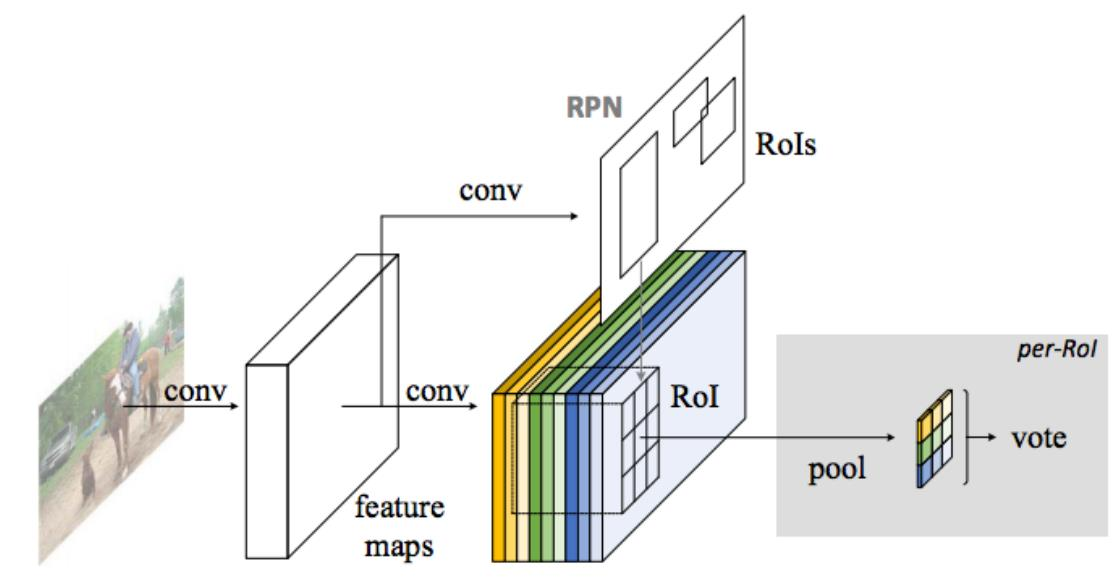
Faster R-CNN
改进
- 与Faste R-CNN的区别:使用RPN获得ROI区域,不依赖外部区域简易算法
- 可以在单个前向传播中进行目标检测
解决多尺度和多尺寸的方法
- 构建图像和特征图的金字塔,并且分类器在所有尺度上运行
- 在特征图上运行具有多个尺度/尺寸的金字塔滤波器
- 使用多个锚定框(anchor boxes)金字塔
整体流程

- RPN的输入是conv5传出的特征图像,获取分类和候选框的数据。其余和fast R-CNN一致
锚定框
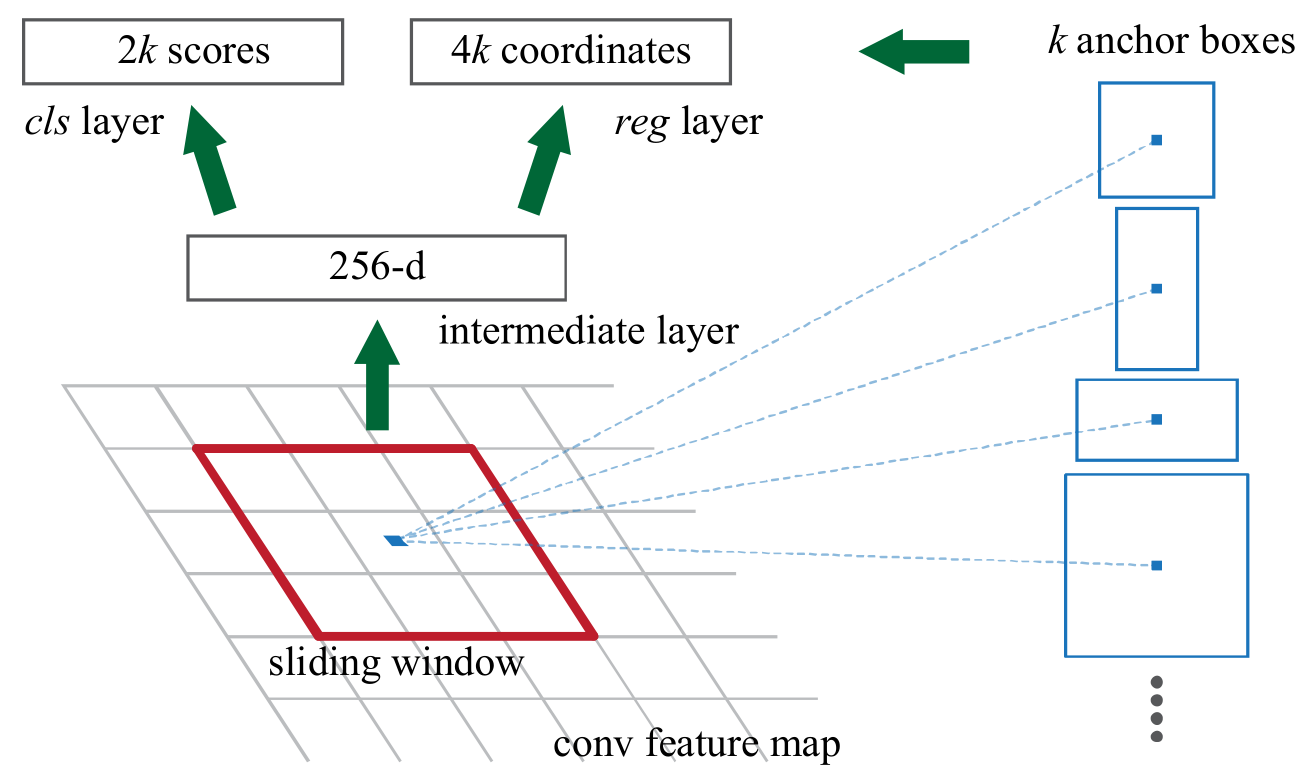
-
锚定框是固定尺寸的边界框,其放置在整个图像中并具有不同的形状和尺寸。 对于每个锚定框, RPN预测两件事情:
- 第一个是一个锚定框是某个目标的概率(不考虑目标属于哪个类别):RPN在原图尺度上设置了许多候选的Anchors。 然后用CNN去判断哪些Anchor是里面有目标的foreground anchor,哪些是没有目标的background anchor,前景和背景。所以是个二分类问题。
- 第二个是用于调整锚定框以更好地适合目标的边界框回归器:遍历通过Conv layers计算获得的特征图, 为每一个点都配备9种anchors作为初始的检测框。这样获得检测框尚不准确,后面还有2次边界框回归器可以修正检测框位置
-
在conv5_3的卷积特征图上用一个𝑛 × 𝑛的滑动窗(论文选用𝑛 = 3, 即3 × 3的滑动窗)生成一个长度为256维(对应于ZF网络)或512(对应于VGG网络)维长度的全连接特征。
-
然后在这个256维或512维的特征后产生两个分支的全连接层:
- reg-layer, 用于预测proposal的中心锚定框对应的proposal的坐标𝑥, 𝑦和宽高𝑤, ℎ;
- cls-layer,用于判定该proposal是前景还是背景。滑动窗的处理方式保证reg-layer和cls-layer关联了conv5_3的全部特征空间。
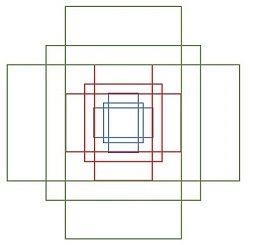
- 锚定框以滑动窗的中心为中心,并且与尺度(scale)和宽高比(aspect ratio)相关联。默认情况下,使用3个尺度和3个宽高比,在每个滑动位置产生𝑘 = 9个锚定框。对于大小为𝑊 × 𝐻(通常为〜2,400)的卷积特征图,总共有𝑊 × 𝐻 × 𝑘个锚定框。实际上通过anchors引入了检测中常用到的多尺度方法。9个矩形共有3种形状,宽高比为width:height∈{1: 1, 1: 2, 2: 1}三种。
ROI Pooling
-
得到不同形状和大小的边界框后,传递到RoI池化层,为每个锚定框提取固定大小的特征图,然后将这些特征图传递到全连接层,该层具有一个softmax层和一个线性回归层。 它最终对目标进行分类并预测已识别目标的边界框
-
ROI 池化实际上是SPP-net的一个精简版, SPP-net对每个proposal使用了不同大小的金字塔映射,而ROI池化只需要下采样到一个7x7的特征图。
-
对于VGG16网络conv5_3有512个特征图,这样所有region proposal对应了一个7×7×512维度的特征向量作为全连接层的输入。
-
RoI池化实现从原图区域映射到conv5区域,再最后池化到固定大小
训练
-
两种方法 :
- 交替优化(Alternating optimization): Presented in NIPS 2015 paper
- 近似联合训练(Approximate joint training): available in https://github.com/rbgirshick/py-faster-rcnn
-
训练目标:产生建议窗口的CNN和目标检测的CNN两者
共享特征(share features),也可以不共享 -
四个损失:RPN proposal的分类和边界框、输出的分类和边界框的误差
-
- 𝑖:anchor index in minibatch 小批次中,anchor的索引
- Pi: Predicted probability of being an object for anchor i 是目标anchor的概率
- Pi*:Ground truth objectness label
- ti*:True box coordinates
- Lreg:使用smoooth
- Lcls:是否真的目标标签,使用交叉熵损失
- ti:Coordinates of the predicted bounding box for anchor i 目标anchor的坐标
- 𝑁𝑐𝑙𝑠= Number of anchors in minibatch (~256)小批次中anchor的数量
- 𝑁𝑟𝑒𝑔= Number of anchor locations (~2400) anchor的边框数量
- 𝜆:In practice 𝜆=10, so that both terms are roughly equally balanced 加权,因为边界框和分类相差太多
Anchor正负样本
- Anchor正样本
- 与GT box有最高重叠IoU的anchor
- 与GT box重叠IoU的大于0.7的anchors
- Anchor负样本
- 与GT box重叠IoU小于0.3的anchors
- 既不是正样本也不是负样本的anchors不用于训练
四步骤交替训练(4-Step Alternating Training)
- 步骤1:使用ImageNet预训练模型训练RPN,并对区域建议任务进行端到端微调
- 步骤2:使用步骤1 RPN生成的区域建议训练Fast R-CNN
- 步骤3:使用在步骤2中训练的模型初始化RPN训练,但固定共享卷积层仅微调RPN特有的层
- 步骤4:保持共享卷积层固定,微调Fast R-CNN特有的层
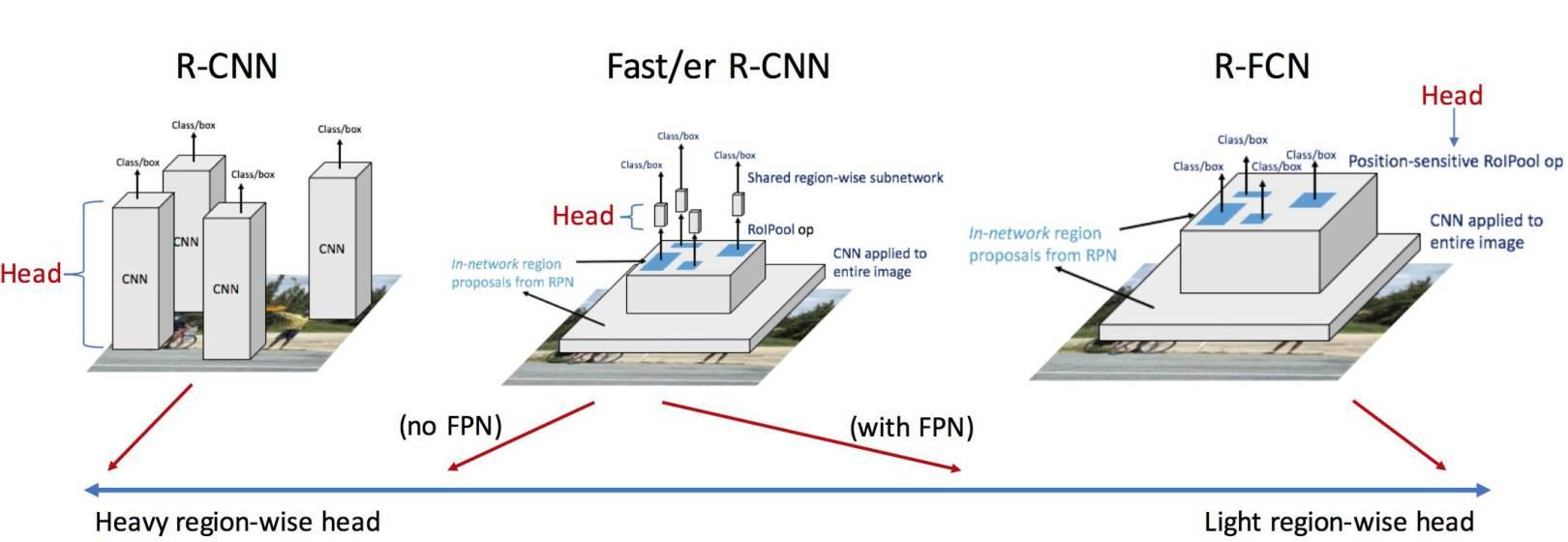
R-FCN
- R-FCN2016,主要思想是尽量将卷积共享,Faster R-CNN结构进行了改造,将RoI层之后的卷积都移到了RoI层之前,并利用一种位置敏感的特征图来评估各个类别的概率,在保持较高定位准确度的同时,大幅提高检测速率。
改进
- 解决了图像分类的平移不变性(translation-invariance in image classification)与目标检测的平移可变性(translation-variance in object detection)之间的矛盾,在提升精度的同时利用位置敏感得分图(position-sensitive score maps)提升了检测速度。
- 基于ResNet-101的R-FCN在PASCAL VOC 2007的测试集上的mAP=83.6%,速度为170ms/image。
位置敏感得分图
- Faster R-CNN检测速度慢的问题的原因:在最终卷积之前插入了RoI池化层,破坏了平移不变性。 RoI层后的结构对不同的proposal不共享, RoI后的全连接网络对每个proposal都要计算。
- 把RoI后的结构往前搬移可提升速度,但会导致RoI在conv5后的平移可变性有问题; 必须通过其他方法加强结构的可变性, R-FCN通过添加位置敏感得分图来达到这个目的,即把目标的位置信息融合进RoI pooling。
判断RoI子区域是否含有目标的相应部位

- 通过了解左眼的位置,可以知道人脸应该在哪里。
- 单个特征很少能提供如此精确的答案。 但如果有专门检测左眼、鼻子或嘴巴的其他特征图,可以将信息组合在一起, 使人脸检测更容易、更准确。
- 创建了9个(
7*7也可以)基于区域的特征图 ( region-based feature maps ),每个特征图检测目标的左上、中上、右上、中左、 …或右下区域。 通过融合这些特征图的投票(votes),可确定目标的类别和位置。
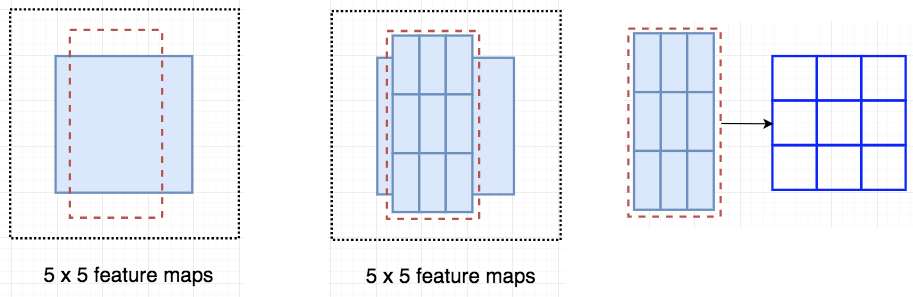
- 将得分图和RoI映射到投票矩阵的过程称为位置敏感的RoI池化
- 假设虚线红色矩形是建议的RoI。
- 将其划分为3×3区域,并询问每个区域包含目标的相应部分的可能性。
- 例如,左上角RoI区域包含左眼的可能性有多大。 将结果存储在右图中的3×3投票矩阵中。
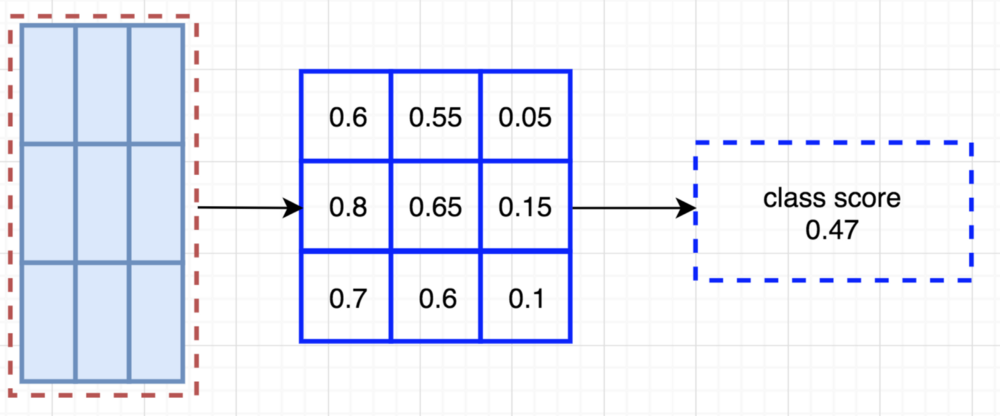
流程
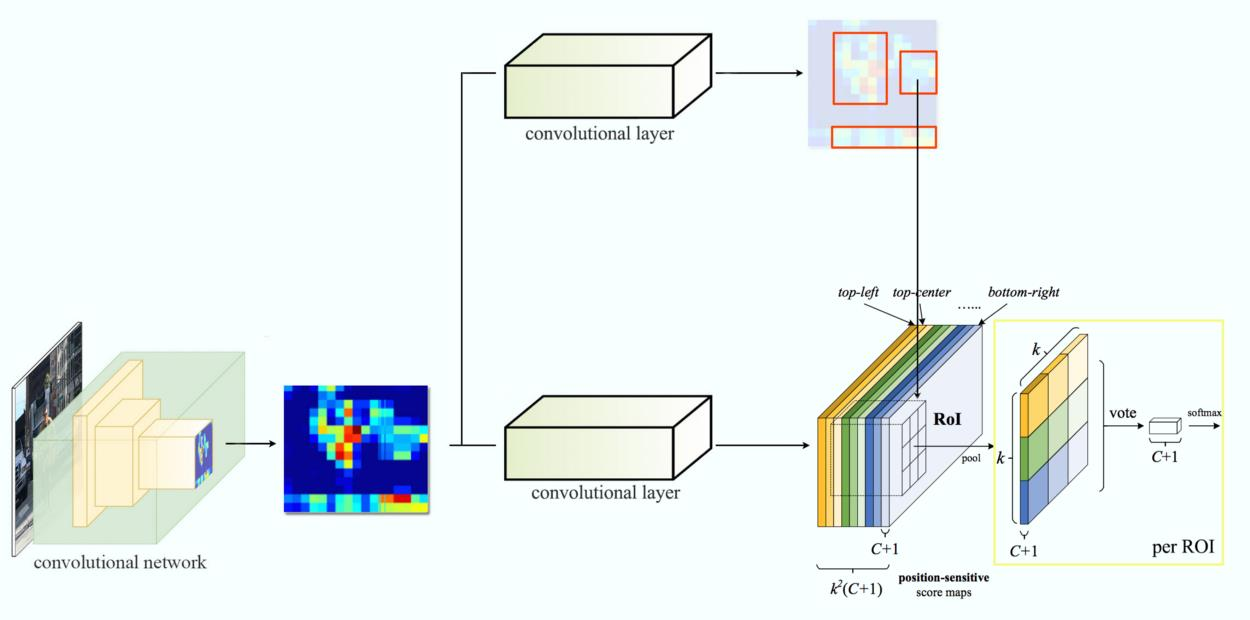
- 在该图示中,存在由全卷积网络生成的𝑘 × 𝑘 = 3 × 3位置敏感得分图
- 对于RoI中的每个𝑘 × 𝑘bins之一, 仅在𝑘 × 𝑘个映射之一(由不同颜色标记)上执行池化
- 一个RoI会分成 k×k 个bins(也就是子区域。每个子区域bin的长宽分别是ℎ/𝑘和𝑤/𝑘),每个bin都对应到score map上的某一个区域
- 池化操作就是在该bin对应的score map上的子区域执行,执行的是平均池化
- ResNet-101有100个卷积层,后面是全局平均池化层(global average pooling, GAP)和一个1000类别的fc层。
- 删除GAP层和fc图层,仅使用卷积层来计算特征图。
- ResNet-101在ImageNet上进行预训练。 ResNet-101中的最后一个卷积块是2048-d,附加一个随机初始化的1024-d 1×1卷积层以降低维数。
- 然后使用𝑘2 𝐶 + 1 个通道的卷积层来生成得分图。
标准目标检测多任务损失函数
-
- Lcls:交叉熵损失
- Lreg:回归损失
- c^*>0:如果是背景,则为零
-
正负样本
- 从RoI形成的正样本,具有与GT box至少0.5的IoU重叠,否则为负样本
在线困难样本挖掘
- Online Hard Example Mining during training
- 假设每个图像有𝑁个proposals,在前向传播中,评估所有𝑁个proposals的loss。 然后按损失对所有RoI(正样本和负样本)进行排序,并选择损失最大的𝐵个RoIs。
- 基于所选的样本执行反向传播。因为R-FCN中每个RoI计算可以忽略不计,所以前向时间几乎不受𝑁的影响,而Fast R-CNN相比会使训练时间加倍。
带孔卷积Atrous Convolution
- 将ResNet-101的有效步幅从32像素降低到16像素,从而提高了得分图的分辨率。
- Conv4和之前的所有层(stride = 16)都保持不变; 将第一个conv5中的stride = 2修改为stride = 1
- Conv 5的所有卷积滤波器都通过“带孔算法”(Algorithme à rous)进行修改,以补偿减小的步幅。
YOLO-v1
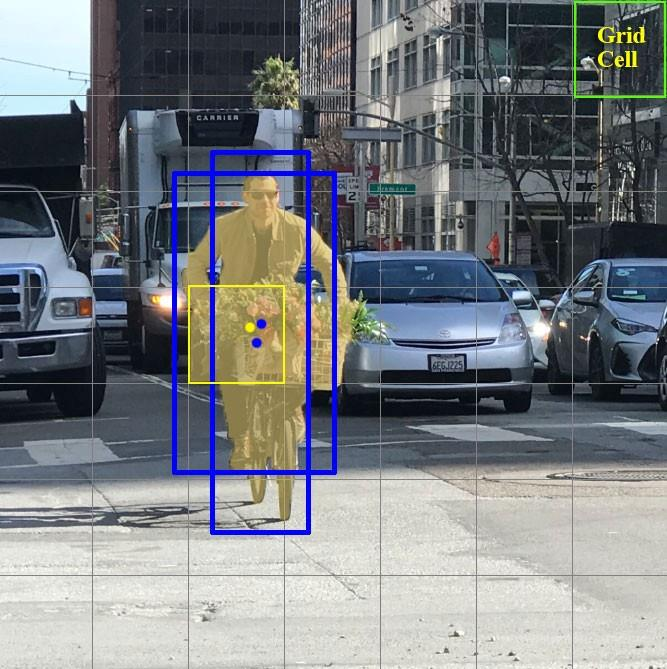
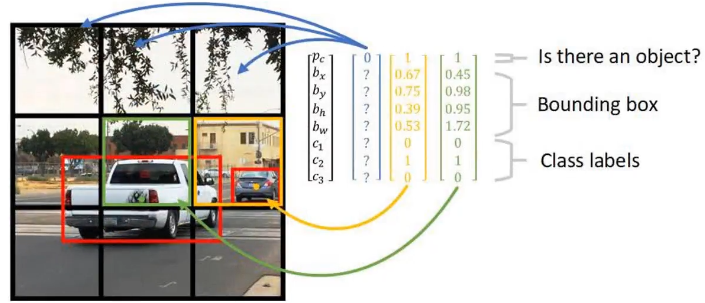
- YOLO-v12016,You Only Look Once,YOLO将全图划分为S×S(7x7)的格子, 每个格子负责对落入其中的目标进行检测,一次性预测所有格子所含目标的边界框、定位置信度、以及所有类别概率向量。

流程
网格单元Grid cell
- YOLO将输入图像分成S×S网格。 每个网格单元仅预测一个目标。
- 每个网格单元预测固定数量的边界框。在此示例中,黄色网格单元格进行两个边界框预测(蓝色框)以定位人的位置
-
预测B个边界框,每个框计算一个框置信度得分,只检测一个目标而不管边界框B的数量
-
预测C个条件类别概率(conditional class probabilities),对于可能的目标类别,每个类别预测一个值
-
每个边界框包含5个元素:(x, y, w, h)和一个框置信度得分。
-
框置信度得分(box confidence score)反映了框包含一个目标的可能性(objectness )以及边界框的准确程度。
-
将边界框宽度w和高度h用图像宽度和高度归一化。 x和y是相应单元格的偏移量。 因此, x, y, w和h都在0和1之间。
-
每个单元格有20个条件类别概率。 条件类别概率( conditional class probability )是检测到的目标属于特定类别的概率(每个单元的每个类别有一个概率)。
-
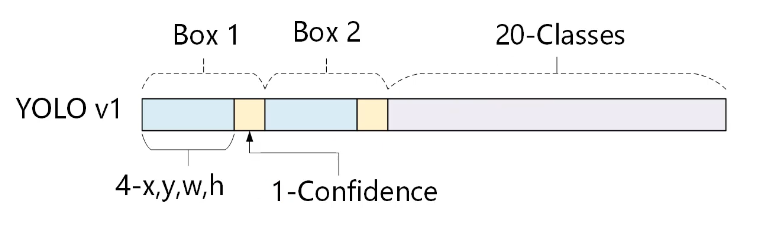
So, YOLO’s prediction has a shape of (S, S, B×5 + C) = (7, 7, 2×5 + 20) = (7, 7, 30).
-
系统将检测模型作为回归问题。 将图像划分为𝑆 × 𝑆网格,并且每个网格单元预测𝐵个边界框,框的置信度和𝐶类别概率。 这些预测被编码为𝑆 × 𝑆 × (𝐵 × 5 + 𝐶) 的张量。
-
为了评估PASCAL VOC,使用𝑆 = 7, 𝐵 = 2。 PASCAL VOC有20个类别标记,因此𝐶 = 20。最终预测是7 × 7 ×30的张量。
网络结构

- YOLO有24个卷积层,后面是2个全连接的层(FC)。
- 一些卷积层交替使用1×1的reduction层以减少特征图的深度。 对于最后一个卷积层,它输出一个形状为(7,7,1024)的张量。然后张量展开。 使用2个全连接的层作为一种线性回归的形式,它输出7×7×30个参数,然后重新塑形为(7,7,30)。
流程
类别置信度得分
- 类别置信度=条件类别概率*框置信度得分:
- Pr(object):box包含目标的概率
- IoU:预测和真实的概率
- Pr(classi|object):条件类别的概率
损失函数
-
YOLO每个网格单元预测多个边界框。为了计算true positive的损失,只希望其中一个框负责该目标。为此,选择与GT具有最高IoU的那个框。
-
YOLO使用预测值和GT之间的误差平方的求和来计算损失。 损失函数包括:
-
分类损失
-
定位损失(预测边界框与GT之间的误差)
-
置信度损失(框的目标性)
-
分类损失:如果检测到目标,则每个单元格的分类损失是每个类别的条件类别概率的平方误差,
- :目标出现在单元格cell则为1,否则为0
- :denotes the conditional class probability for class c in cell i.
-
定位损失:定位损失测量预测的边界框位置和框大小的误差。 只计算负责检测目标的框,
- 不希望在大框和小框中同等地加权绝对误差。 即不认为大框中的2像素误差对于小框是相同的。
- 为了部分解决这个问题, YOLO预测边界框宽度和高度的平方根,而不是宽度和高度。 另外,为更加强调边界框的精度,将损失乘以𝜆𝑐𝑜𝑜𝑟𝑑(默认值:5)
-
置信度损失:
- 如果在框中检测到目标,则置信度损失:
- 如果在框中没有检测到目标,则置信度损失为:
- 大多数框不包含任何目标。 这导致类不平衡问题,即训练模型时更频繁地检测到背景而不是检测目标。为了解决这个问题, 将这个损失用因子𝜆𝑛𝑜𝑜𝑏𝑗(默认值: 0.5)降低。
-
损失函数是上面三个损失之和。
非最大抑制
- YOLO可能对同一个目标进行重复检测。 为了解决这个问题, YOLO采用非最大抑制来消除置信度较低的重复。非最大抑制可以增加2~3%的mAP。
- 可能的非最大抑制实现之一:
- 按置信度分数对预测进行排序
- 从最高分开始,如果发现任何先前的预测具有相同的类别并且当前预测的IoU> 0.5,则忽略当前预测
- 重复步骤2,直到检查完所有预测
优缺点
-
处理速度快,45fps,可以实时处理
-
预测目标位置和类别由单个网络完成。 可以端到端训练以提高准确性。
-
YOLO更加一般化。 当从自然图像推广到其它领域(如艺术图像)时,它优于其他方法。
-
对小目标及邻近目标检测效果差:当一个小格中出现多于两个小目标或者一个小格中出现多个不同目标时效果欠佳。
-
原因:B表示每个小格预测边界框数,而YOLO默认落入同一格子里的所有边界框均为同种类的目标。
YOLO-v2
- YOLO-v22017,YOLOv2是YOLO的第二个版本,其目标是在提高速度的同时显著提高准确度。与基于proposal的检测器相比, YOLOv1定位误差更高, 并且召回率(测量所有目标的定位有多好)更低。
- SSD是YOLOv1的强大竞争对手,它在某一方面表现出更高的实时处理精度
改进
-
提出了一种目标分类与检测的联合训练方法,通过WordTree来混合检测数据集与识别数据集之中的数据,同时在COCO和ImageNet数据集中进行训练得到YOLO9000,实现9000多种目标的实时检测。
-
使用批归一化(Batch Normalization) 提高准确度
-
高分辨率分类器(High-resolution classifier )
-
用锚定框的卷积(Convolutional with Anchor Boxes)
-
维度聚类(Dimension Clusters)
-
直接位置预测(Direct Location Prediction)
-
更精细的特征(Fine-Grained Features)
-
多尺度训练(Multi-Scale Training)
-
Dataset combination with WordTree
-
Darknet-19网络模型
-
Joint classification and detection
流程
高分辨率分类器
-
所有State-Of-The-Art的检测方法都在ImageNet上对分类器进行了预训练。从AlexNet开始,多数分类器都把输入图像Resize到256x256以下,这会容易丢失一些小目标的信息。
-
YOLOv1训练由两个阶段组成。 首先,训练像VGG16这样的分类器网络。 然后用卷积层替换全连接层,并端到端地重新训练以进行目标检测。 YOLOv1先使用224x224的分辨率来训练分类网络,在训练检测网络的时候再切换到448x448的分辨率,这意味着YOLOv1的卷积层要重新适应新的分辨率,同时YOLOv1的网络还要学习检测网络。
-
YOLOv2 以224×224图片开始用于分类器训练,但是然后使用更少的epoch再次用448×448图片重新调整分类器。让网络可以调整滤波器来适应高分辨率, 这使得检测器训练更容易。 使用高分辨率的分类网络提升了将近4%的mAP。
用锚定框的卷积
-
YOLO论文指出:早期训练容易受到不稳定梯度的影响。最初, YOLO对边界框进行任意猜测。 这些猜测可能对某些目标有效,但对其他目标则很糟糕,导致陡峭的梯度变化。在早期训练中,预测在相互争论什么样的特定形状合适。
-
YOLOv1使用全连接层数据进行边界框预测(要把1470×1的全连接层reshape为7×7×30的最终特征),这会丢失较多的空间信息而定位不准。
-
YOLOv2借鉴了Faster R-CNN中的Anchor思想:简单理解为卷积特征图上进行滑动窗采样,每个中心预测9种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个Cell一一对应。由于预测层是卷积, 所以RPN预测offset是全局性的。预测offset值而不是坐标值简化了实际问题,并且更便于网络学习。
-
总的来说就是移除全连接层(以获得更多空间信息) 使用锚定框来预测Bounding boxes
-
具体做法如下:
- 去掉最后的池化层确保输出的卷积特征图有更高的分辨率。
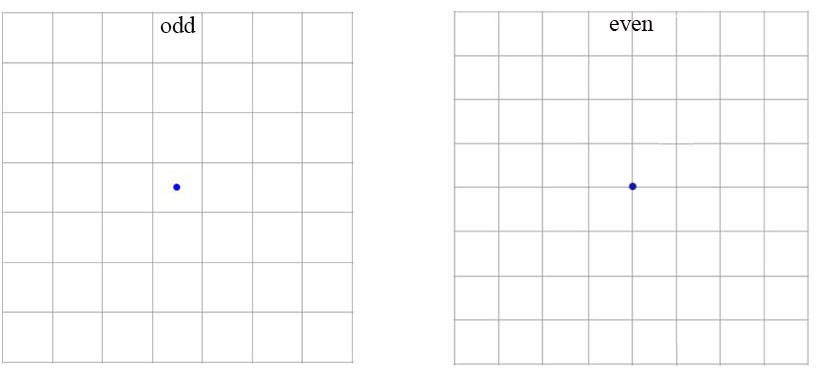
- 缩减网络,让图片输入分辨率为416x416,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个Center Cell。对于一些大目标, 它们中心点往往落入图片中心位置,此时使用特征图的一个中心点的cell去预测这些目标的边界框相对容易些,否则就要用中间的4个Cells来进行预测。这个技巧可稍稍提升效率,所以在YOLOv2设计中要保证最终的特征图有奇数个位置。
- 使用卷积层降采样(factor 为32),使得输入卷积网络的416×416图片最终得到13 ×13的卷积特征图(416/32=13)
-
将输入图像大小从448×448更改为416×416。这将创建奇数空间维度(7×7 v.s. 8×8 grid cell)。 图片的中心通常被大目标占据。 对于奇数网格单元,可以更确定目标所属的位置。
-
为了生成形状为7×7×125的预测,用三个3×3卷积层替换最后一个卷积层,每个有1024个输出通道。 然后用最终的1×1卷积层将7×7×1024输出转换为7×7×125。
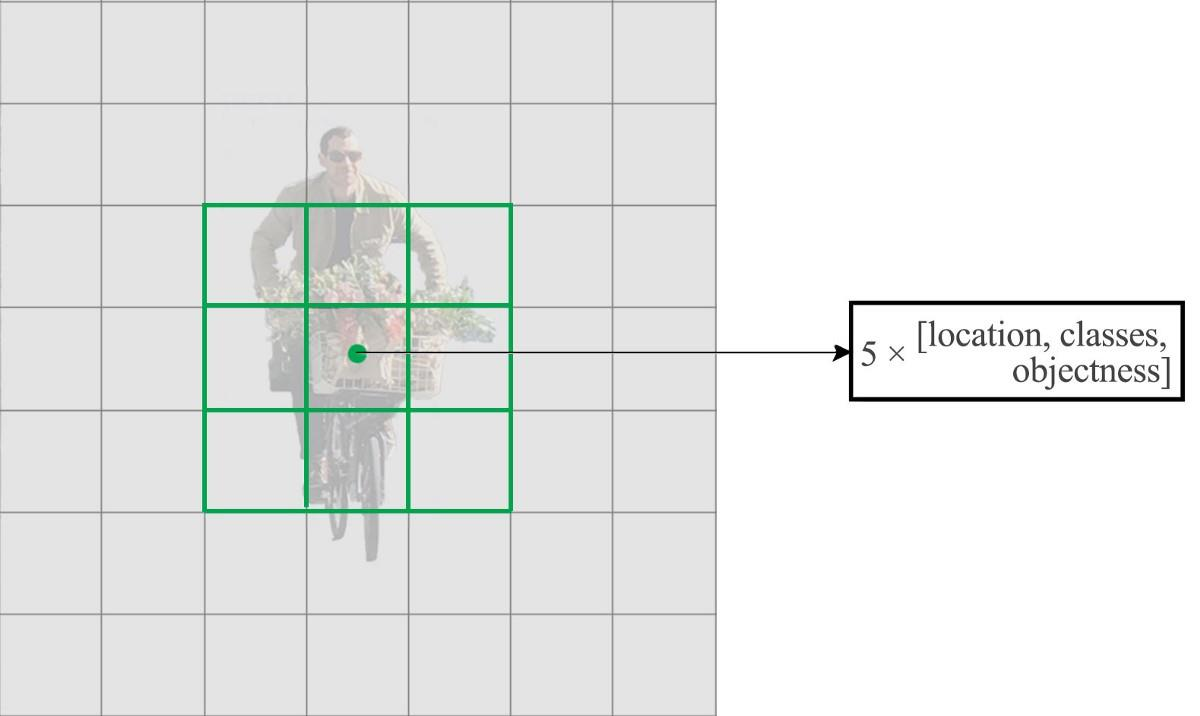
- 删除一个池化层,使网络的空间输出可变为13×13(而不是7×7)
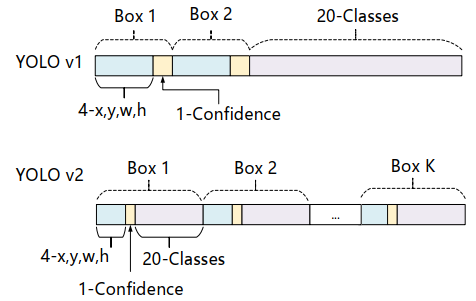
- 把预测类别的机制从空间位置(Cell)中解耦,由Anchor Box同时预测类别和坐标。
- YOLO v1是由每个Cell来负责预测类别,每个Cell对应的2个Bounding Box 负责预测坐标(YOLOv1中最后输出7×7×30的特征,每个Cell对应1×1×30,前10个主要是2个Bounding Box用来预测坐标,后20个表示该Cell在假设包含目标的条件下属于20个类别的概率)。
- YOLOv2中,不再让类别的预测与每个Cell(空间位置)绑定一起,而是全部放到Anchor Box中。上面是特征维度示意图(仅作示意并非完全正确)
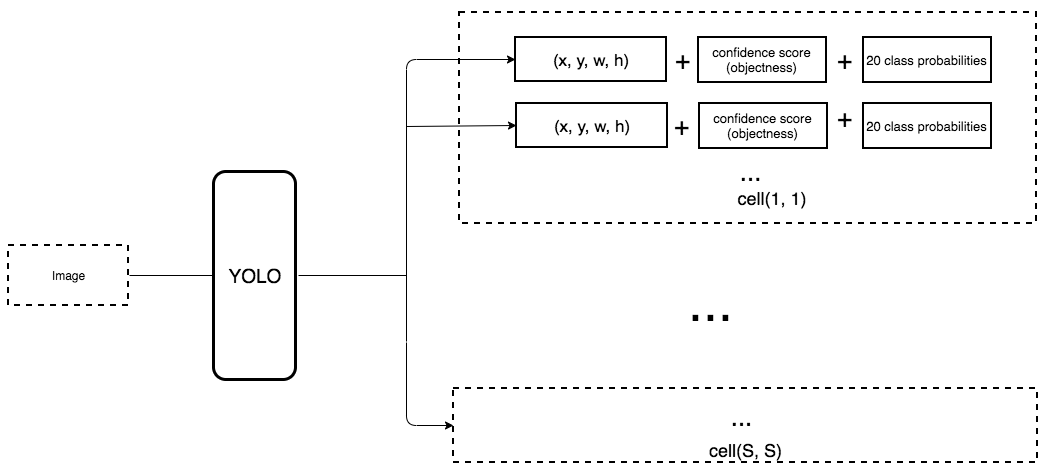
-
将类别预测从cell级别转移到边界框级别。 现在,每个预测包括边界框的4个参数, 1个框置信度得分(objectness)和20个类别概率。 即具有25个参数的5个边界框:每个网格单元(grid cell) 有125个参数。
-
与YOLO相同, objectness预测仍然预测GT框和建议框的IOU。
-
锚定框将mAP从69.5略微降低至69.2,但召回率从81%提高到88%。 准确度稍微降低,
但它增加了检测所有GT 目标的机会。 -
YOLOv1只能预测98个边界框( 7×7×2 )
-
YOLOv2使用anchor boxes之后可以预测上千个边界框(13×13×9=1521)。所以使用anchor boxes之后, YOLOv2的召回率大大提升,由原来的81%升至88%。mAP略微较低,从69.5到69.2,召回率从81%到88%。它增加了检测所有GT目标的机会。
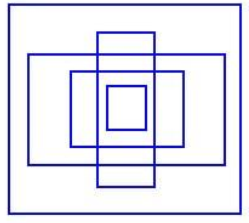
- 例如,可以创建5个具有以下形状的锚定框。预测每个锚定框的偏移量,而不是预测5个任意的边界框。 如果约束偏移值,可以保持预测的多样性,并使每个预测集中在特定的形状上。 因此,初始训练将更加稳定。
维度聚类
- 使用Anchor时,作者发现Faster-RCNN中锚定框的个数和宽高维度往往是手动挑选的先验框(Hand-PickedPriors),设想能否一开始就选择了更好的、更有代表性的先验框维度,那么网络就应该更容易学到准确的预测位置
- 解决办法就是统计学习中的K-means聚类方法,通过对数据集中的GT Box做聚类,找到GT Box的统计规律。以聚类个数𝑘为锚定框个数,以𝑘个聚类中心Box的宽高维度为宽高的维度。
- 如果按照标准K-means使用欧式距离函数,大框比小框产生更多误差。但是,我们真正想要的是使得预测框与GT框的有高的IOU得分,而与框的大小无关。因此采用了如下距离度量,即聚类分析时选用box与聚类中心box之间的IOU值作为距离指标
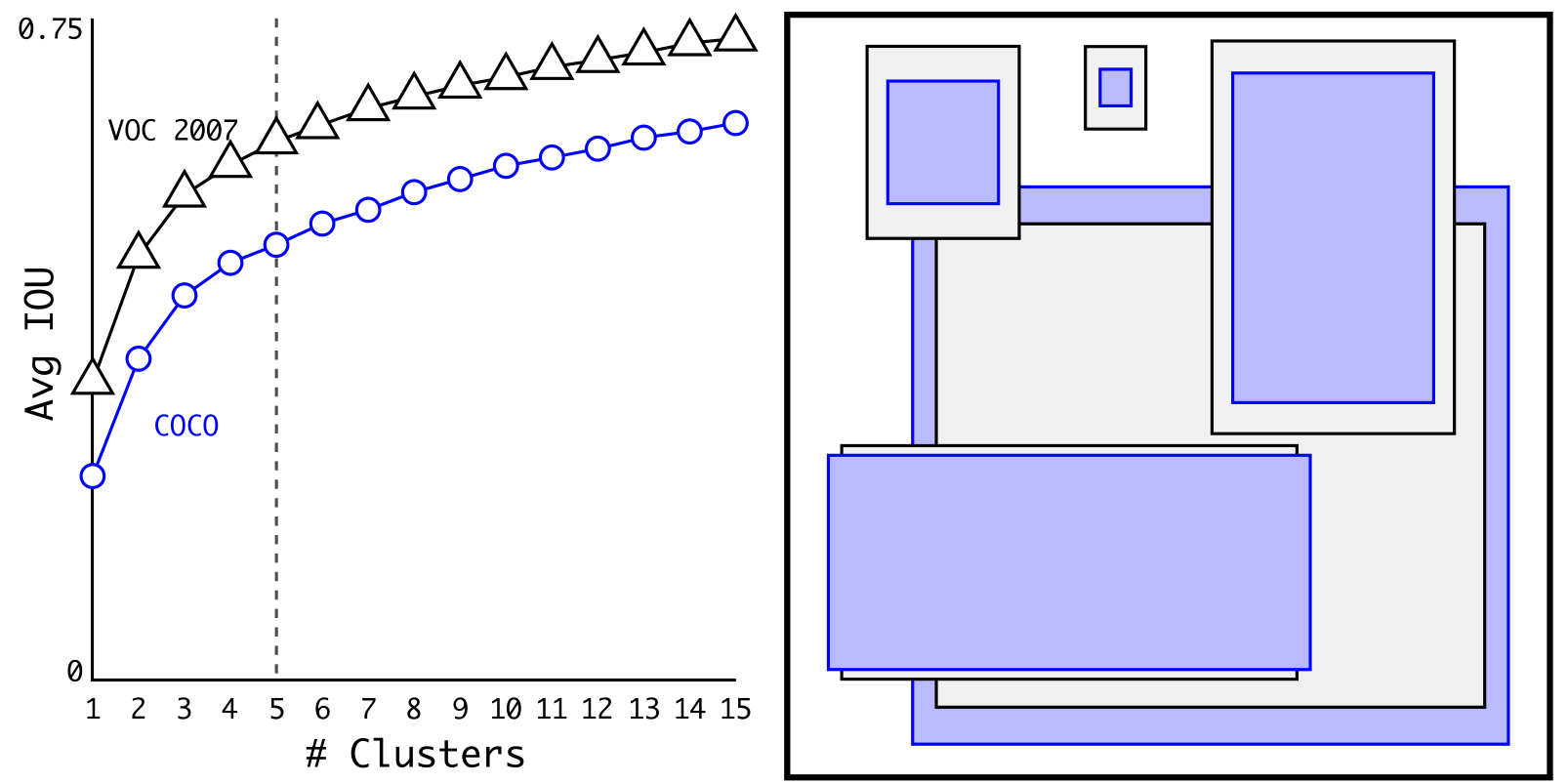
- 上面左图:随着𝑘的增大, IOU也在增大(高召回率),但是复杂度也在增加。所以平衡复杂度和IOU之后,最终得到𝑘值为5。
- 上面右图: 5个聚类的中心与手动挑选的框是不同的,扁长的框较少,瘦高的框较多。作者文中的对比实验说明了K-means方法的生成的框更具有代表性,使得检测任务更容易学习。
直接位置预测
- 引入Sigmoid函数预测offset,解决了anchor boxes的预测位置问题,采用了新的损失函数
- 作者借鉴了RPN网络使用的锚定框去预测边界框相对于图片分辨率的offset,通过(x,y,w,h)四个参数去确定锚定框的位置,但是这样在早期迭代中x,y会非常不稳定,因为RPN是一个区域预测一次,但是YOLO中是169个gird cells一起预测,处于一个gird cell 的x,y可能会跑到别的gird cell中,导致不稳定。
- 作者巧妙的应用了sigmoid函数来规约x,y的值在(0,1)轻松解决了这个offset的问题。关于w,h的也改进了YOLOv1中误差平方的计算方法,用了RPN中的log函数。
- YOLOv2沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值。
- 为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内。
- 总结来看,根据边界框预测的4个offsets 𝑡𝑥 ,𝑡𝑦 ,𝑡𝑤 ,𝑡ℎ ,可以按如下公式计算出边界框实际位置(坐标值)和大小:
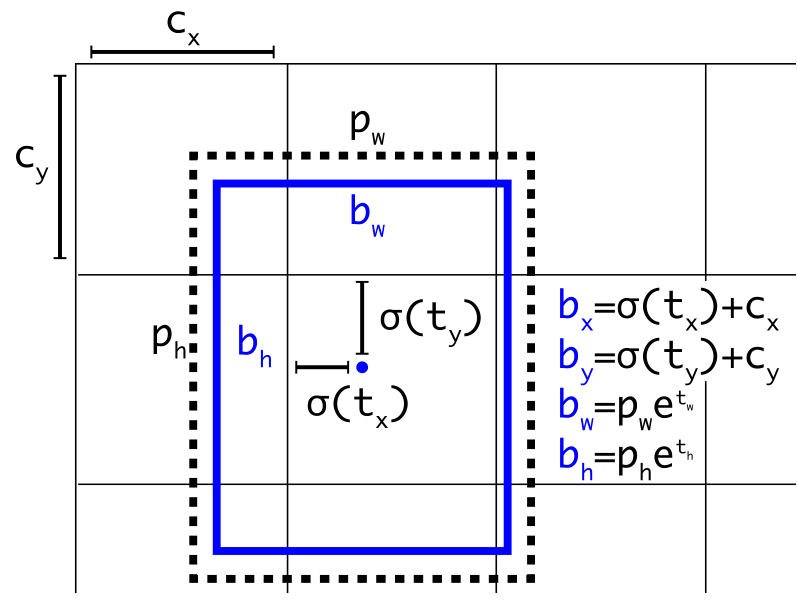

-
sigmoid函数,限制x,y
-
-
-
-
最终,网络在特征图(13×13 =169) 的每个Cell上预测5个边界框(开始是9个,kmeans后变为5个),每一个边界框预测5个值: 𝑡𝑥,𝑡𝑦,𝑡𝑤,𝑡ℎ,𝑡𝑜 ,其中前四个是坐标, 𝑡𝑜是置信度。
-
如果这个Cell距离图像左上角的边距为(𝑐𝑥,𝑐𝑦)以及该Cell对应的边界框先验维度(Bounding Box Prior)的宽和高分别为(𝑝𝑤,𝑝ℎ):
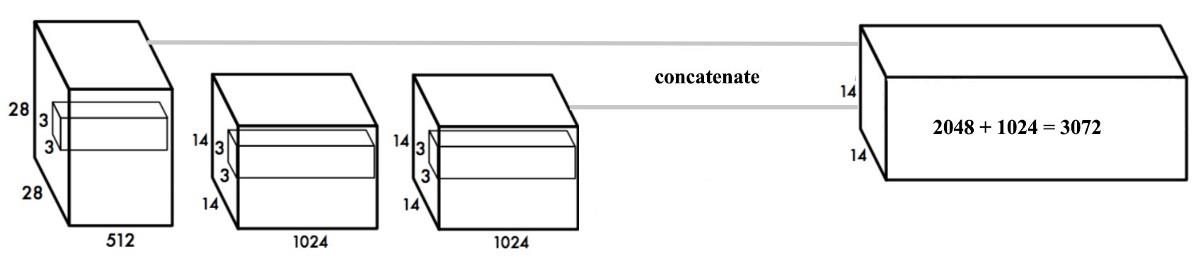
更细粒度的特征
- 卷积层逐渐减小空间维度。 随着相应的分辨率降低,检测小目标变得更加困难。 其他目标检测器(如SSD)可以从不同的特征图层中找到目标。 所以每一层都专注于不同的尺度。
- YOLO采用了一种称为passthrough的不同方法。 它将28×28×512层重整形为14×14×2048。然后将其与原始的14×14×1024输出层连接。 在新的14×14×3072层上应用卷积滤波器来进行预测。
- YOLOv2的检测器使用的就是经过扩展后的的特征图,它可以使用细粒度特征,使得模型的性能获得了1%的提升
多尺度训练
- 由于YOLOv2模型移除全连接层后只有卷积层和池化层,所以YOLOv2的输入可以不限于 416×416 大小的图片。
- 为了增强模型的鲁棒性, YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的迭代(iterations)之后改变模型的输入图片大小。由于YOLOv2的为32倍下采样,输入图片大小选择一系列为32倍数的值: {320, 352,…, 608} ,输入图片最小为 320×320 ,此时对应的特征图大小为 10 × 10 ;而输入图片最大为 608 × 608 ,对应的特征图大小为 19 × 19 。
- 在训练过程,每隔10个迭代(iterations)随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。
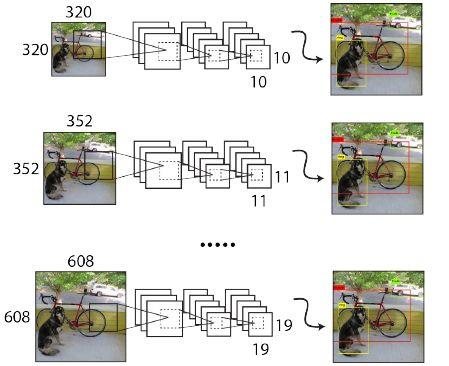
- 另外,可以使用较低分辨率的图像进行目标检测,但代价是准确度。 这对于低GPU设备的速度来说是一个很好的权衡。
- 在288×288时, YOLO的运行速度超过90FPS,mAP几乎与Fast R-CNN一样好。 在高分辨率下,YOLO在VOC 2007上实现了78.6 mAP。
Darknet-19
- YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个max pooling层。

- Darknet-19与VGG16模型设计原则是一致的,主要采用 3×3 卷积,采用 2×2 的最大池化层之后,特征图维度降低2倍,而同时将特征图的通道增加两倍。
- 与NIN(Network in Network)类似, Darknet-19最终采用global avg pooling做预测,并且在 3×3 卷积之间使用 1×1 卷积来压缩特征图通道以降低模型计算量和参数。
- Darknet-19每个卷积层后面同样使用了batch norm层以加快收敛速度,降低模型过拟合。
- 在ImageNet分类数据集上, Darknet-19的top-1准确度为72.9%, top-5准确度为91.2%,但是模型参数相对小一些。
- 使用Darknet-19之后, YOLOv2的mAP值没有显著提升,但是计算量却可以减少约33%
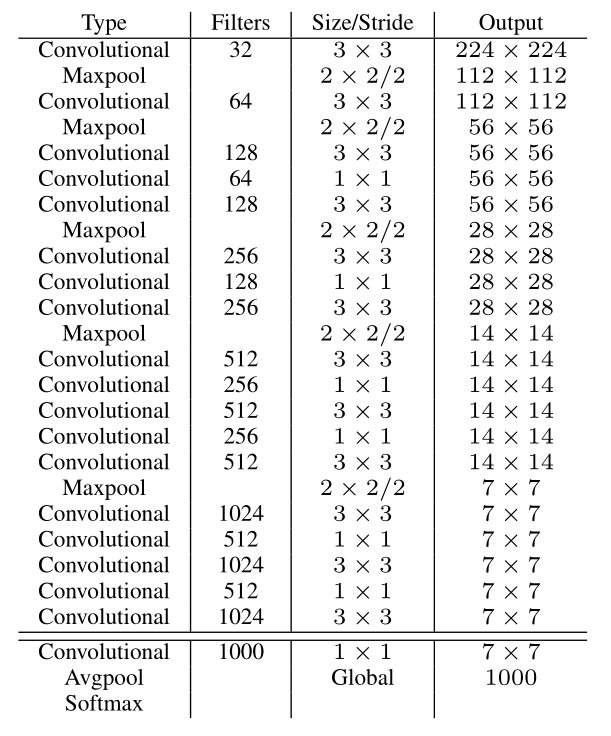
- Darknet-19网络结构,包括19个卷积层和5个max pooling层。
- 采用global avg pooling+Softmax做预测
训练
- YOLOv2的训练主要包括三个阶段:
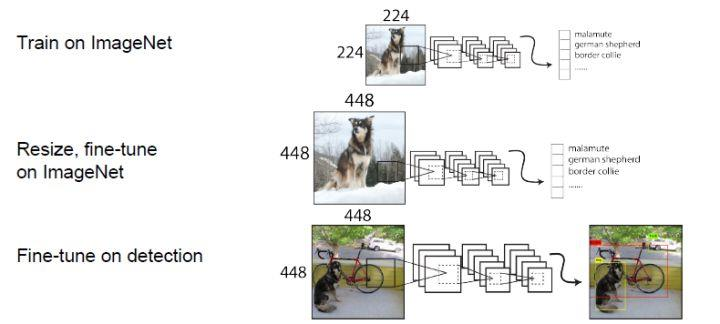
- 第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224×224 ,共训练160个epochs。
- 然后第二阶段将网络的输入调整为 448 × 448 ,继续在ImageNet数据集上微调分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
- 第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续微调网络。
WordTree
- 作者选择在COCO和ImageNet数据集上进行联合训练,但是遇到的第一问题是两者的类别并不是完全互斥的,比如“Norfolk terrier” 明显属于“dog” ,所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree。
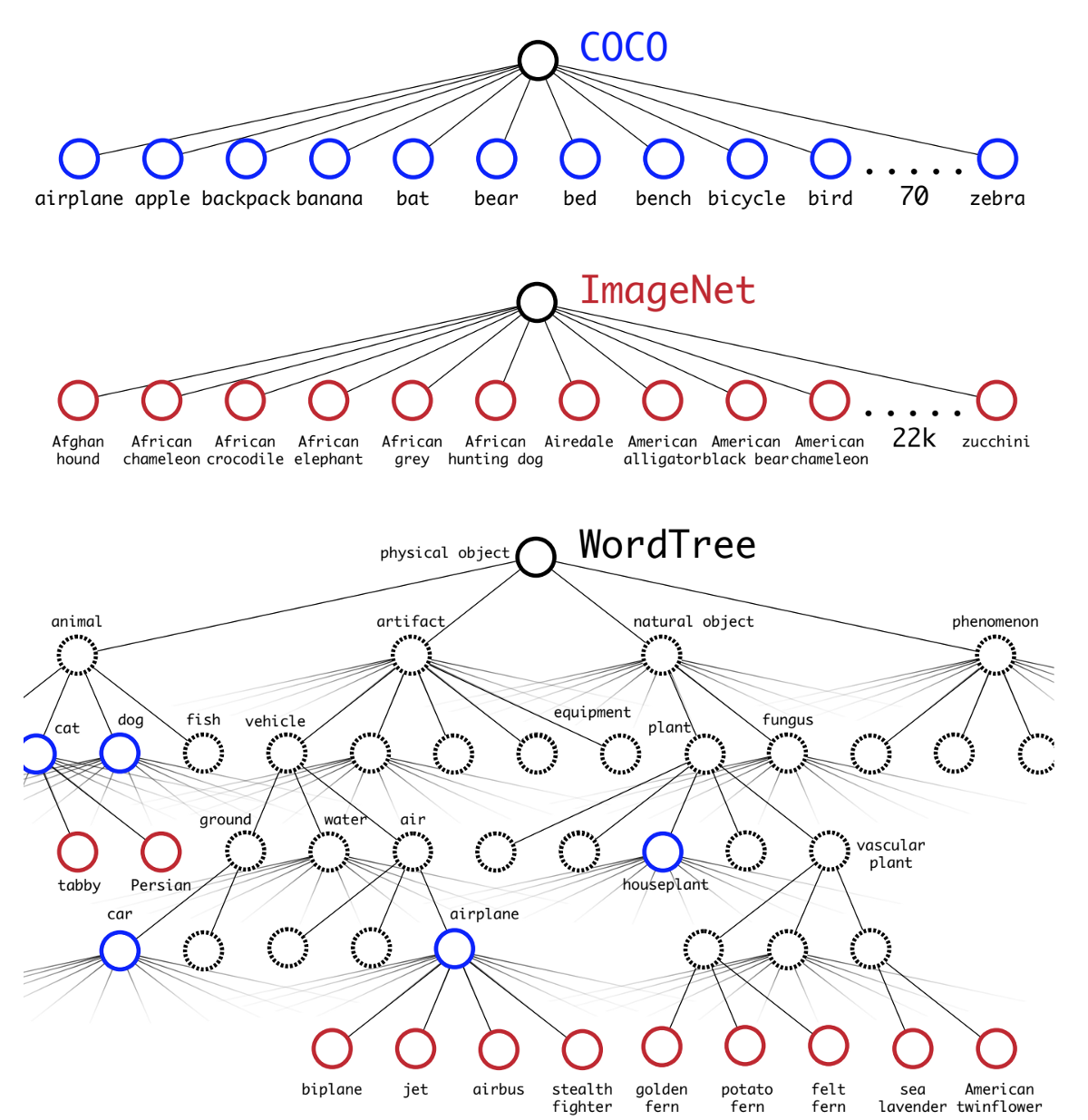
- 作者使用WordTree把多个数据集整合在一起。只需要把数据集中的类别映射到树结构中的同义词集合(Synsets)。
- WordTree中的根节点为"physical object",每个节点的子节点都属于同一子类,可以对它们进行softmax处理。在给出某个类别的预测概率时,需要找到其所在的位置,遍历这个path,然后计算path上各个节点的概率之积。
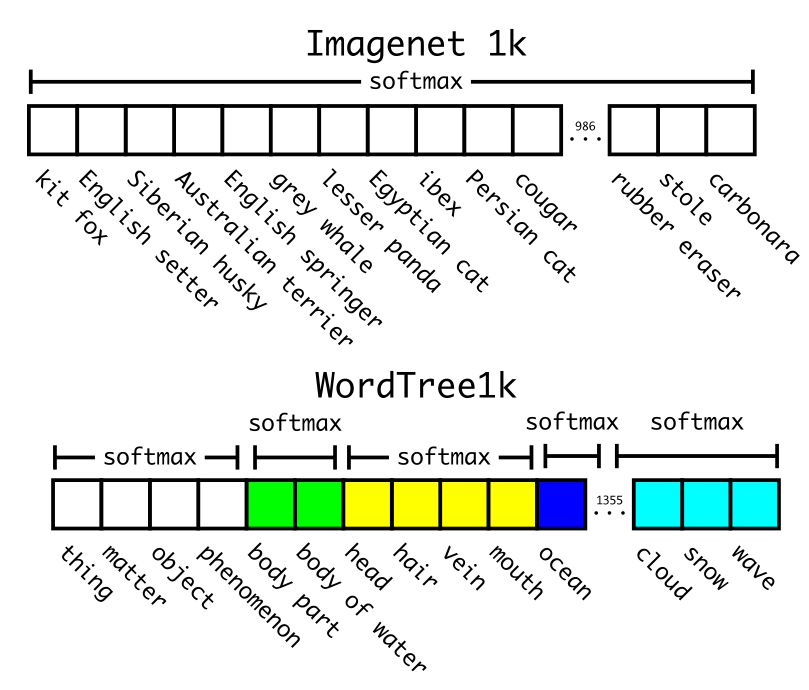
- 大多数ImageNet模型使用一个大的softmax来预测概率分布。使用WordTree,在co-hyponyms上执行多个softmax操作。
- “玫瑰”是“花”的一个下义词(hyponym);被包括在同一个上义词项内的词项称作同下义词(co-hyponyms),如被包括在上义词“花”之内的“玫瑰、牡丹、水仙、腊梅”等是同下义词。
联合分类和检测
- YOLO9000扩展YOLO以检测超过9000个类别的目标,使用了9418节点WordTree的分层分类方法。它结合了COCO的样本和ImageNet的前9000个类别。
- YOLO为每个COCO数据采样四个ImageNet数据。 它学习使用COCO中的检测数据查找目标,并使用ImageNet样本对这些目标进行分类。
- 采用这种联合训练, YOLO9000从COCO检测数据集中学习如何在图片中寻找目标,从ImageNet数据集中学习更广泛的目标分类。
- 通过联合训练策略, YOLO9000可以快速检测出超过9000个类别的目标, 总体mAP值为19.7%。
YOLO-v3
- YOLO-v32018,YOLO-v3是单阶段的目标检测方法,使用端到端的方法。检测速度非常快,精度与RetinaNet相当,速度是其4倍
改进
流程
基本思路
- 基本思想是将图片划分为网格grid,得到框和置信度,以及类别位置概率图,结合为最终结果。
- 首先通过特征提取网络,得到固定大小的特征图,然后将输入图像分为girdcell,如果GT中某个目标的中心坐标落在那个gridcell,就有该gridcell来预测目标。每个gridcell都会预测固定数量的边界框(yolo-v1是2个,v2是5个,v3是3个,这几个边界框初始大小是不同的)。
- 这几个边界框中只有和GT的IOU最大的边界框才是用来预测该目标的。
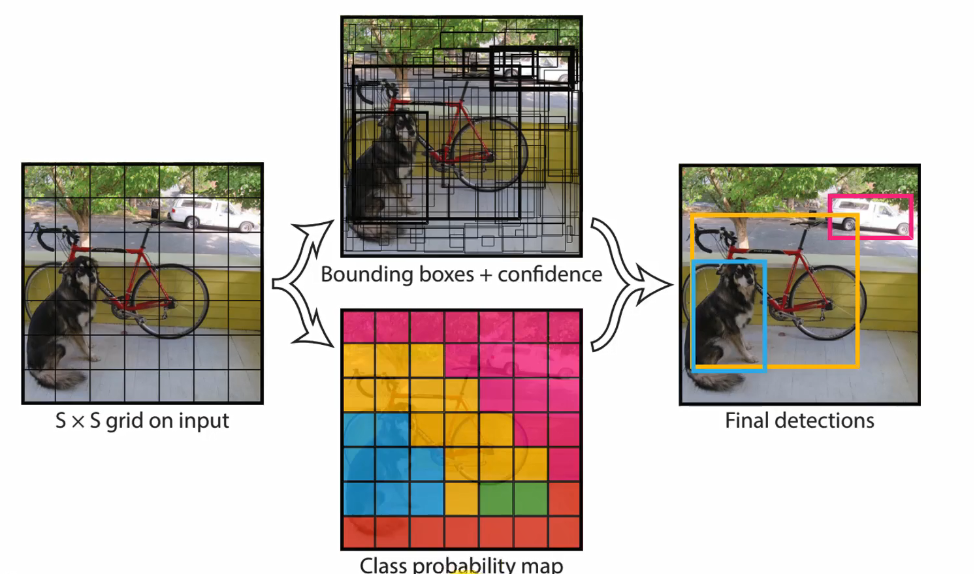
-
预测数据包括框的坐标+目标置信度+类别概率
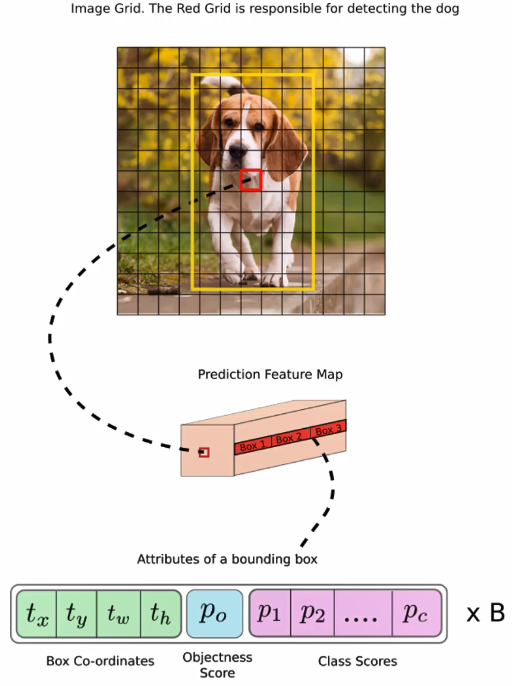
-
预测得到的输出特征图有两个维度是提取到的特征的维度,比如13x13,还有一个维度(深度) 是
Bx(5+C),注: YOLO v1中是(B x 5+C),其中B表示每个grid cell预测的边界框的数量(比如YOLO v1中是2个, YOLO v2中是5个, YOLO v3中是3个); C表示边界框的类别数(没有背景类,所以对于VOC数据集是20), 5表示4个坐标信息和一个目标性得分(objectness score)。
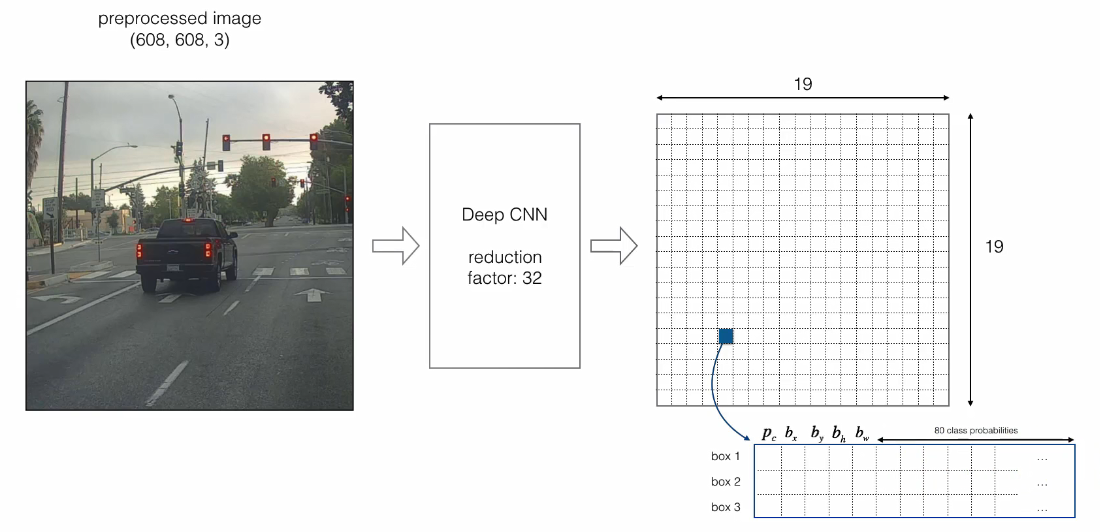
-
原图
608*608*3经过DeepCNN特征提取网络,得到一定大小的特征,维度降低为19*19(608*608*3降维32得到19*19*3的网格,416*416降维32得到13*13的网格)
类别预测(Class Prediction)
- 大多数分类器假设输出标签是互斥的。 如果输出是互斥的目标类别,则确实如此。 因此, YOLO应用softmax函数将得分转换为总和为1的概率。 而YOLOv3使用多标签分类。 例如,输出标签可以是“行人”和“儿童”,它们不是非排他性的。 (现在输出的总和可以大于1)
- YOLOv3用多个独立的逻辑分类器替换softmax函数,以计算输入属于特定标签的可能性。 在计算分类损失时, YOLOv3对每个标签使用二元交叉熵损失。这也避免使用softmax函数而降低了计算复杂度。
边界框预测和代价函数计算
- YOLOv3使用逻辑回归预测每个边界框的目标性得分(objectness score )。
- YOLOv3改变了计算代价函数的方式。
- 如果边界框先验(锚定框)与GT目标比其他目标重叠多,则相应的目标性得分应为1。
- 对于重叠大于预定义阈值(默认值0.5)的其他先验框,不会产生任何代价。
- 每个GT目标仅与一个先验边界框相关联。 如果没有分配先验边界框,则不会导致分类和定位损失,只会有目标性的置信度损失。
- 使用tx和ty(而不是bx和by)来计算损失。
非最大值抑制
- 为避免多个grid检测同一个object的情况,采用非最大值抑制的方法,去除重复的预测。
多尺度的特征提取
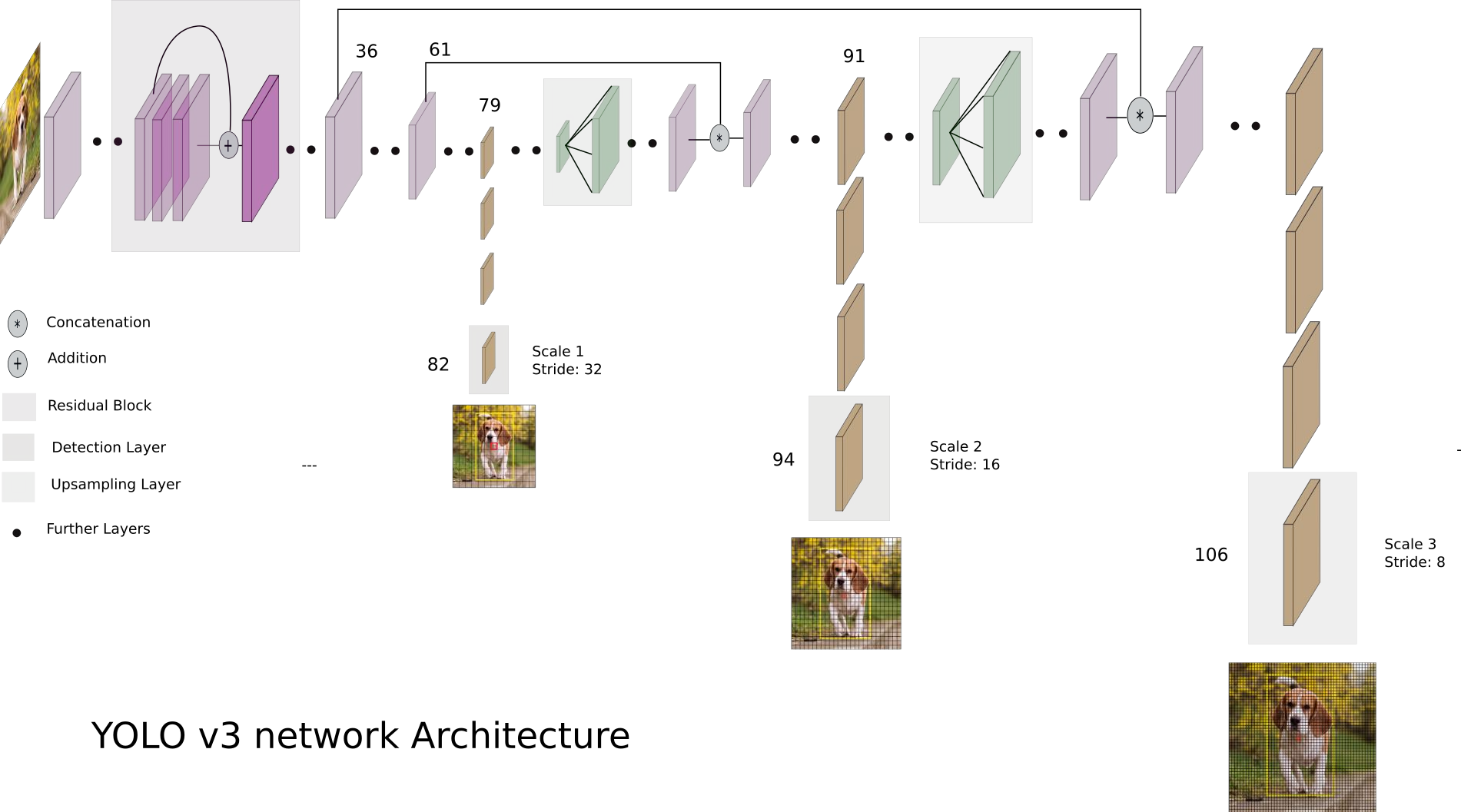
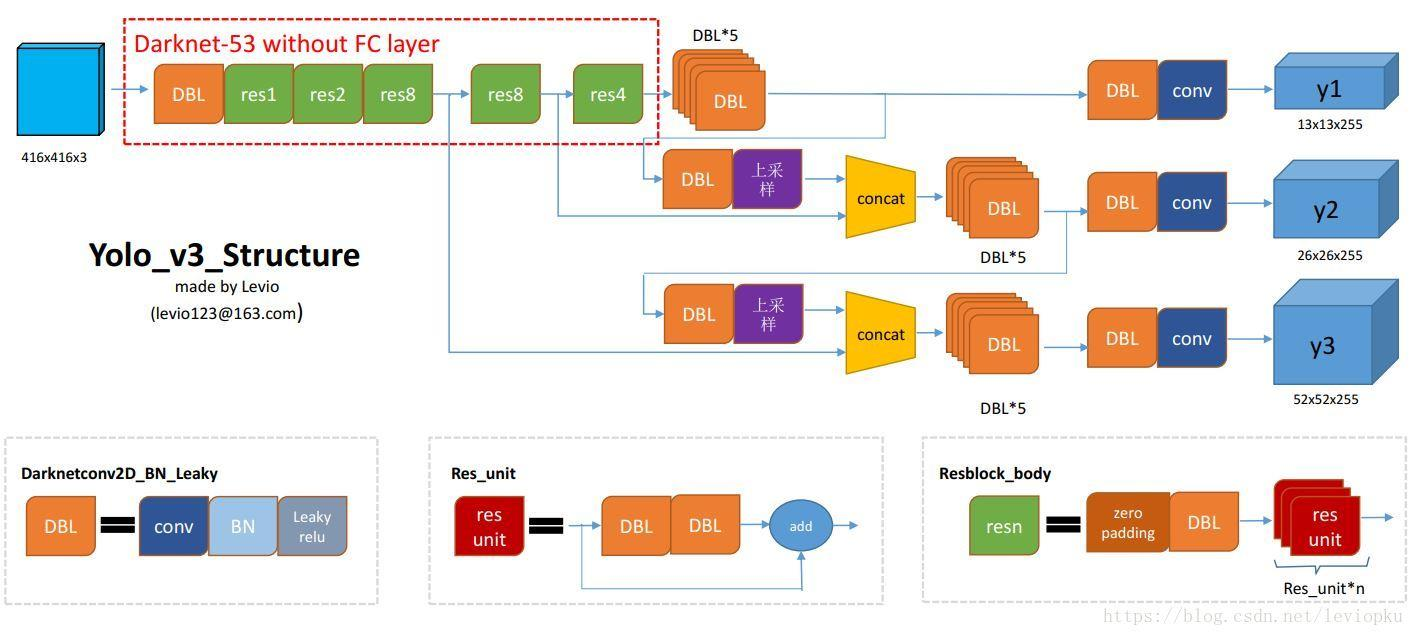
- yolo v3输出了3个不同尺度的特征,如上图所示的y1, y2, y3。借鉴了FPN(feature pyramid networks),采用多尺度来对不同大小的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
- y1,y2和y3的深度都是255,边长的规律是13:26:52。
- 对于COCO类别而言,有80个类别, 所以每个box应该对每个类别都输出一个概率。 yolo v3设定的是每个网格单元预测3个边界框,所以每个边界框有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以
3x(5+80)=255。 - 回忆下 v1的输出张量:7x7x30,只能识别20类物体,而且每个cell只能预测2个边界框。
Feature Pyramid Networks
-
YOLOv3每个位置做3组不同尺度的预测。每个预测由边界框、 objectness和80个类别得分组成,即N×N×[3×(4+1+80)]个预测。
-
YOLOv3以3种不同的尺度进行预测(类似于FPN):
- 在最后一个特征图层
- 然后它后退2层,然后将其2倍上采样。然后, YOLOv3采用具有更高分辨率的特征图,并使用逐元素相加将其与上采样特征图合并。 YOLOv3在合并图上应用卷积滤波器以进行第二组预测
- 再次重复2,以使得到的特征图层具有良好的高级结构(语义)信息和目标位置的好的分辨率空间信息。
-
为确定priors, YOLOv3应用k均值聚类。然后它预先选择9个聚类簇。对于COCO,锚定框的宽度和高度为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116× 90),(156×198),(373×326)。这应该是按照输入图像的尺寸是416×416计算得到的。这9个priors根据它们的尺度分为3个不同的组。在检测目标时,给一个特定的特征图分配一个组。
多尺度融合的方式做预测

- YOLO v2有一个层叫: passthrough layer,假设最后提取的特征图的大小是13x13,那么这个层的作用就是将前面一层的26x26的特征图和本层的13x13的特征图进行连接,有点像ResNet。
- 当时这么操作也是为了加强YOLO算法对小目标检测的精确度。
- 这个思想在YOLO v3中得到了进一步加强。在YOLO v3中采用类似FPN的上采样和多尺度融合的做法(最后融合了3个尺度,其他两个尺度的大小分别是26x26和52x52),在多个尺度的特征图上做检测,对于小目标的检测效果提升还是比较明显的。
- 前面提到过在YOLO v3中每个grid cell预测3个边界框,看起来比YOLO v2中每个grid cell预测5个边界框要少,其实不然。因为YOLO v3采用了多尺度的特征融合,所以边界框的数量要比之前多很多,以输入图像为416x416为例: (13x13+26x26+52x52)x3比13x13x5更多。
Darknet-53 Feature extractor
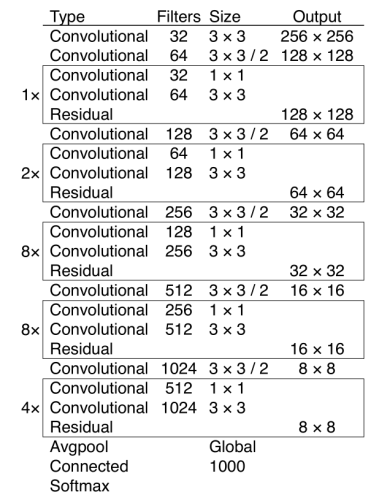
- 一个新的53层Darknet-53用于取代Darknet-19作为特征提取器。
- Darknet-53主要由3×3和1×1滤波器组成, 具有residual连接,如ResNet中的残差网络。
- Darknet-53比ResNet-152具有更少的BFLOP( billion floating point operations ),但实现了相同的分类准确度,速度快了2倍。
注:整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在v2中,特征图要经历5次池化,缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)。 v3也和v2一样, backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数
YOLO-v4
改进
- CSPNet,CSPDarknet53
- Mish激活函数
- SPP(Spatial Pyramid Pooling,空间金字塔池化)
- PANet(Path Aggregation Network)
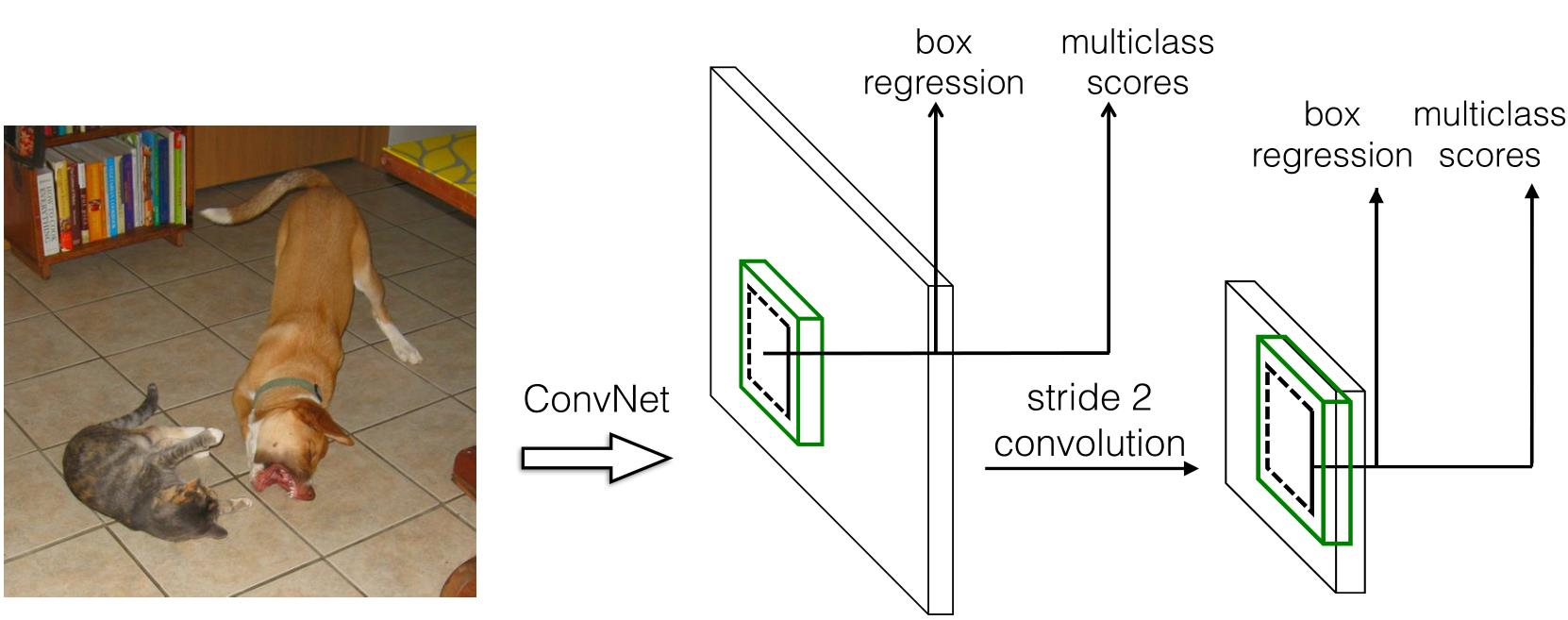
SSD
- SSD2016,
贡献
- 一种针对多类别的single-shot检测器(single-shot detector),比single-shot检测器YOLO更快,并且和 Faster R-CNN一样准确
- 使用应用于特征图上的小卷积滤波器,对一组默认的边界框(BB) 集合进行类别得分和框偏移预测,针对默认框的分开的单独滤波器,可以处理宽高比的差异
- 从不同尺度的特征图预测不同尺度,并根据宽高比独立预测
- 端到端训练和高准确度,提高速度与准确性的权衡
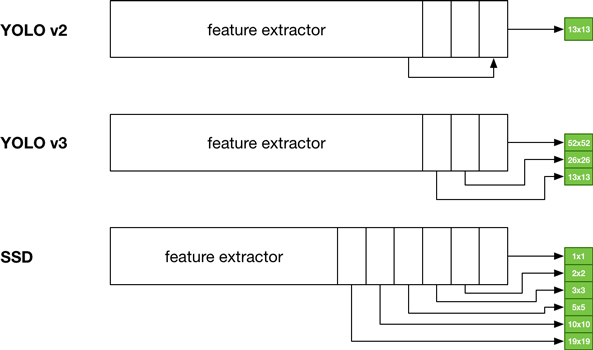
- YOLO v3和SSD非常相似,尽管它们通过不同的方法达到了最终的网格尺寸(YOLO使用了上采样,SSD使用了下采样)。
优缺点
- 对于小尺寸目标对象, SSD的性能比Faster R-CNN差。 SSD只能在较高分辨率的层(最左边的层)检测小目标。 但是这些层包含低级特征,如边缘或色块,分类的信息量较少。
- 准确率随着默认边界框的数量而增加,但以速度为代价。
- 多尺度特征图改进了不同尺度的目标的检测。
- 设计更好的默认边界框将有助于准确性。
- COCO数据集具有较小的目标。 要提高准确性,使用较小的默认框(以较小的尺度0.15开始)。
- 与R-CNN相比, SSD具有较低的定位误差,但处理相似类别的分类错误较多。 较高的分类错误可能是因为使用相同的边界框来进行多个类别预测。
- SSD512 具有比SSD300更高的精度(2.5%),但运行速度为22 FPS而不是59 FPS
模型结构
多尺度特征图和默认边界框
- 与经典的滑动窗预测不同,采用更为粗略的检索方式,减少运算复杂度
- 每个特征图cell对应于𝑘个锚定框
- 类似于Faster-RCNN,但在多尺度特征图中直接输出类别信息
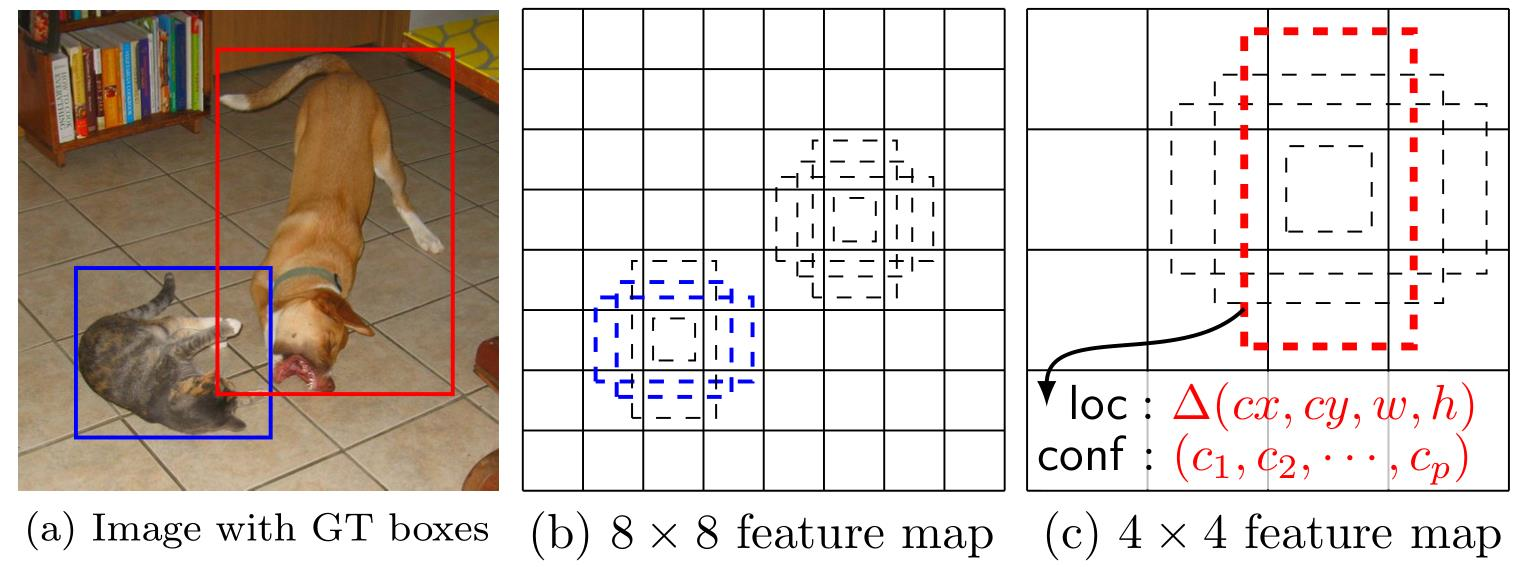
- 狗匹配一个4×4特征图层中的一个默认框(红色),但不匹配更高分辨率的8×8特征图中的任何默认框。
- 较小的猫只能通过2个默认框(蓝色)中的8×8特征图层来检测。
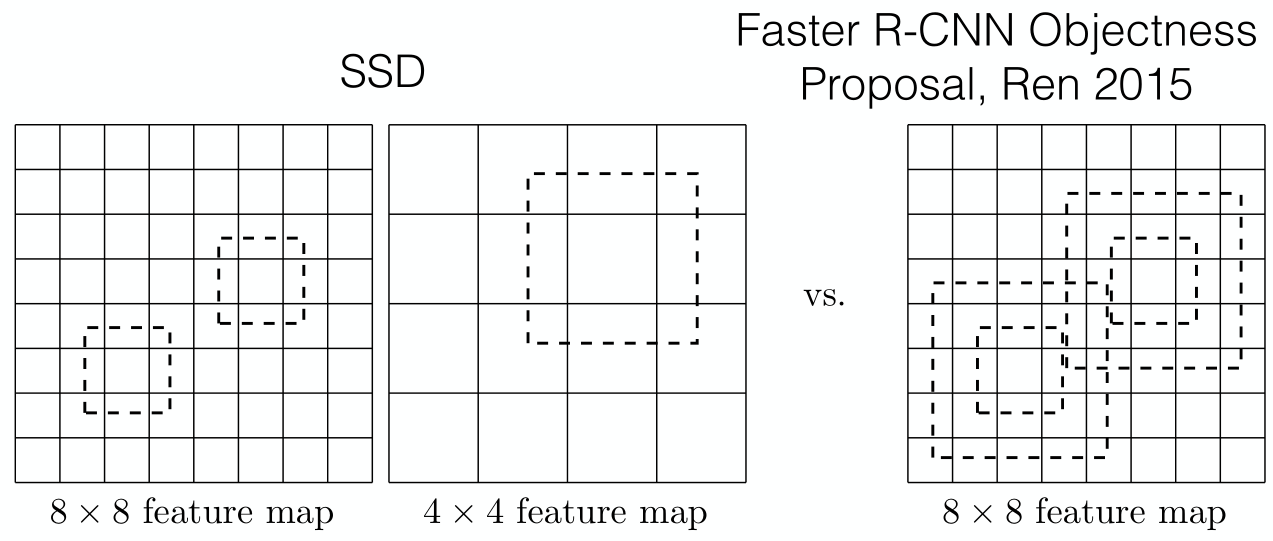
默认边界框
| 宽高比 | box数量 | VOC2007 mAP |
|---|---|---|
| 默认 | 3880 | 71.6 |
| (,2)box | 7760 | 73.7 |
| (,2)box,(,3)box | 8732 | 74.3 |
网络结构
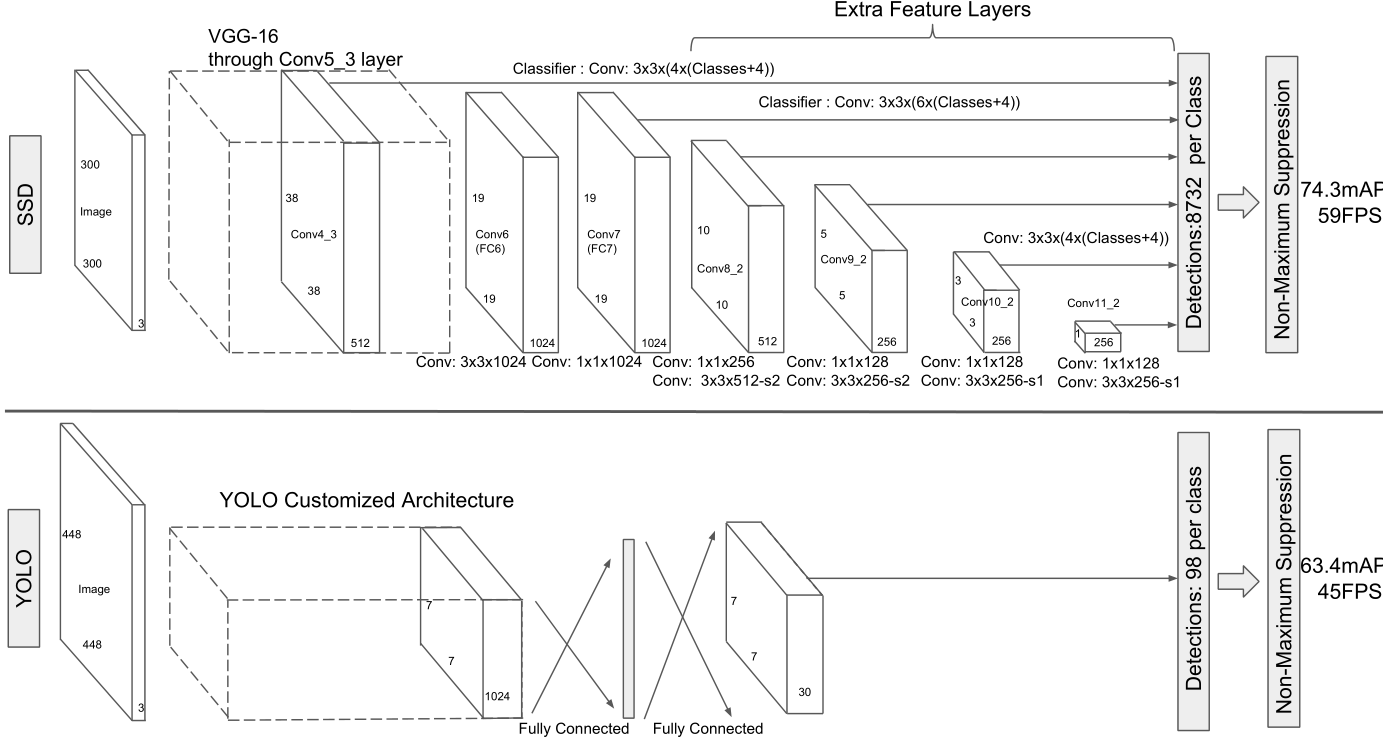

- SSD模型在基础网络后面添加了几个特征图层,可以预测不同尺度和宽高比的默认框的偏移量以及相关的置信度
- 具有300×300输入大小的SSD在VOC2007测试中的精度明显优于其448×448 YOLO,同时还提高了速度
- 在每个卷积特征图的顶部应用一组滤波器,用于预测不同宽高比和类别的检测
- SSD就是Faster-RCNN和YOLO中做了一次的分类和检测过程放在不同大小的特征图上做了多次。
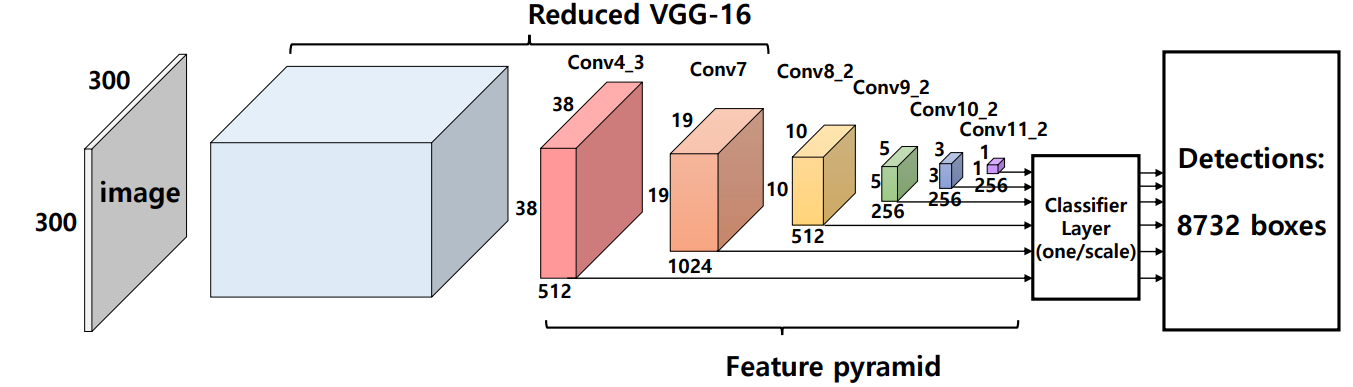
- 从Conv4-3到Conv11-2的层用作分类器网络的输入,称为特征金字塔。 特征金字塔中的每个层负责检测相应大小的目标对象。
- 高分辨率的特征图负责检测小目标。 用于目标检测的第一层conv4_3具有38×38的空间维度,与输入图像相比具有相当大的减小。
- 对小目标表现不佳时, SSD可以通过使用更高分辨率的图像来缓解
- SSD300一共可以预测8732个边界框
| Name | Out_size | Prior_box_num | Total_num |
|---|---|---|---|
| conv4-3 | 38x38 | 4 | 5776 |
| fc7 | 19x19 | 6 | 2166 |
| conv5-2 | 10x10 | 6 | 600 |
| conv7-2 | 5x5 | 6 | 150 |
| conv8-2 | 3x3 | 4 | 36 |
| conv9-2 | 1x1 | 4 | 4 |
| 8732 |
| - | faster R-CNN | YOLO | SSD300 | SSD512 |
|---|---|---|---|---|
| boxes | 6000 | 98 | 8732 | 24564 |
| resolution | 100*600 | 488*488 | 300*300 | 512*512 |
- SSD使用VGG16提取特征图。 然后它使用Conv4_3层检测目标。 为了说明,我们将Conv4_3在空间上绘制为8×8(它应该是38×38)。 对于每个单元格(也称为位置),它进行4个目标预测。
- 每个预测由一个边界框以及有21个类别得分(包含没有目标的一个额外类别),选择最高分作为框定目标的类别。
- Conv4_3总共进行了38×38×4个预测:无论特征图的深度如何, 每个单元有四个预测。 许多预测不包含任何目标。SSD保留类“0”以指示它没有目标。
- 每个预测包括一个边界框和21个类别的21个得分(一个类没有目标)
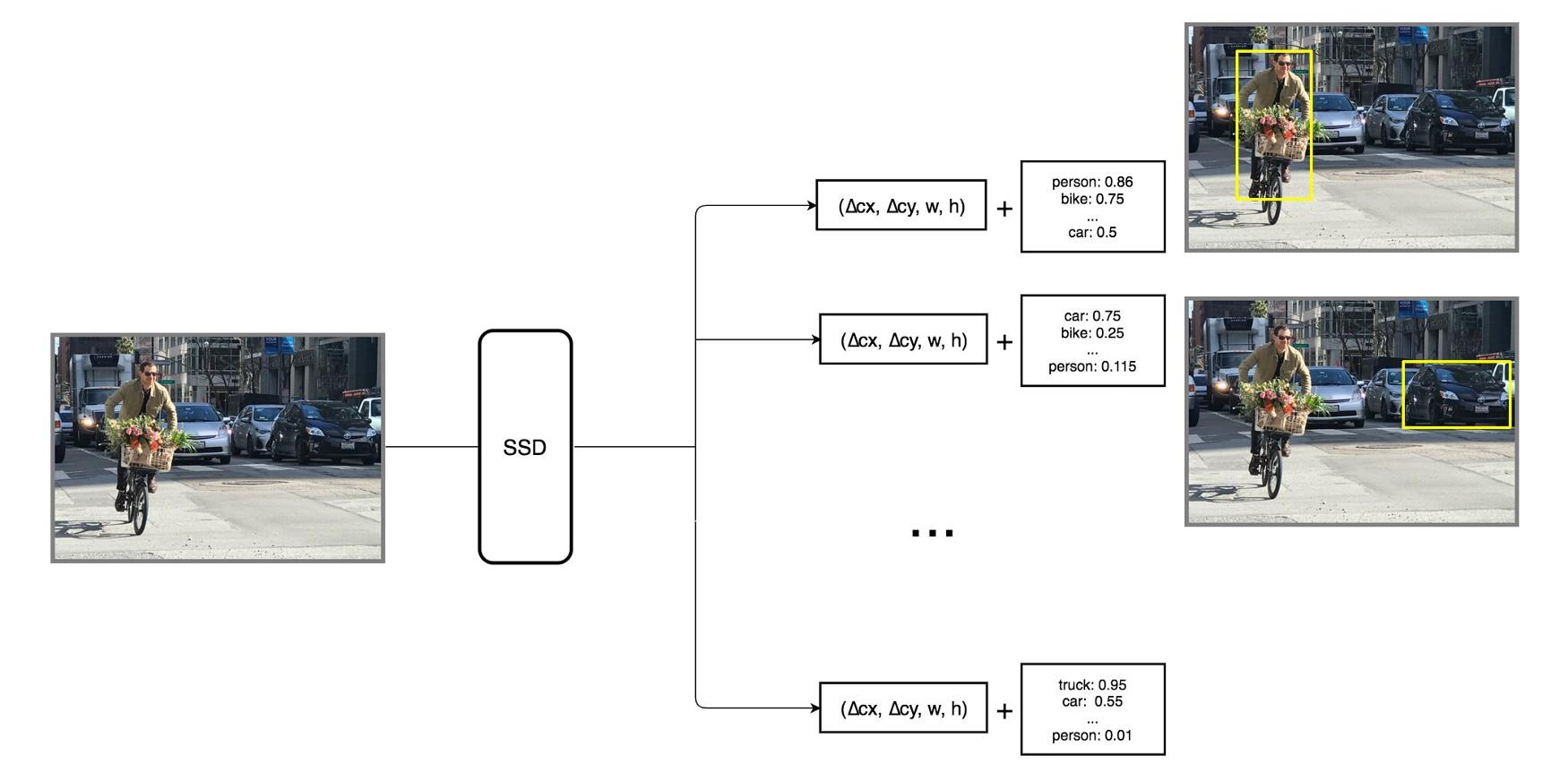
处理boxes
- 只检测匹配的groud truth和default boxes,IoU>0.5
- 困难负样本挖掘:不平衡的数据样本,保持TP:FP为1:3
目标检测的卷积预测器
- SSD不使用特定的区域建议网络。它采用一个非常简单的方法,即使用小卷积滤波器计算位置和类别得分。
- 在提取特征图之后,SSD对每个单元应用3×3卷积滤波器以进行预测(这些滤波器像常规CNN滤波器一样计算结果)。
- 每个滤波器输出25个通道:每个类别21个分数加上一个边界框。
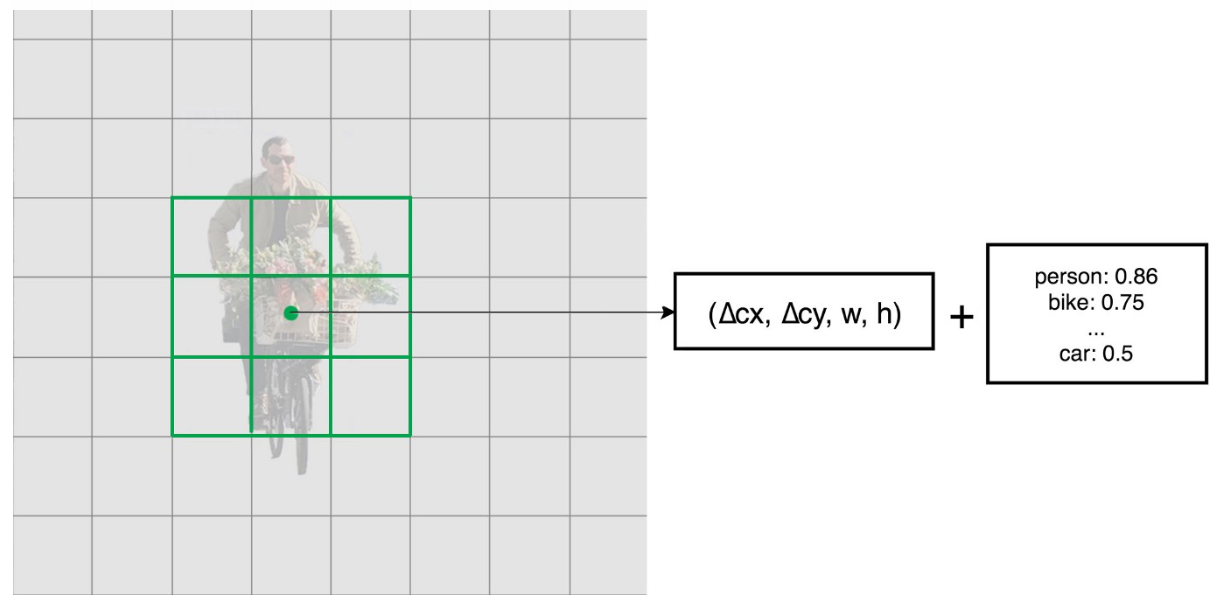
- 在Conv4_3中,应用4个3×3滤波器将512个输入通道映射到25个输出通道:
默认边界框
- 默认边界框等同于Faster R-CNN中的锚定框
- 对于每个特征图层,它共享单元格为中心的同一组默认框。 但是不同的层使用不同的默认框来自定义不同分辨率的目标检测。 下面的4个绿框表示4个默认边界框。
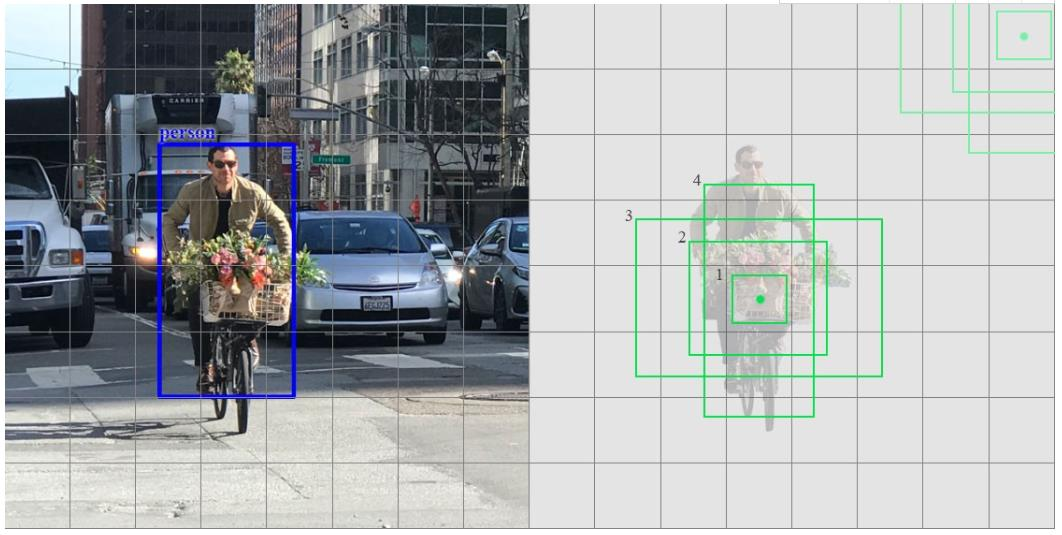
- 默认边界框是手动选择的。 SSD为每个特征图层定义一个尺度值。 从左侧开始, Conv4_3以最小尺度0.2(或有时为0.1)检测目标,然后以0.9的比例线性增加到最右边的层。 将尺度值与目标宽高比相结合,计算默认框的宽度和高度。 对于进行6次预测的层, SSD以5个目标宽高比开始: 1, 2, 3, 1/2和1/3。
- 默认框的宽度和高度计算(YOLO在训练数据集上使用k-means聚类来确定默认边界框):
匹配策略
- SSD预测分为正匹配或负匹配。 如果相应的默认边界框(不是预测的边界框)与GT的IoU大于0.5,则匹配为正。 否则,是负的。
- SSD仅使用正匹配来计算边界框不匹配的代价。
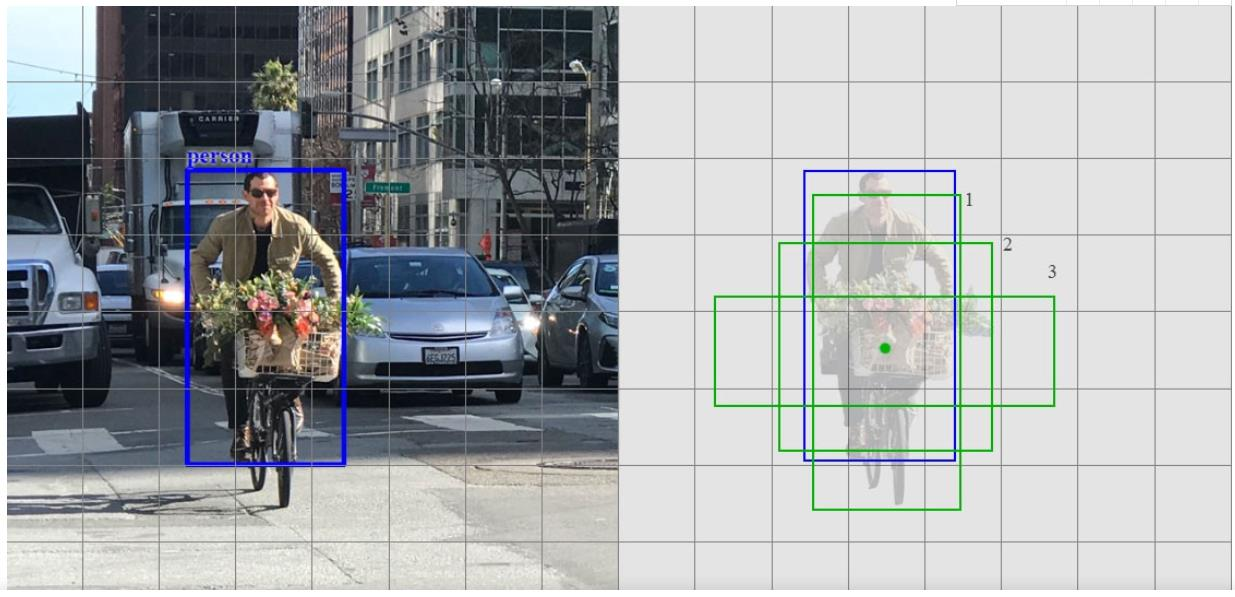
- 让我们将讨论简化为3个默认框。 只有默认框1和2(但不是3)的IoU大于0.5,上面的GT框(蓝框)。 因此,只有第1和第2个框是正匹配。 一旦识别出正匹配,就使用相应的预测边界框来计算代价。 这种匹配策略很好地划分了预测所负责的GT框的形状。
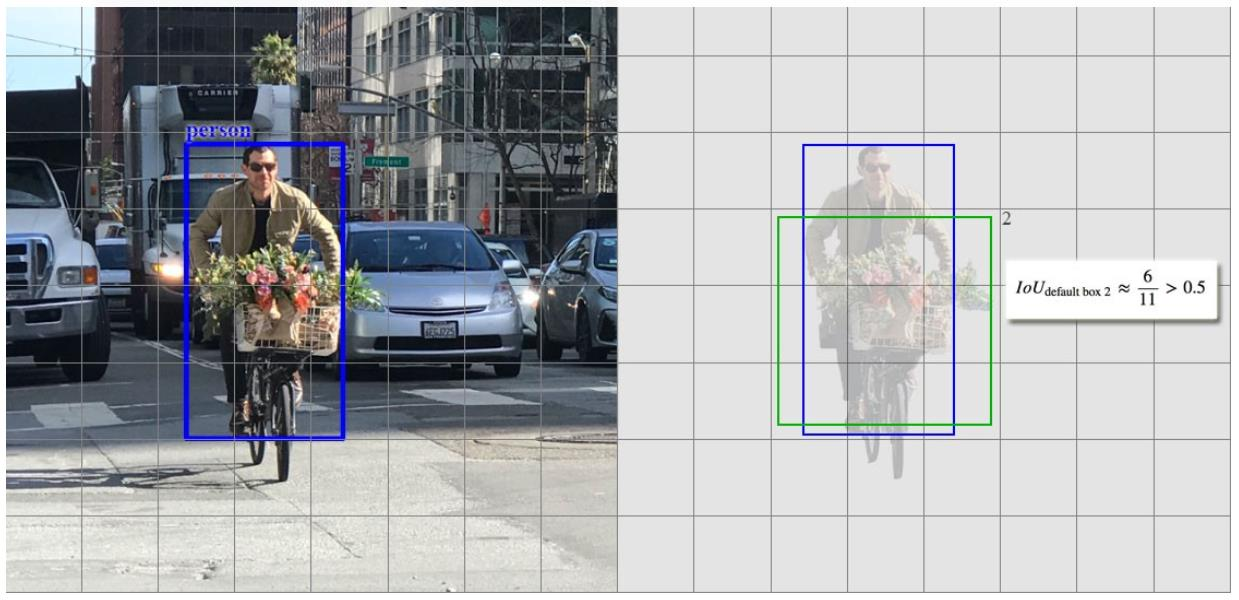
- 该匹配策略鼓励每个预测更接近相应默认框的形状。 因此,预测在训练中更加多样化和稳定。
训练
- 总体目标损失函数是定位损失(loc)和置信度损失(conf)的加权和:
- 定位损失是GT框与预测边界框之间的不匹配
- SSD仅对正匹配的预测进行惩罚。 希望正匹配的预测能够更接近GT。 负匹配可以忽略。
- 定位损失是预测框(𝑙)和GT框(𝑔)参数之间的Smooth L1损失。
- 与Faster R-CNN类似,我们回归到默认边界框(𝑑)的中心(𝑐𝑥, 𝑐𝑦)以及宽度(𝑤)和高度(ℎ)的偏移:
- 置信度损失是多类置信度(c)下的softmax损失:
基础网络
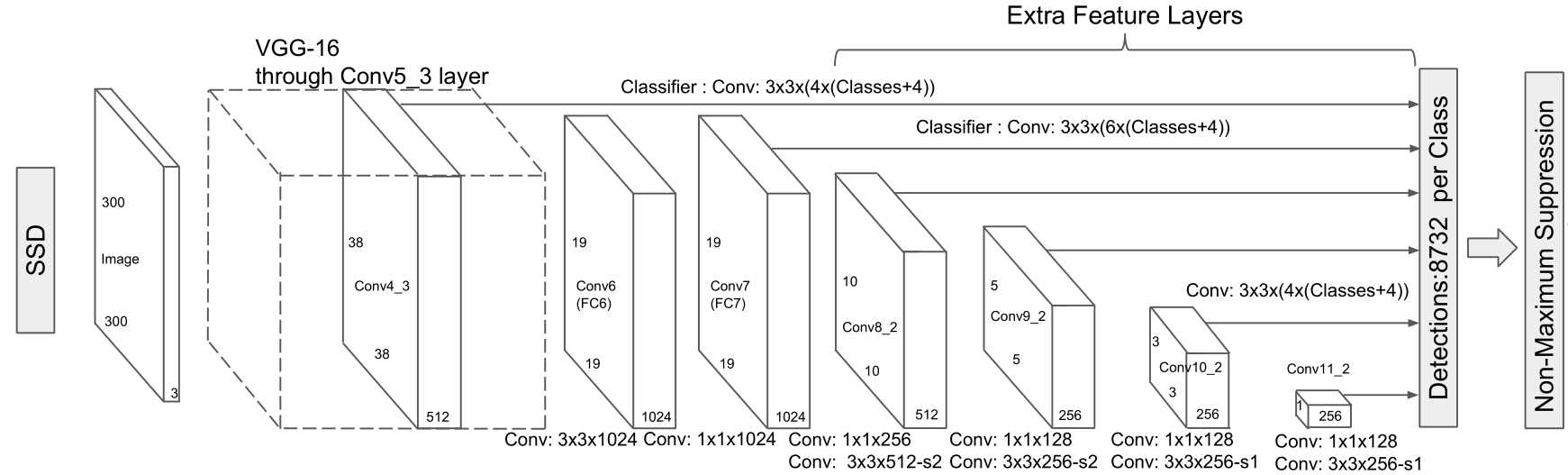
- 首先VGG16在ILSVRC CLS-LOC数据集上进行预训练。
- 然后借鉴了DeepLab-LargeFOV,分别将VGG16的全连接层fc6和fc7转换成3×3卷积层conv6和1×1卷积层conv7,同时将池化层pool5由原来的2×2−s2变成3×3−s1。
- 为了配合这种变化,采用了一种Atrous Algorithm,其实就是conv6采用带孔卷积(Dilation Conv), 在不增加参数与模型复杂度的条件下指数级扩大卷积的感受野。
- 然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做fine tuning。
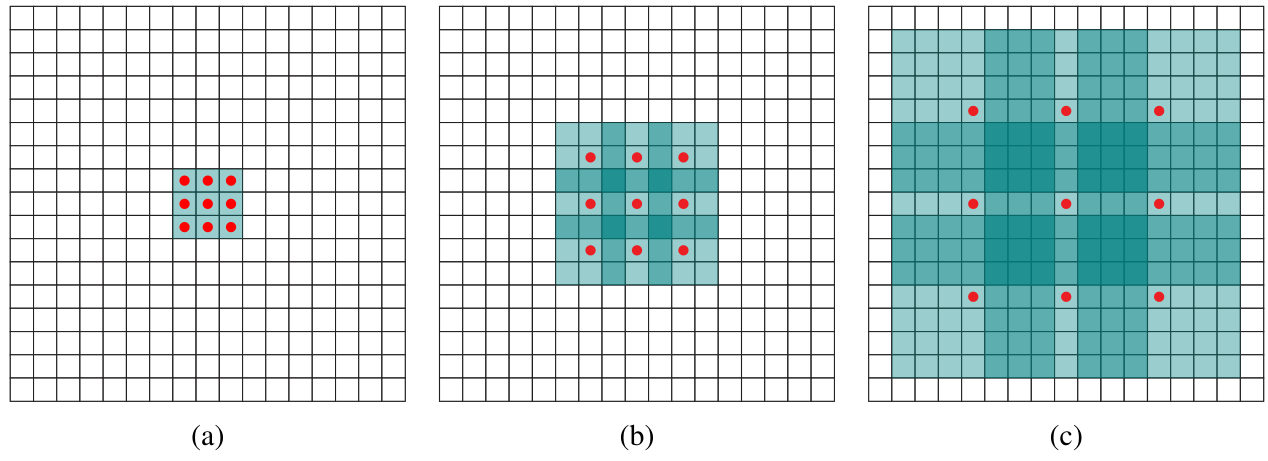
带孔卷积
- 带孔卷积(Dilation Conv),在不增加参数与模型复杂度的条件下指数级扩大卷积的感受野。使用扩张率(dilation rate)参数,来表示扩张的大小。
- 如下图所示, (a)是普通的3×3卷积,其感受野就是3×3, (b)是扩张率为2,此时感受野变成7×7, ©扩张率为4时,感受野扩大为15×15,但是感受野的特征更稀疏了。
- Conv6采用3×3大小, dilation rate=6的膨胀卷积。
-
从后面新增的卷积层中提取Conv7, Conv8_2, Conv9_2, Conv10_2, Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。
-
先验框的设置,包括尺度和宽高比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
-
Suppose we want to use m feature maps for prediction. The scale of the default boxes for each feature mapis computed as:
-
对于宽高比,一般选取𝑎𝑟∈{1, 2, 3, 1/2, 1/3}
-
每个特征图一共有6个先验框{1,2,3,1/2,1/3,1′}但是在实现时, Conv4_3, Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为3,1/3的先验框。
-
Choosing scales and aspect ratios for default boxes: At each scale, different aspect ratios are considered: width and height of default bbox:
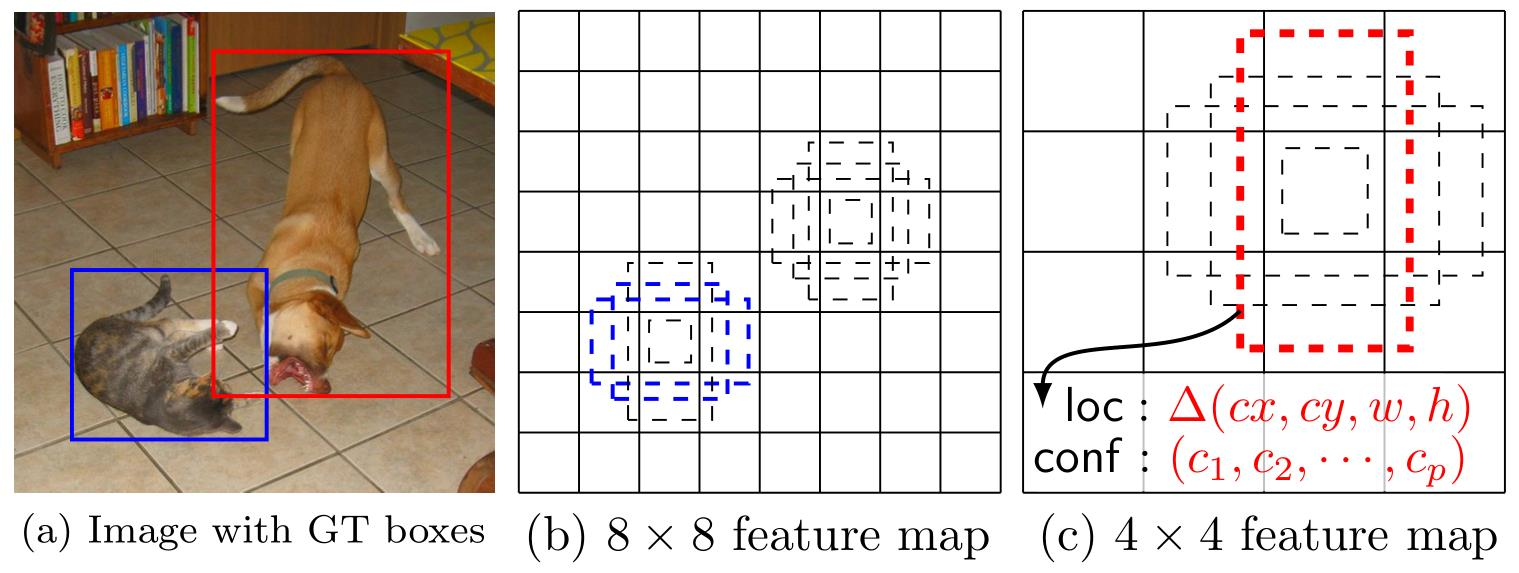
- 得到了特征图之后,需要对特征图进行卷积得到检测结果,左图给出了一个5×5大小的特征图的检测过程。其中Prior box是得到先验框,前面已经介绍了生成规则。
- 检测值包含两个部分:类别置信度和边界框位置,各采用一次3×3卷积来进行完成。令𝑛𝑘为该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为𝑛𝑘 × 𝑐,而边界框位置需要的卷积核数量为𝑛𝑘 × 4 。
- 由于每个先验框都会预测一个边界框,所以SSD300一共可以预测38 × 38 × 4 + 19 × 19 ×6 + 10 × 10 × 6 + 5 × 5 × 6 + 3 × 3 × 4 + 1 ×1 × 4 = 8732 个边界框,这是一个相当大的数字,所以说SSD本质上是密集采样。

困难负样本挖掘
- 由于做出的预测远远超过目标存在的数量,所以负匹配比正匹配要多得多。 这造成了一种训练的类别不平衡:更多地学习背景空间而不是检测目标。
- 然而, SSD仍然需要负采样,因此它可以了解什么构成不良的预测。 因此,我们不是使用所有的样本,而是通过计算的置信度损失对这些负样本进行排序。 SSD选择最高损失的负样本并确保所选负样本与正样本之间的比率最多为3:1。 这导致更快和更稳定的训练。
数据增强
- 数据增强对于提高准确性非常重要。 通过翻转、裁剪和颜色失真来增加数据。
- 要处理各种目标大小和形状的变体,每个训练图像都是通过以下选项之一随机采样:
- Use the original,
- Sample a patch with IoU of 0.1, 0.3, 0.5, 0.7 or 0.9,
- Randomly sample a patch.
预测过程
- 预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。
- 然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。
- 最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果。
DSSD
- DSSD2017
- 新的DSSD模型能够胜过以前的SSD框架,特别是在小目标或上下文特定目标上,同时仍然保持与其他检测器相当的速度。
改进
-
SSD算法对小目标不够鲁棒(会出现误检和漏检);最主要的原因是浅层特征图的表示能力不够强。 DSSD算法的核心思想就是提高浅层的表示能力。
-
DSSD在原来的SSD模型上主要作了两大改进:
-
一是替换掉VGG,而改用了Resnet-101作为特征提取网络并在对不同尺度的特征图进行默认框检测时使用了更新的检测单元;
-
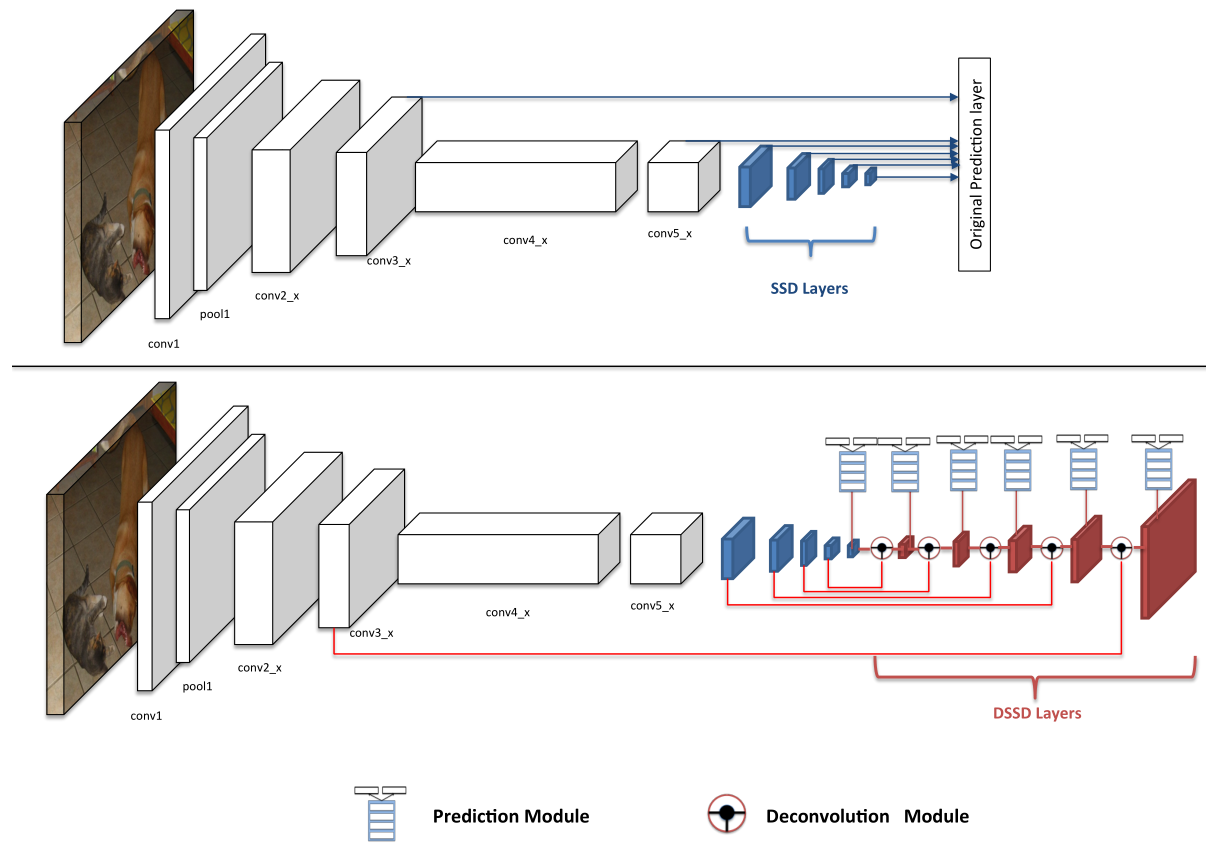
二则在网络的后端使用了多个反卷积层(deconvolution layers)以有效地扩展低维度信息的上下文信息(contextual information) ,从而有效地改善了小尺度目标的检测。添加多余的Residual模块,然后使用conv3_x/conv5_x及后添加的一些模块输出的特征图来预测边界框的得分及框偏移量等
-
-
残差网络上的SSD和DSSD网络: 蓝色模块是SSD框架中添加的层,称之为SSD层。 在下图中,红色图层是DSSD层。
网络结构
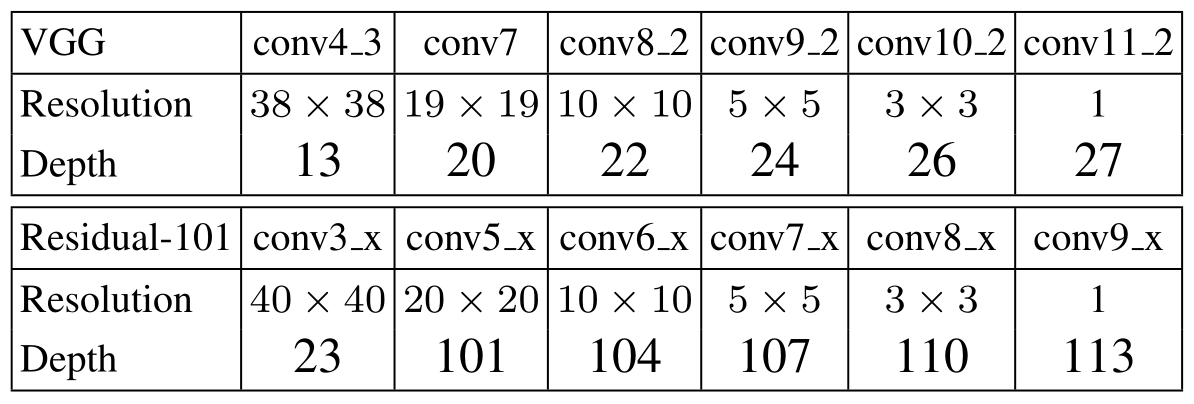
ResNet101代替VGG
- 为了改进目标检测模型,进一步提升其检测精度,作者首先考虑使用更强大的Resnet-101来代替之前在SSD中使用的VGG作为模型的特征提取网络。
- 同时在经典的Resnet-101模型后端添加了一些residual模块以来加强原来模型的特征表达。作者从conv5_x的后端开始添加多余的Residual模块,然后使用conv3_x/conv5_x及后添加的一些模块输出的特征图来预测边界框的得分及框偏移量等。
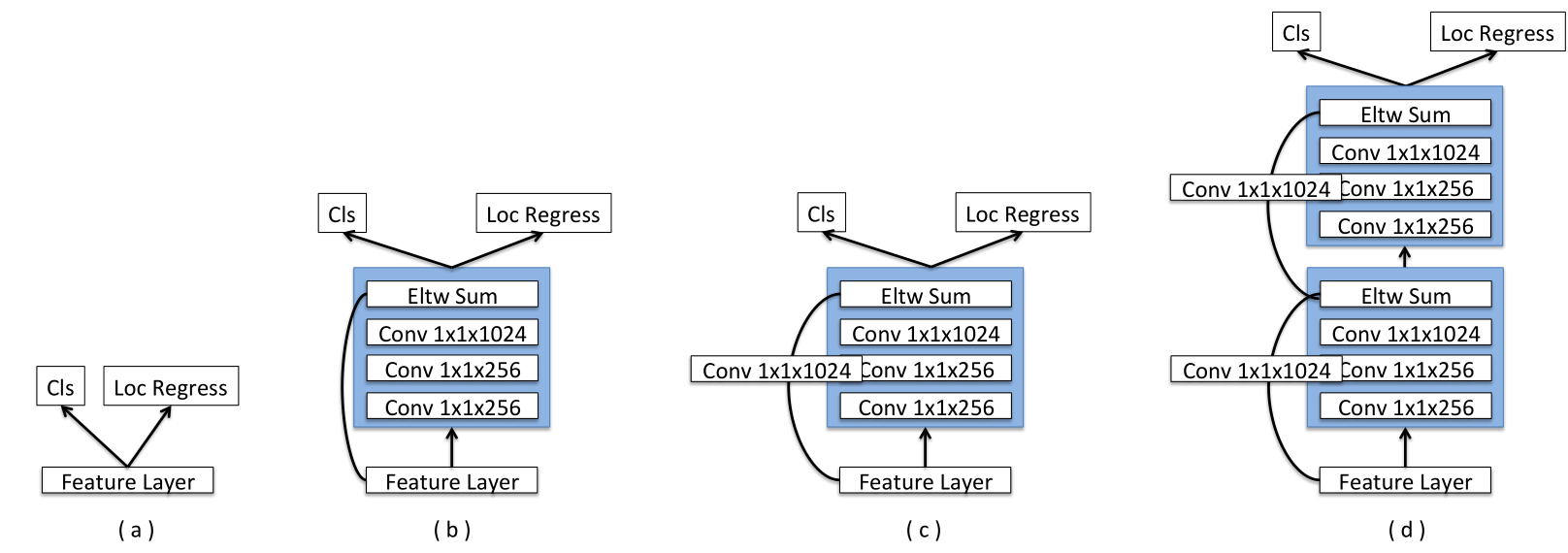
新的预测模块
- 为每个预测层添加一个残差块,如(c)所示。还尝试了原始的SSD方法(a)和具有跳跃连接(b)的残差块的版本以及两个连续的残差块(d)。
编码器
- 使用编码器 - 解码器沙漏结构在进行预测之前传递上下文信息。
- 检测任务之外的研究已经开始使用称为“编码器 - 解码器”网络来集成上下文。其中网络中间的瓶颈层用于编码关于输入图像的信息然后在变大的层逐步解码成了整个图像的特征图。 由此产生的宽,窄,宽的网络结构通常被称为沙漏(hourglass)。
- 反卷积层不仅解决了卷积神经网络中特征图分辨率收缩的问题,而且还为预测带来了上下文信息。
反卷积模块
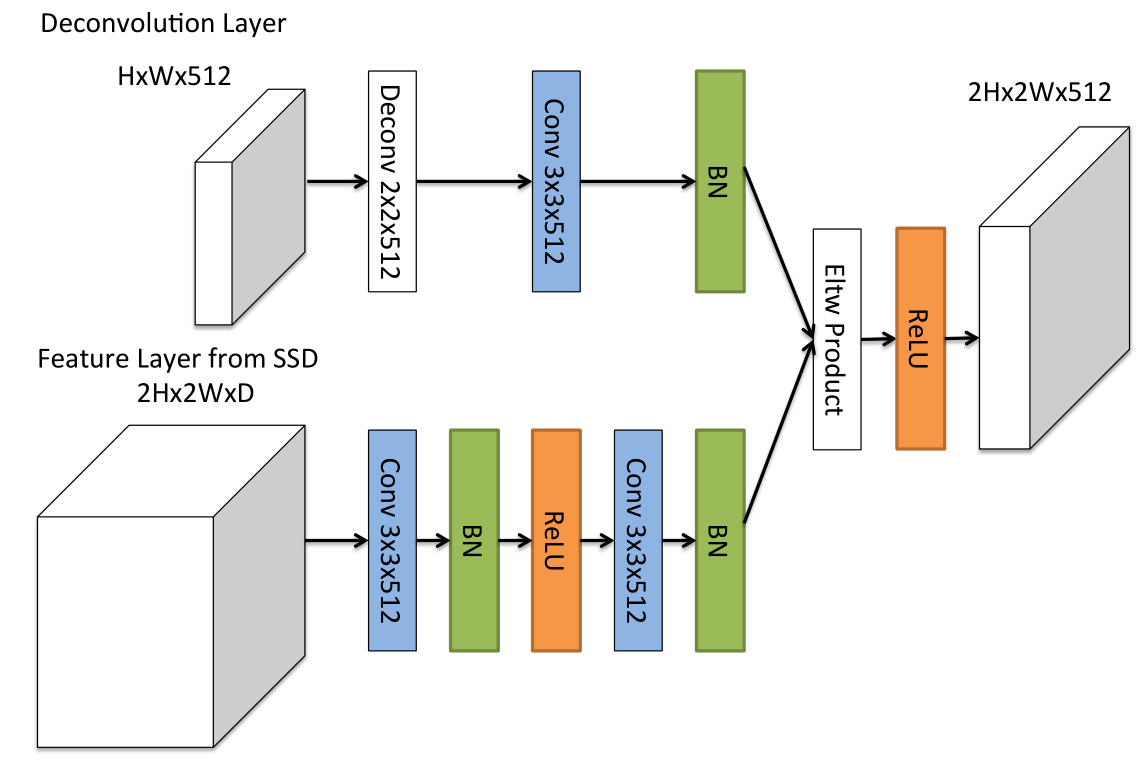
- DSSD的第二个重大创新来自于在模型后端添加了多个反卷积模块来扩大模型在小尺度上的high level特征信息。而这种反卷积输出的特征图又会与模型前端卷积层的相同尺度的特征图进行元素级的乘法(element-wise product) 来生成相应尺度的特征图。
- 添加额外的反卷积层以连续增加特征图层的分辨率。 为了加强特征,采用了沙漏模型中的“跳跃连接”理念
- 首先,在每个卷积层之后添加BN层。 其次,使用学习的反卷积层而不是双线性上采样。 最后,测试了不同的组合方法:逐元素相加和逐元素乘积。 实验结果表明,逐元素乘积提供了最佳的准确性
模型训练
- DSSD模型的训练与SSD相似。
- 同SSD一样,需要先将默认框匹配到对应的GT框。也是将所有与GT框具有最大重叠或重叠的IoU大于0.5的框视为正样本;然后再基于置信度损失选取一定比例(为3:1)的负样本框。计算所用的损失同SSD一样即为反映位置信息的L1 loss及反映类别信息的Softmax loss之和。
- 它所采用的数据增强的方式也与SSD完全一样。
- 不过在选取默认框的尺度时,借鉴了Yolo v2中的做法,即对训练集中已有的GT框进行聚类分析。然后基于在原来使用的(1.0,2.0,3.0)三种宽高比的默认框基础上增添了一种1.6的默认框。
RetinaNet
- RetinaNet2017
主要贡献
- 找到妨碍单阶段目标检测器实现高准确度的主要原因:
- 训练期间的前景-背景之间的类别不平衡:设计焦点损失(Focal Loss) 来解决这种类别不平衡问题,降低分配给分类良好例子的损失。
- 提出了单阶段RetinaNet网络架构,使用了焦点损失和多尺度特征金字塔。
损失函数
类别不平衡问题及解决方法
- 两阶段
- 区域建议阶段将候选目标位置的数量缩小到较小的数量(例如, 1~2k), 过滤掉大多数背景样本。
- 在第二个分类阶段,采取采样启发式(sampling heuristics),例如固定的前景 - 背景比(1:3),或在线难例挖掘(Online Hard Example Mining, OHEM)以保持前景和背景之间的平衡。
- 单阶段
- 必须处理在图像上规则采样的更大的候选目标位置集。 这通常相当于枚举约10万个覆盖空间位置、尺度和宽高比的密集位置。
- 使用采样启发法效率低,因为训练过程仍然由易分类的背景例支配。 这种低效率是目标检测中的典型问题,通常通过如bootstrapping 或难例挖掘等技术来解决。
- 作者提出一种新的损失函数,可以作为处理类不平衡的一种更有效的替代方法
二分类的交叉熵损失
- 定义,则
- 问题: CE loss 对容易分类的例子 也会导致non-trivial损失。 大量简单的例子相加,这些小损失值可以压倒the rare class (量小的类别) 。
二平衡的交叉熵
- 解决类不平衡的常用方法是为类1引入加权因子𝛼,为类-1引入1 − 𝛼。 实际上,可以通过类别频率的倒数设置或者作为超参数通过交叉验证来设置。𝛼-balanced loss可写为:
- 虽然 𝛼 平衡了正例/负例的重要性,但它并没有区分简单/困难的例子。 所以建议reshape损失函数,以减轻简单的例子,从而集中训练困难例子。
焦点损失
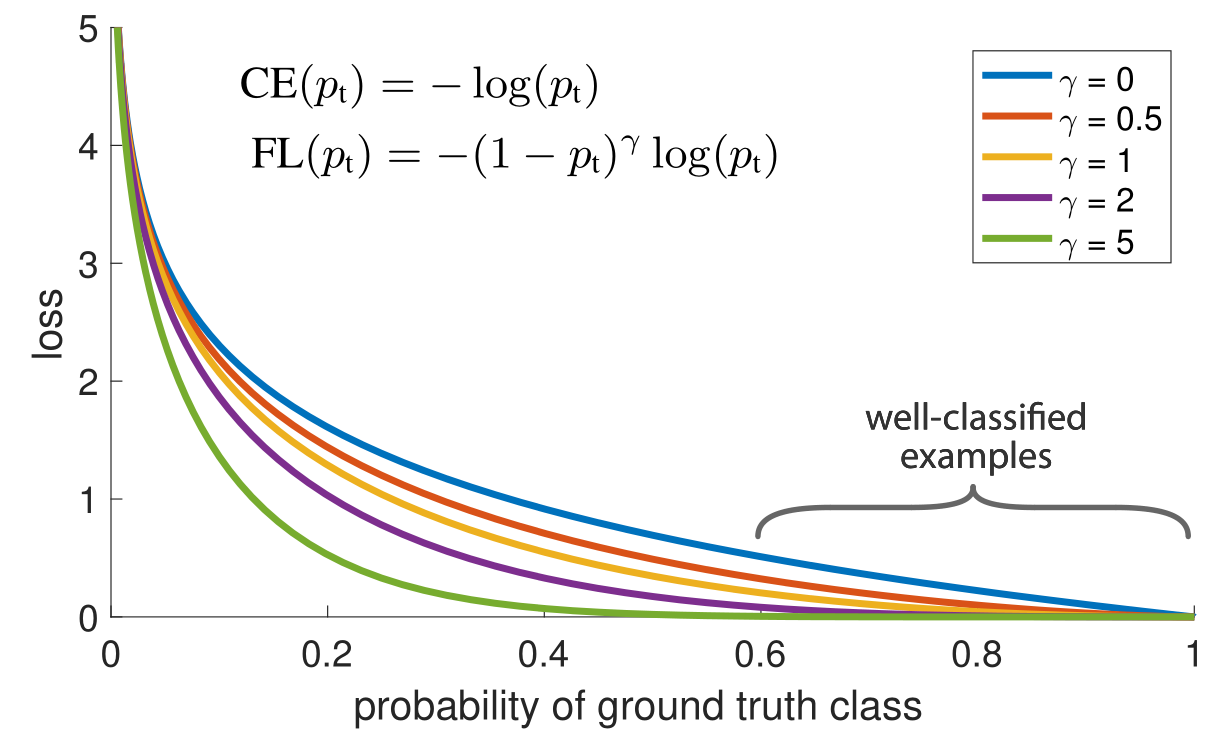
-
提出了一种新的损失,称为焦点损失,它将因子 加到标准交叉熵准则上。
-
设置可以减少分类良好例子的相对损失 ,更多地关注困难错误分类的例子。所提出的焦点损失使得能够在存在大量简单背景例子的情况下训练高度精确的密集目标检测器。
-
焦点损失旨在解决one-stage目标检测场景,其中在训练期间前景和背景类之间存在极度不平衡(例如, 1: 1000)
-
-
-
- 𝛾是可以改变的超参数。 𝑝𝑡是来自分类器的样本的概率。 设置𝛾大于0将减少分类良好的样本的权重。
- 𝛼𝑡是正常加权损失函数中所加的类别的权重。 称为𝛼-balanced loss 。
-
请注意,这是分类损失,还要与RetinaNet中目标检测任务的smooth L1损失相结合。
-
调制因子减少了简单样本的损失贡献,并扩展了样本接收低损失的范围。
-
本质改进点在于,在原本的交叉熵误差 (CE(𝑝𝑡)=− 𝛼𝑡log(𝑝𝑡)) 前面乘上了(1 − 𝑝𝑡 )𝛾 这一权重。
-
一旦乘上了该权重,量大的类别所贡献的损失被大幅消减,量少的类别所贡献的损失几乎没有多少降低。虽然整体的损失总量减少了,但是训练过程中量少的类别拥有了更大的话语权,更加被模型所关心了
网络结构
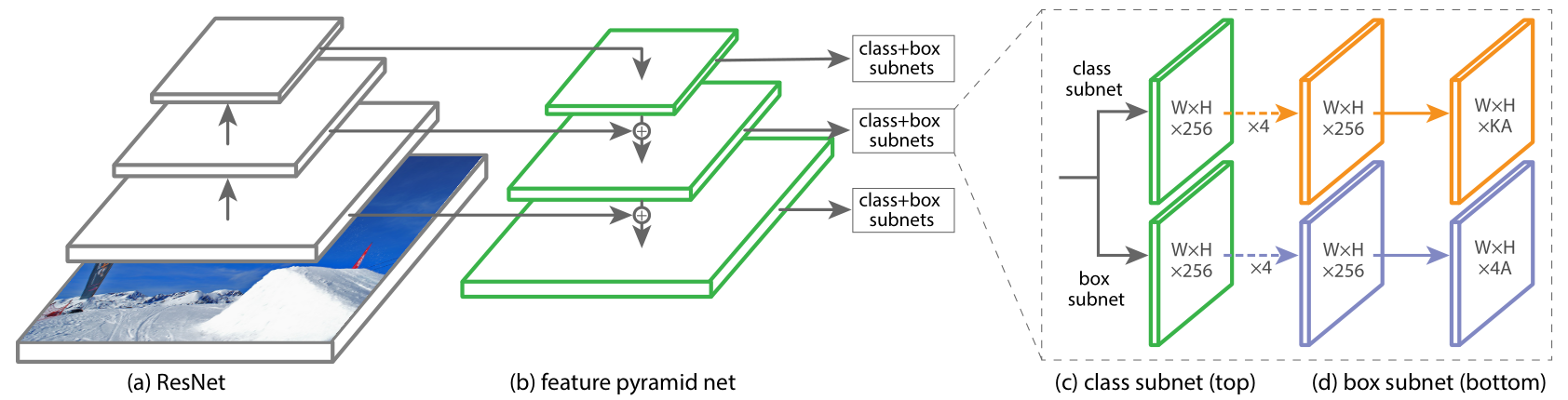
- 单阶段RetinaNet网络架构在前馈ResNet架构(a)之上使用特征金字塔网络(FPN)作为骨干网络,以生成丰富的多尺度的卷积特征金字塔(b)。
- 骨干网后, RetinaNet附加了两个子网,一个用于分类锚定框(c),一个用于从锚定框回归到GT目标框(d)
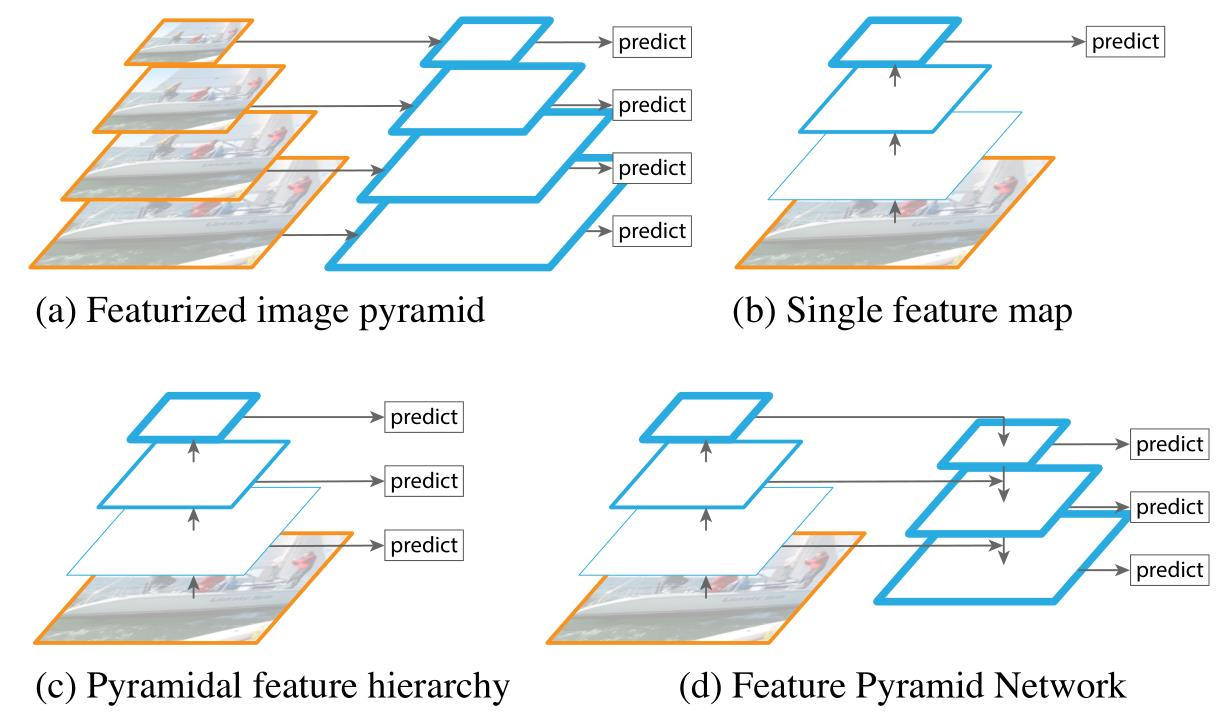
-
a:使用图像金字塔构建特征金字塔。 在每个图像尺度上独立地计算特征,比较缓慢。
-
b:最近的检测系统选择仅使用单一尺度的特征来加快检测速度。
-
c:另一种方法是重用从ConvNet计算的金字塔特征层次结构,就好像它是一个特征化的图像金字塔。
-
d:提出的特征金字塔网络(FPN)像(b)和(c)快速,但更准确,并在各个层独立进行预测。
-
Building block: 包括侧向连接(lateral connection )和自上而下路径(passway) ,通过相加合并
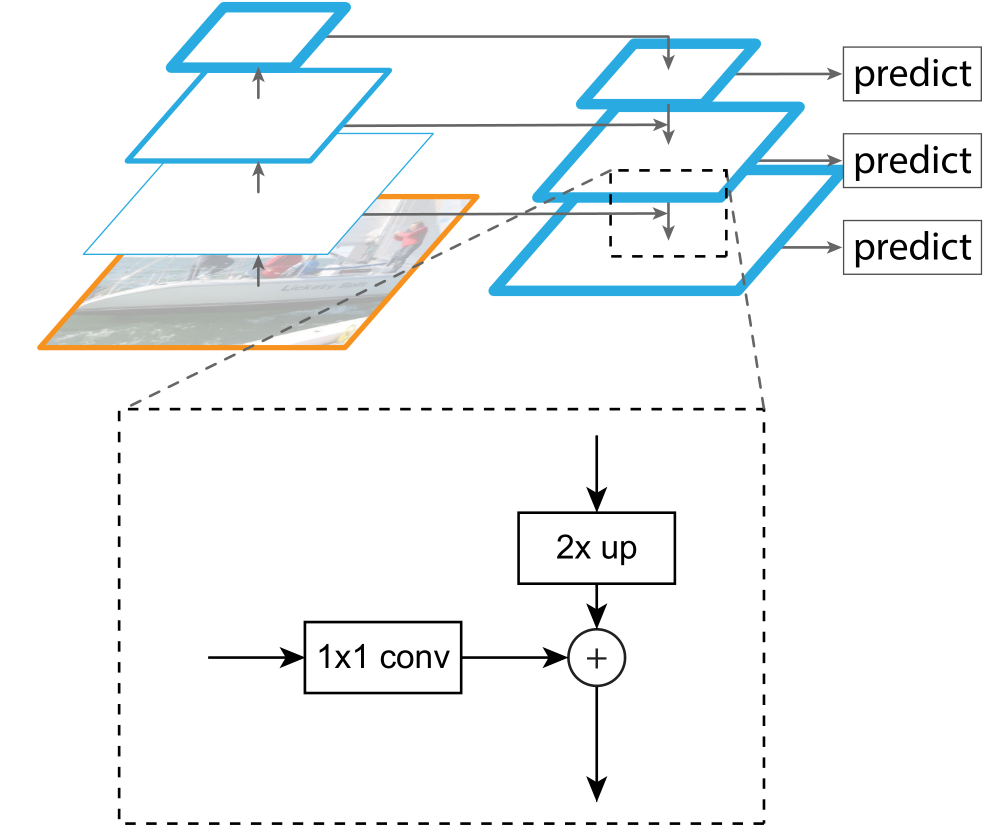
- 侧向连接通过 1x1 卷积并与经过上采样的从上到下连接的结果相加求和。
- 自上而下的部分生成粗粒度特征,自下而上的部分通过侧向连接加入细粒度特征
FPN with RPN
- FPN本身不是目标检测器。 它是一个与目标检测器配合使用的特征检测器。馈送每个独立的特征图以进行目标检测
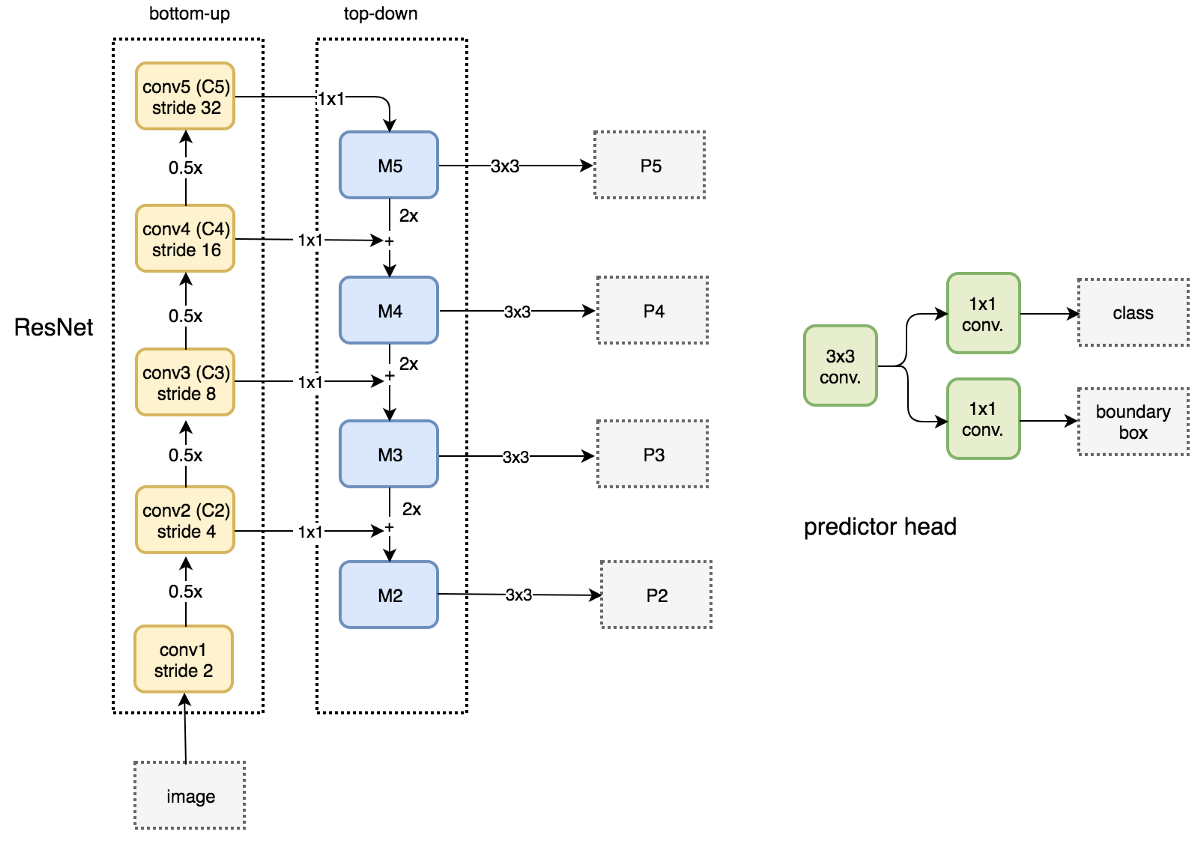
锚定框(Anchors )
- 作者使用平移不变锚定框。锚定框在金字塔等级P3至P7上分别具有322 至5122 的区域。 在每个金字塔等级,使用三个宽高比{1:2, 1:1, 2:1}的锚定框。 对于更密集的比例覆盖,在每个级别,添加原始3个宽高比为的锚定框。总的来说,每个级别有A = 9个锚定框,并且它们覆盖了相对于网络输入图像的尺度范围为32~ 813像素。
- 为每个锚定框指定一个长度为𝐾的分类目标的独热矢量(𝐾是目标类的数量) ,以及一个4元素向量的框回归目标。
- 使用0.5的(IoU)阈值将锚定框分配给GT框; 如果他们的IoU在[0,0.4]中,则为背景。
分类子网
- 分类子网对每个A个锚定框和K个目标类别在每个空间位置处预测目标存在的概率。 该子网是连接到每个FPN级别的小型FCN; 所有金字塔等级共享此子网的参数。 它的设计很简单。 使用来自给定金字塔等级的C个通道的输入特征图,子网应用四个3×3卷积层,每个都有C个滤波器,然后是ReLU激活,接着是带有KA个滤波器的3×3卷积层。
- 最后附加sigmoid激活以输出每个空间位置的KA个二元预测。 在大多数实验中使用C = 256和A = 9。
- 与RPN相比,这里的目标分类子网更深,仅使用3×3转换,并且不与框回归子网共享参数。
框回归子网
- 框回归子网:与目标分类子网并行,将另一个小FCN附加到每个金字塔等级,以便将每个锚定框的偏移量回归到附近的GT目标(如果存在的话)。
• 框回归子网的设计与分类子网相同,只是它在每个空间位置最终是4A个线性输出。 对于每个空间位置的A锚定框的每一个,这4个输出预测了锚定框和GT框之间的相对偏移。 这里使用的是类别无关的边界框回归, 它使用更少的参数,并同样有效。
• 目标分类子网和框回归子网虽然共享一个共同的结构,但使用单独的参数。
Inference and Training
- 为了提高速度,在将检测器置信度阈值设置为0.05后,仅解码每FPN级别最多1k最高得分预测的框预测。
- 合并所有级别的最高预测,并应用阈值为0.5的非最大抑制以产生最终检测。
焦点损失的计算
- 在训练RetinaNet时,焦点损失应用于每个采样图像中的所有~100k锚定框。
- 图像的总焦点损失被计算为所有~100k锚定框上的焦点损失的总和, 并用分配给一个GT框的锚定框的数量来归一化。
- 通过分配锚定框的数量而不是总的锚定框来执行归一化,因为绝大多数锚定框都是容易的负样本并且在焦点损失下获得可忽略的损失值。
语义分割
FCN
DeconvNet
SegNet
U-Net
DeepLab-v1
DeepLab-v2
DeepLab-v3
RefineNet
PSPNet
GCN
实例分割
Mask R-CNN
全景分割
Panopatic FPN
循环神经网络RNN
- RNN (Recurrent Neural Network),可用于图像描述(一对多),情感分析(多对一),机器翻译(多对多),视频逐帧分类(多对多)
- 循环神经网络具有“环”,允许信息持续存在
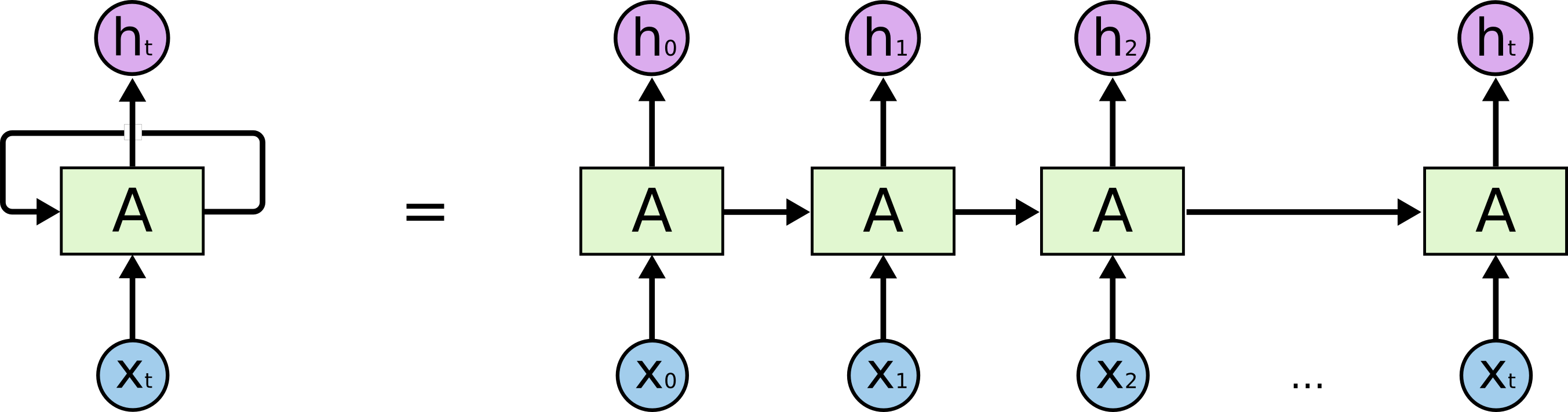
-
-
:new state
-
:function parameterized by w,RNN更新选择使用tanh函数
-
:old state
-
:input vector
-
输出:
-
隐藏层状态::
-
梯度爆炸:反向传播计算h0时,会多次进行Whh和f’,矩阵奇异值比较大就会梯度爆炸,解决方法就是梯度裁剪
-
一种方法就是小批量的裁剪
-
另一种方法就是裁剪一个摩norm||g||:
-
梯度消失:奇异值小于1时,多次相乘则会产生梯度消失。
RNN
- 在标准RNN中,该重复模块具有非常简单的结构,例如单个tanh层。
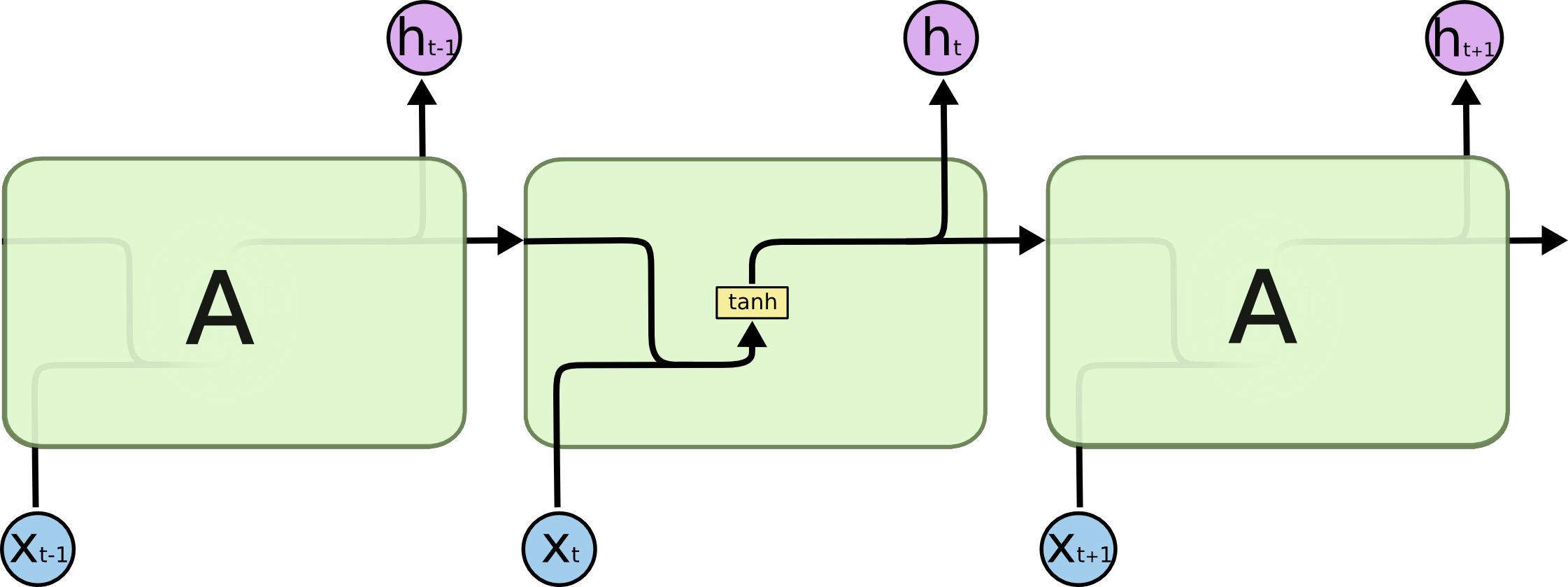
- 隐藏层状态::
lstm
- 使用门控制单元,跟踪信息,对长期信息的依赖问题能够很好解决
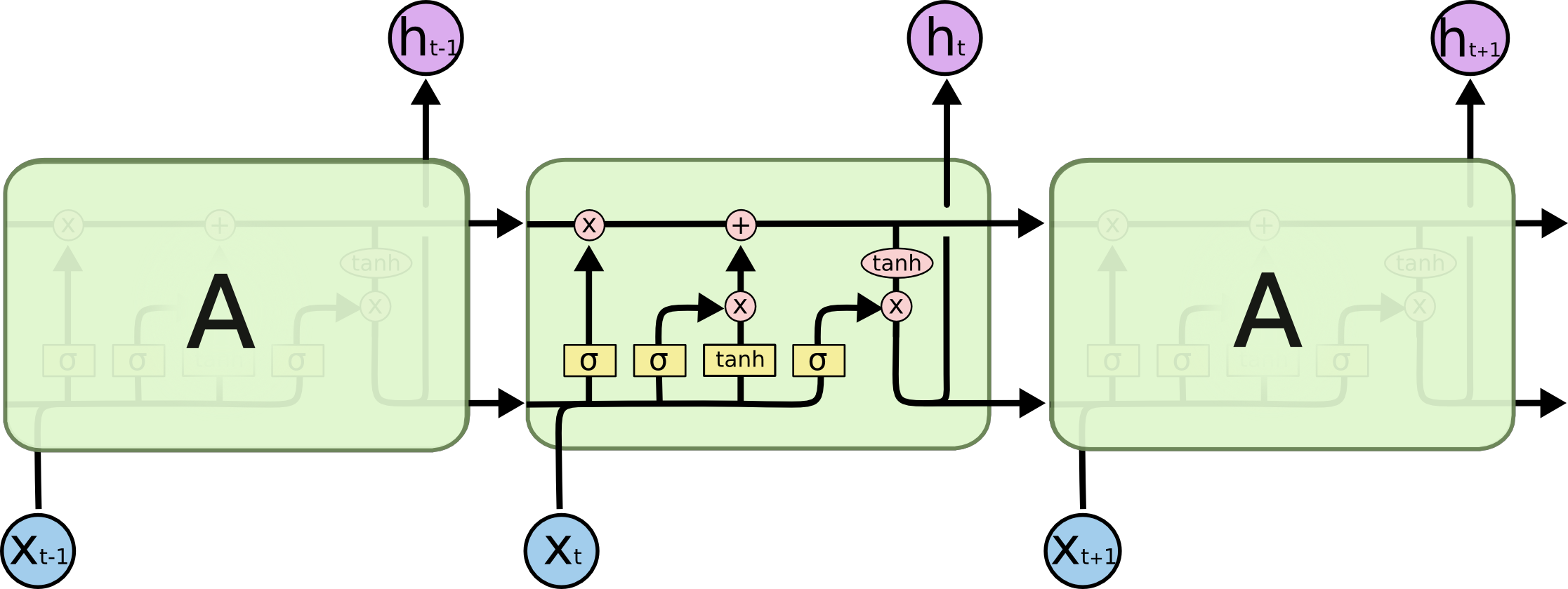
-
LSTM的关键是单元状态(cell state), 水平线贯穿图的顶部。单元状态有点像传送带。 它直接沿着整个链运行, 只有一些小的线性相互作用。信息很容易沿着它不变地流动。这个结构对梯度消失有很好的抑制。
-
LSTM能够移除或添加信息到单元状态, 由称为门的结构调节。门是一种可选择通过信息的方式。 它们由Sigmoid神经网络层和逐点乘法运算组成。sigmoid层输出0到1之间的数字, 描述每个组件应该通过多少。 值为零意味着“不让任何东西通过” , 而值为1则意味着“让一切都通过”
-
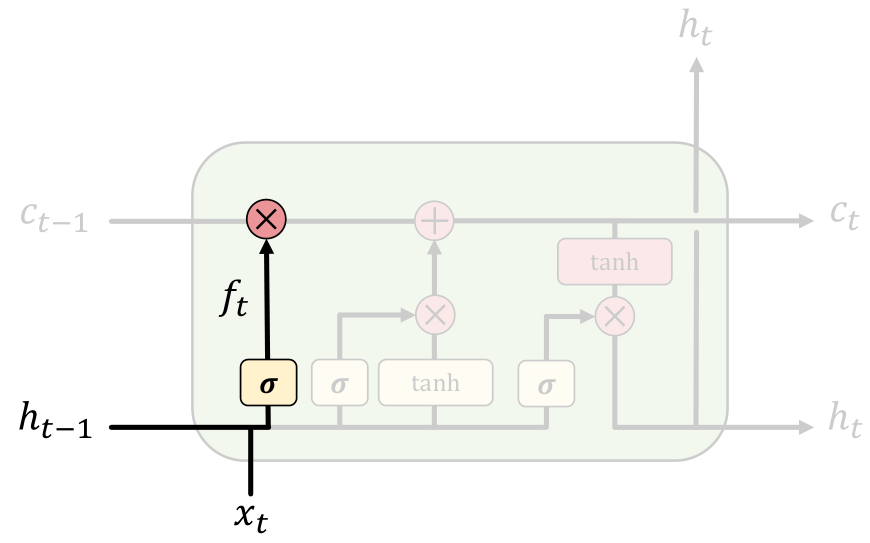
遗忘门:,遗忘门查看ℎ𝑡−1和𝑥𝑡 ,并为𝐶𝑡−1输出0到1之间的数字。 1代表“完全保留”,而0代表“完全遗忘”。
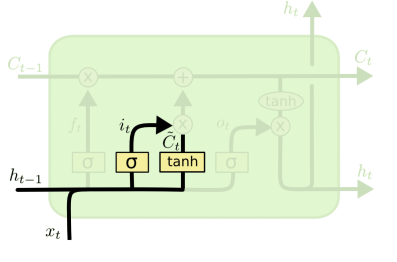
- 输入门:确定在单元状态中存储哪些新信息 ,更新旧的单元状态C_{t-1}到新的单元状态C_t,将旧状态乘以𝑓𝑡,忘记之前决定遗忘的事情然后加上缩放后的候选值
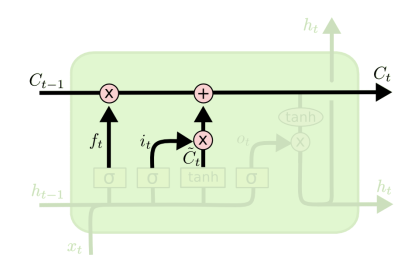
- 输出门:要输出的内容 ,输出将基于单元状态(cell state),但将是滤波后的版本
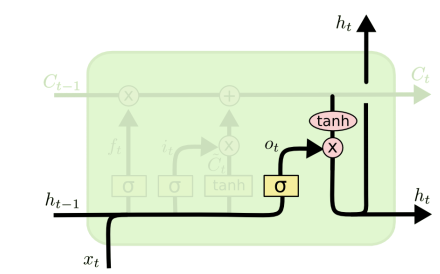
GRU
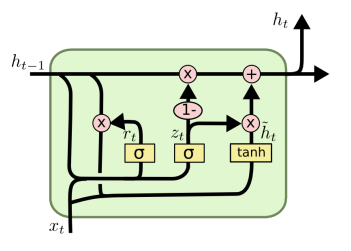
- GRU模型是LSTM模型的简化版,仅包含两个门函数(reset gate和update gate)。reset gate决定先前的信息如何结合当前的输入, update gate决定保留多少先前的信息。如果将reset全部设置为1,并且update gate设置为0,则模型退化为RNN模型。
生成对抗网络GAN
- GAN (Generative Adversarial Network)