降维
谱定理spectral theorem
- 谱定理是线性代数中很重要很基础的定理,并为以后的特征值分解做准备
- 谱定理:设A是nxn满秩对称矩阵,存在正交向量u,Aui=λiui,满足下面的等式:
- A=UΛUT=∑i=1nλiuiuiT,Λ=diag(λ1,⋯,λn)
- 其中:UUT=UTU=I
瑞利商
- Rayleigh Quotient定义函数为瑞丽商
- R(A,x)=xHxxHAx
- 其中x为非零向量,而A为n×n的Hermitan矩阵。所谓的Hermitan矩阵就是满足共轭转置矩阵和自己相等的矩阵,即AH=A。如果我们的矩阵A是实矩阵,则满足AT=A的矩阵即为Hermitan矩阵。
- 瑞利商R(A,x)有一个非常重要的性质,即它的最大值等于矩阵A最大的特征值,而最小值等于矩阵A的最小的特征值,也就是满足
- λmin≤xHxxHAx≤λmax,∀x=0
- λmax(A)=maxx:∣∣x∣∣2=1xTAx
- λmin(A)=minx:∣∣x∣∣2=1xTAx
- 解释瑞丽商就是:经过x和xT旋转变换后的最大最小值是多少,旋转不会改变特征值的大小
- 当向量x是标准正交基时,即满足xHx=1时,瑞利商退化为:R(A,x)=xHAx,这个形式在谱聚类和PCA中都有出现。
SVD
-
有一个m×n的实数矩阵A,我们想要把它分解成如下的形式:
- A=UΣVT
- 其中U和V均为单位正交阵,即有UUT=I和VVT=I,U称为左奇异矩阵,V称为右奇异矩阵,Σ仅在主对角线上有值,我们称它为奇异值,其它元素均为0。上面矩阵的维度分别为U∈Rm×m, Σ∈Rm×n, V∈Rn×n。
-
一般地Σ有如下形式
- Σ=⎣⎢⎢⎡σ10000σ20000⋯00000000⋯0000⎦⎥⎥⎤m×n
-
正常求上面的U,V,Σ不便于求,我们可以利用如下性质:
- AAT=UΣVTVΣTUT=UΣΣTUT(2-2)
- ATA=VΣTUTUΣVT=VΣTΣVT(2-3)
- 注:需要指出的是,这里ΣΣT与ΣTΣ在矩阵的角度上来讲,它们是不相等的,因为它们的维数不同ΣΣT∈Rm×m,而ΣTΣ∈Rn×n,但是它们在主对角线的奇异值是相等的
- ΣΣT=⎣⎢⎢⎡σ10000σ20000⋯0000⋯⎦⎥⎥⎤m×m,ΣTΣ=⎣⎢⎢⎡σ10000σ20000⋯0000⋯⎦⎥⎥⎤n×n
-
可以发现AAT和ATA也是对称矩阵,那么可以利用式(1-1),做特征值分解。利用式(2-2)特征值分解,得到的特征矩阵即为U;利用式(2-3)特征值分解,得到的特征矩阵即为V;对ΣΣT或ΣTΣ中的特征值开方,可以得到所有的奇异值。
PCA & Kernel PCA
Kernel PCA可以理解为,先通过非线性变换,将点云投影到高维空间中,然后在高维空间中做PCA。但这个非线性变换函数很难找,所以通过数学变换,改写,用核方法表示。使用常用的,多项式的核,高斯的核就可以实现Kernel PCA。
PCA步骤
- 输入:x∈Rn,i=1,2,⋯,m
- 输出:最主要的特征向量z1,z2,⋯,zk∈R,k≤n
- 将数据归一化
- X~=[x1~,⋯,xm~]
- 其中:xi~=xi−xˉ,i=1,⋯,m
- xˉ=m1∑i=1mxi
- 计算得到最大的方差时的投影方向z,z∈Rn,∥z∥2=1
- 投影:ai=x~iTz
- 计算投影的方差,由于数据中心化,方差为数据的平方和
- m1∑i=1mai2=m1∑i=1mzTx~ix~iTz=m1zTX~X~Tz
- 转化为求最值的问题:
- maxz∈RnzT(X~X~T)z,s.t.∥z∥2=1
- 根据瑞丽熵:
- λmin(A)≤xTxxTAx≤λmax(A),∀x=0
- 谱定理:
- A=UΛUT=∑i=1nλiuiuiT,Λ=diag(λ1,⋯,λn)
- 最值问题可以转为求解特征值特征向量
- H=X~X~T=UrΣ2UrT
Kernel PCA
- 例如原始数据为两组,一组是二维的圆上的数据,一组为圆心周围的数据,数学表达为:xi=[xi1,xi2]∈R2
- 增加一个维度,就是数据相对原点的距离:xi=[xi1,xi2,xi12+xi22]∈R3
- 此时变为三维空间后,就可以很好的分类两组数据
| 核函数 |
公式 |
| Linear |
k(xi,xj)=xiTxj |
| Polynomial |
k(xi,xj)=(1+xiTxj)p |
| Gaussian |
k(xi,xj)=e−β∥xi−xj∥2 |
| Laplacian |
k(xi,xj)=e−β∥xi−xj∥1 |
法向量估计
- Surface Normal就是PCA中中最后一维的向量(也就是方差最小的向量z),将点云做PCA,最后一个主成分就是法向量的方向,curvature也与PCA中最小的特征值有关。
法向量计算步骤
滤波
去噪
Radius Outlier Removal
- 在每个点计算半径r内是否相邻指定的点,不包含则丢弃
Statistical Outlier Removal
- 计算所有点半径r内每个邻居的距离的平均值和方差,再对每个点计算邻居,大于3σ则认为是噪声
下采样
Voxel Grid Downsampling
- pcl库中使用排序的方法,时间时间复杂度是O(NlogN),如果使用哈希表,其实感觉就像是桶排序,可以做到O(N)
- 分成指定网格,再在网格中取一个点代表这个网格,选择方法:平均值、随机点
FPS
- Farthest Point Sampling,可以将比较密集的点去除
- Randomly choose a point to be the first FPS point
- Iterate until we get the desired number of points
- For each point in the original point cloud, compute its distance to the nearest FPS point
- Choose the point with the largest value, add to FPS set
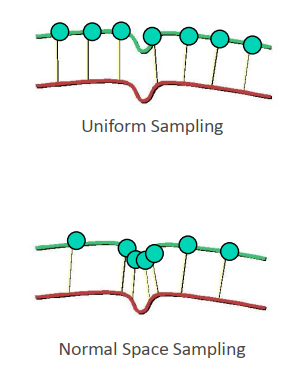
Normal Space Sampling
DeepLearning:《learning to sample》
上采样
Bilateral Filter – Gaussian Filter
- 对像素值与周围进行平均,可以对图像进行平滑,但是会将边缘丢失。
- 高斯核:Gσ(x)=2πσ21exp(−2σ2x2)
- Bilateral Filter使用了两个高斯核,当是边缘时,权重会比较小
- BF[I]p=Wp1∑q∈SGσs(∥p−q∥)Gσr(Ip−Iq)Iq
- 其中:Wp=∑q∈SGσs(∥p−q∥)Gσr(Ip−Iq)
最近邻Nearset Neighbor Problem
Binary Search Tree
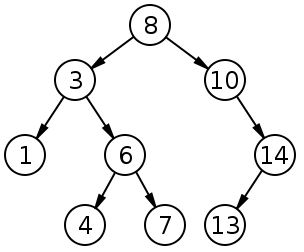
KD-Tree

-
KD-Tree:k-dimensional tree,高维度的二叉树,每个维度切一刀
-
切法:
- 轮流切,xyzxyz
- adaptive,按照点的分布切
-
两种速度差别并不是很大,结果是一样的。
-
构建速度,最快O(nlogn),使用O(n)的求中值的方法,但很复杂。有以下两个trick:
- 找中值时,不用某个区域的全部点,而是只用一部分
- 用平均值代替中值
-
这两个trick生成的树不是平衡树,但用起来还算可以
-
查找时需要根据worst-distance判断查找范围
Octree
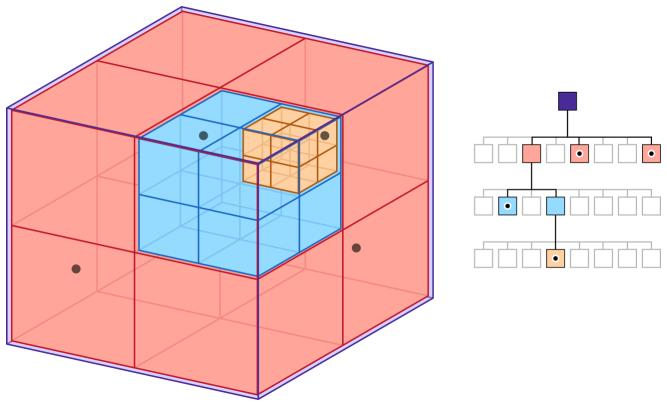
- 专门为三维数据设计的,在最近点搜索中比较高效的原因是,可以提前终止搜索。使用KD-Tree,无论如何都会返回到root。
- 构建八叉树的时候,要确定leaf_size和最小边长。
聚类
k-means
步骤
- 𝑁 input data points, find 𝐾 clusters.
- 输入:𝑥1, ⋯ , 𝑥𝑁 , 𝑥𝑛 ∈ ℝ𝐷
- Randomly select K center points
- Each data point is assigned to one of the K centers. Cluster center 𝜇𝑘, 𝑘 = 1, ⋯ 𝐾。
- 𝜇𝑘 is the center of 𝑘𝑡ℎ cluster
- Re-compute the K centers by the mean of each group
- Iterate step 2 & 3. Objective of K-Means is to minimize the distortion measure:
- J=∑n=1N∑k=1Krnk∥xn−μk∥2
Tricks
- 选择数据中的点作为初始化点,而不是随机选点
- 由于K-menas选点的初始值有关,所以跑几次K-menas,选择惩罚函数最小的一次作为结果
- Mini-Batch K-means
- Sequential K-means
- 欧氏距离不能用,就不能用K-menas,因为其要求平均值
k-medoids
- 对kmeans加强,为了增加对噪声的鲁棒性,不要求距离函数可导
- k中心点,将第i各类中的所有点,分别遍历其他所有点距离和最小的点作为类中心
GMM
高斯模型
GMM
-
在现有x分布的状态下,类别z的概率分布:p(z∣x)=p(x)p(x∣z)p(z)
- 其中:p(x)=∑zp(z)p(x∣z)
- GMM是有向图,通过z来判断x:p(x,z)=p(z)p(x∣z)
- p(zi=1)=πi,π∈[0,1],∑i=1Kπi=1
- p(z)=∏i=1Kπizi
-
GMM表达的K个高斯模型的线型组合,每个模型包含三个参数:
- p(x)=∑k=1KπkN(x∣μk,Σk)
- μ,Σ高斯的参数
- π高斯模型的权重
-
求解GMM时,也是用EM迭代优化得到GMM的参数
-
K-means只是GMM的一个特例:GMM中每个高斯模型的方差都趋于0
K-means的优劣
- 优点:简单,快速
- 缺点:1)认为类别是各向同性的,2)需要预先确定K,3)易受初始化影响,4)对噪声铭感
EM
- EM不是特定于针对GMM的算法,而是针对求最大似然估计的方法,最大似然估计是要求
maxp(θ∣X)。通过在p(θ∣X)引入预测的label,变成p(θ,Z∣X)。通过最大化来求取模型参数θ。
步骤
- 选择初始化的参数θold
- E-step:估计p(Z∣X,θold)
- M-step:根据优化问题,估计θnew
- θnew=argmaxθQ(θ,θold)
- Q(θ,θold)=∑zp(Z∣X,θold)lnp(X,Z∣θ)=Ez[lnp(X,Z∣θ)]
- 由于P(θ∣X)不好求,所以转为求上图中的Q,Q中的第一项就是给了模型估计点的label,很方便,第二项的求法是将p(X,Z∣X)=p(Z∣θ)p(X∣Z,θ),其中第一项是label的分布,在GMM中就是每个GM的权重,第二项是数据的先验分布。
Spectral Clustering
- 谱聚类先构建一个图,计算点与点之间的关系。用每个点与其他点的联系的权重组成的向量作为改点的vector。对所有点的vector进行压缩,然后使用压缩后的特征值进行k-menas。
- 不归一的谱聚类倾向于每个类中点的数量相似。
- Build the graph to get adjacency matrix 𝑊 ∈ ℝ𝑛×𝑛
- Compute unnormalized Laplacian 𝐿
- Compute the first (smallest) 𝑘 eigenvectors 𝑣1, ⋯ , 𝑣𝑘 of 𝐿
- Let 𝑉 ∈ ℝ𝑛×𝑘 be the matrix contraining the vectors 𝑣1,⋯ , 𝑣𝑘 as columns
- For 𝑖 = 1,⋯ 𝑛 , let 𝑦𝑖 ∈ ℝ𝑘 be the vector corresponding to the 𝑖-th row of 𝑉
- Cluster the points {𝑦𝑖 ∈ ℝ𝑘} with k-means algorithm into clusters 𝐶1,⋯ , 𝐶𝑘
- The final output clusters are 𝐴1, ⋯ ,𝐴𝑘 where 𝐴𝑖 = {𝑗|𝑦𝑗 ∈ 𝐶𝑖}
- 归一化的谱聚类倾向于每个类中点的密度相似。
- Build the graph to get adjacency matrix 𝑊 ∈ ℝ𝑛×𝑛
- Compute normalized Laplacian 𝐿′ = 𝐿𝑟𝑤
- Compute the first (smallest) 𝑘 eigenvectors 𝑣1, ⋯ , 𝑣𝑘 of 𝐿′
- Let 𝑉 ∈ ℝ𝑛×𝑘 be the matrix contraining the vectors 𝑣1,⋯ , 𝑣𝑘 as columns
- For 𝑖 = 1,⋯ 𝑛 , let 𝑦𝑖 ∈ ℝ𝑘 be the vector corresponding to the 𝑖-th row of 𝑉
- Cluster the points {𝑦𝑖 ∈ ℝ𝑘} with k-means algorithm into clusters 𝐶1,⋯ , 𝐶𝑘
- The final output clusters are 𝐴1, ⋯ ,𝐴𝑘 where 𝐴𝑖 = {𝑗|𝑦𝑗 ∈ 𝐶𝑖}
- 谱聚类可以自适应的选择类别的多少。
- 缺点:复杂,慢
- 优点:1)不对类的预先形状做假设,2)对任意维度的数据都可以处理,3)可以自动找出需要聚成多少个类
Mean Shift
Mean Shift步骤
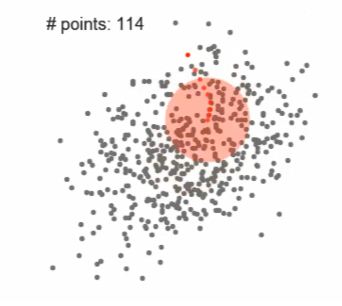
- 放置一个圆,计算圆的均值的位置,将圆的中心更新,继续计算直到稳定
做聚类的方法
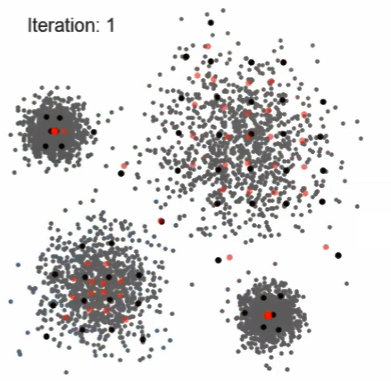
- Randomly select a circle with radius 𝑟
- Move the circle to the center of the points inside
- Repeat step-2 until it doesn’t move
- Repeat step-1,2,3. Remove overlapping circles
- If circles overlap, select the one with most points
- Determine clusters by finding the nearest circle center (similar to k-means)
特点
- 不需要预先确定有多少个类
- 复杂度:O(Tnlgn)
- 还是认为类的分布是椭圆的,爬山也不一定爬到最优的中心
- 对高维稀疏的情况,设定R不易确定
DBSCAN
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
步骤
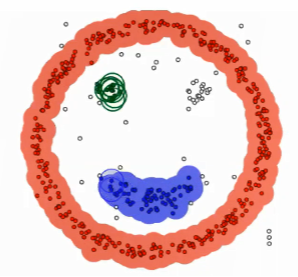
- Preparation: all points labeled as unvisited
- Parameters: distance 𝑟, min _samples
- Randomly select a unvisited point 𝑝, find its neighborhood within 𝑟
- Number of points within 𝑟 ≥ min _𝑠𝑎𝑚𝑝𝑙𝑒𝑠?
- Yes. 𝑝 is a core point, Create a cluster 𝐶, go to step 3, mark 𝑝 as visited.
- No. Mark 𝑝 as noise and visited.
- Go through points within its 𝑟-neighborhood, label it as 𝐶
- If it is a core point, set it as the “new 𝑝”, repeat step-3
- Remove cluster 𝐶 from the database, go to step-1
- Terminate when all points are visited.
特点
- 同样不需要预先确定有多少类
- 与Spectral Clustering同为是考虑连接的,不假设类别是椭圆的。
模型拟合
最小二乘
- 拟合线性关系
- E=∑i=1n(axi+byi+c)2,求解abc,使得E最小
- 矩阵形式:
- minE=∥Ax∥22,s.t.∥x∥2=1
- A=⎣⎢⎡x1⋮xny1⋮yn1⋮1⎦⎥⎤
- x=[a,b,c]T
- 在A满秩的情况下,求解x=(ATA)−1ATb
噪声处理
- 2范数对噪声敏感,可以使用不同的优化函数,减小噪声的干扰
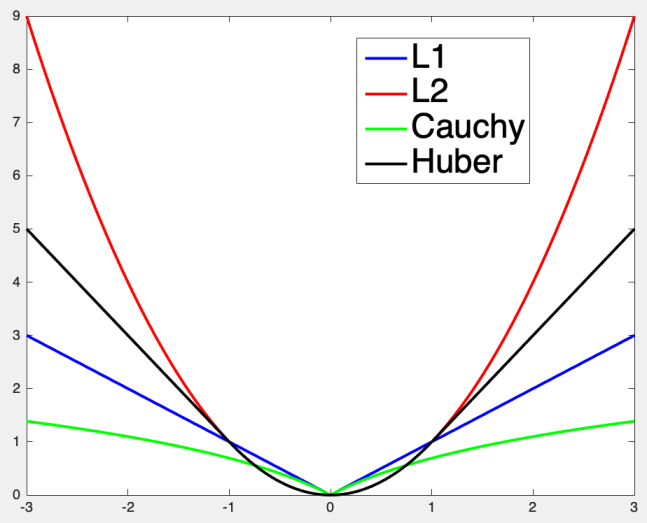
| 优化函数 |
公式 |
| L1 |
ρ=∥s∥ |
| L2 |
ρ=s2 |
| Cauchy |
ρ=log(1+∥s∥) |
| Huber |
ρ={s2,2δ(∥s∥−21δ),∥s∥<δotherwise |
- 使用了优化的损失函数,可以用梯度下降、高斯牛顿、LM方法求解最优解
-
使用极坐标表示直线,防止斜率k无穷大时无法表示的问题
- xcosθ+ysinθ=r
-
对每个θ,r进行计算x’,y’,与原始的x,y进行匹配,找到最合适的参数解
-
其他形状也同样使用
-
只适用于低维空间,否则计算量太大,一般要求模型参数<=3
RANSAC
步骤
- 随机选择一个sample,用于表征模型所需的最小的点的个数
- 根据sample建立模型,计算a,b
- 计算其余的点与模型的距离:
- 点到直线的距离:di=∥n∥2nT(pi−p0)
- n表示法线向量
- 计算某个接收区间的点的个数:
- 重复n次,找到接收最多的参数模型
τ的设定
-
τ的设定可以由实验获得,但使用χ2分布并不靠谱,一般用经验确τ的值。
-
假设点到模型的距离符合高斯分布,d∼N(0,δ2)
-
χ2分布:k个标准正态分布的和,假设在95%置信区间内满足点在区域内,则:
- 1维:τ=3.84δ2
- 2维:τ=5.99δ2
- 3维:τ=7.81δ2
N的设定
- 定义概率p,做N次sample,都在接受区间的概率,当p至少为0.99的时候的N,为最佳的N
- (1−(1−e)s)N=1−p
- 其中:e:拒绝点的ratio
- s:sample的点的个数
- N:迭代次数
- p:置信度至少一次得到最近加sample的概率
- 1-p:一次好的都拿不到
- 得到:
- N=log(1−(1−e)s)log(1−p)
提取特征点
Harris 2D
定义
-
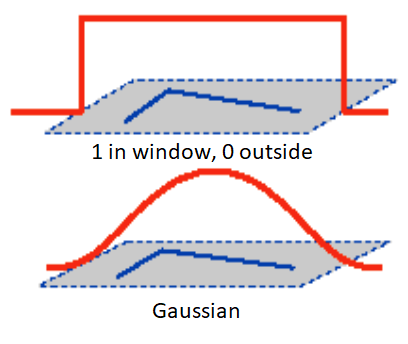
给定图像I上一点(x,y)视野移动(u,v)时变化为:
- E(u,v)=∑x,y∈Ωw(x,y)[I(x+u,y+v)−I(x,y)]2
- 其中w(x,y)表示对x,y方向上的权重
-
-
u和v足够小时,上式可以等价于求导,使用一阶泰勒展开:
- f(x+u,y+v)≈f(x,y)+ufx(x,y)+vfy(x,y)
-
忽略w,令w(x,y)=1,使用一阶泰勒近似,上式可简化为:
- E(u,v)≈∑x,y∈Ω[I(x,y)+uIx+vIy−I(x,y)]2=∑x,y∈Ωu2Ix2+2uvIxIy+v2Iy2
- =∑x,y∈Ω[uv][Ix2IxIyIxIyIy2][uv]
-
此时移动一个方块图像的变化可表示为:
- E(u,v)≈[uv]M[uv]
- M为协方差矩阵:M=∑x,y∈Ω[Ix2IxIyIxIyIy2]
-
通过协方差矩阵的特征就可以判断是否是角点,因为其在x,y方向上都有较大的一阶导数变化
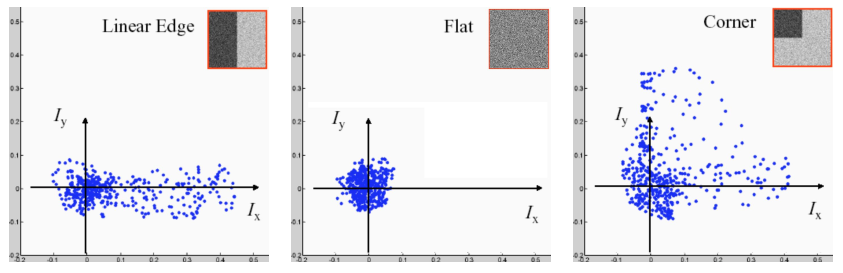
-
求M的特征值特征向量,令R=min(λ1,λ2)
Harris 3D&6D
数学表达
-
同理,对于3D空间的特征定义变换的方程
- E(u,v,w)=∑x,y,z∈Ω[I(x+u,y+v,z+w)−I(x,y,z)]2
- 一阶近似:E(u,v,w)≈[uvw]M⎣⎡uvw⎦⎤
- M为协方差矩阵:M=∑x,y,z∈Ω⎣⎡Ix2IxIyIxIzIxIyIy2IyIzIxIzIyIzIz2⎦⎤
-
计算IxIyIz的方法:
-
定义
- p为要分析的点
- 邻居域Ω,包含点集:xi=[xi,yi,zi]
- p的梯度向量e=[ex,ey,ez]T∈R3
-
p点和其邻域的点的关系:
- (x1−px)ex+(y1−py)ey+(z1−pz)ez=I(x1,y1,z1)−I(px,py,pz)
- 向量化:xiT′e=△li
- xi′=[xi′,yi′,zi′]T=[xi−px,yi−py,zi−pz]T]
- △li=I(x1,y1,z1)−I(px,py,pz)
-
多个邻域的点组合,得到矩阵
- Ae=b
- 当A满秩可逆,可得e=(ATA)−1ATb
-
得到e就可以得到每个方向上的一阶梯度,用以得到M矩阵
-
求M的特征值特征向量,令R=λ2
e的优化
- 对于e,可以用一阶导数,也就是切面的梯度进行近似
- 根据邻域得到切平面:
- ax+by+cz+d=0
- 法向量:n=[nxnynz]=∥[a,b,c]∥2[a,b,c]T
距离的方法
- 对于雷达没有intensity时,无法获得b,此时,根据某个平面的距离作为b
- 要计算的p的切面法向量为n,对p做(u,v,w)移动后,相对切面变化的距离作为b
- 其M的表示为:
- M=∑x,y,z∈Ω⎣⎡nx2nxnynxnznxnyny2nynznxnznynznz2⎦⎤
- 求M的特征值特征向量,令R=λ3
6d
-
协方差矩阵[Ix,Iy,Iz,nx,ny,nz]
-
求M的特征值特征向量,令R=λ4
-
Harris3D分为使用intensity的和使用距离的两种。
-
使用intensity的方式,求得的梯度,投影到局部平面更好
-
Harris6D,把intensity和法向量结合起来
ISS(Intrinsic Shape Signatures)
- 在邻域内点分布变化很大的地方。就是把邻域内的点拿出来,求协方差矩阵,然后再做特征值分解,找最小的特征值。
步骤
- 在r的范围内计算每个点的协方差矩阵
- 点的权重
- wj=∥{pk:∥pk−pj∥2<r}∥1
- 加权协方差
- cov(pi)=frac∑∥pj−pi∥2<rwj(pj−pi)(pj−pi)T∑∥pj−pi∥2<rwj
- 得到特征值λi1,λi2,λi3由大到小
- 判断是否是特征点:
- λi1λi2<γ21,λi2λi3<γ32
- 平面的约束为:λi1=λi2>λi3
- 直线:λi1>λi2=λi3
- 要确保:λi1>λi2>λi3
- NMS最大值抑制,选取λi3,最小特征值比较大
USIP
- 一个物体提取的特征点,在任意角度看仍然是特征点
- 特征点具有尺度不变性
描述子

- 深度学习方法:
- 3DMatch & Perfect Match
- Perfect Match
- PPFNet & PPF-FoldNet
PFH & FPFH
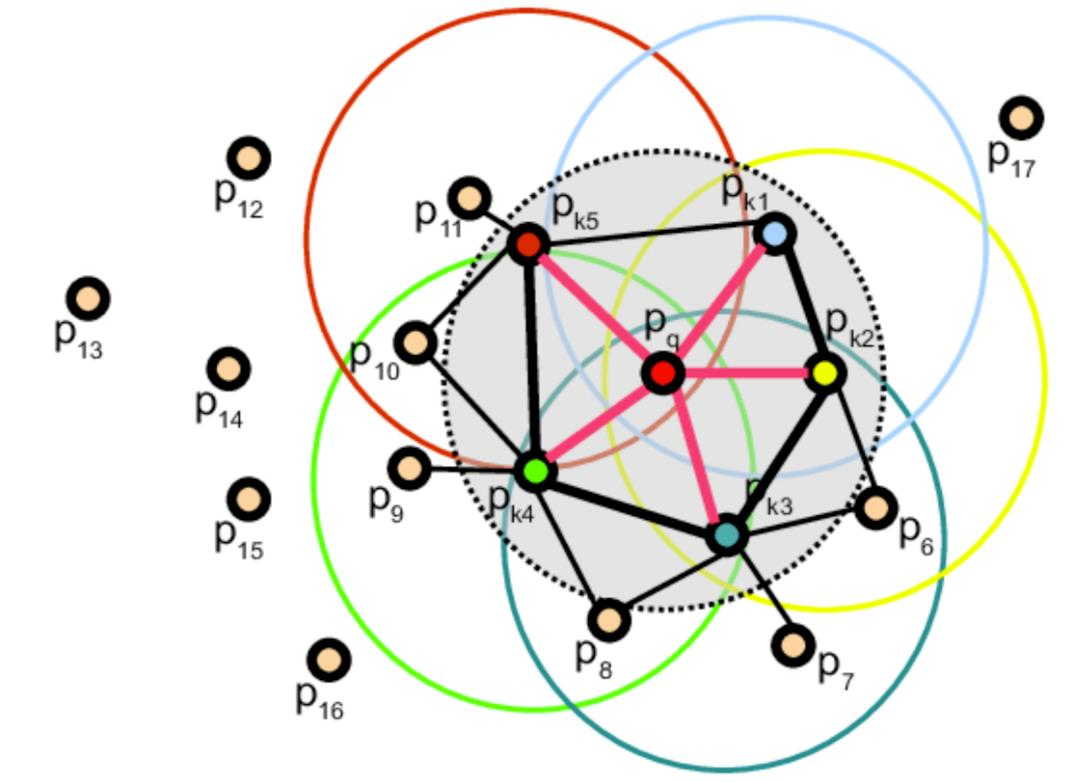
步骤

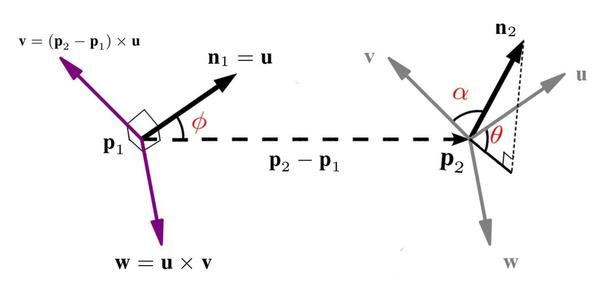
- 一对点p1和p2,其法向量分别为n1,n2,通过法向量和两点连线建立坐标系
- u=n1
- v=u×∥p2−p1∥2p2−p1
- w=u×v
- 四个特征:
- d=∥p2−p1∥2
- α=v⋅n2
- ϕ=u×∥p2−p1∥2p2−p1
- θ=arctan(w⋅n2,u⋅n2)
- 一般情况下,由于激光雷达数据近密远疏的性质,d的效果比较差,所以不做考虑,所以描述子可以表述为:
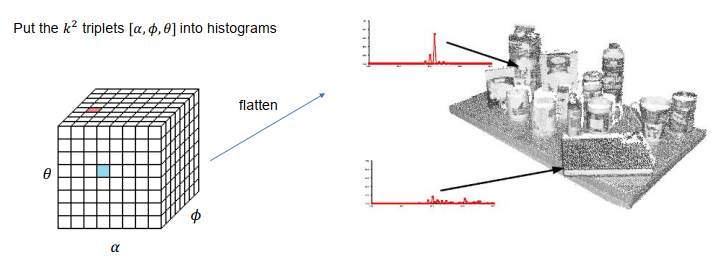
- 在某个点的邻域内,有k个点,每对点的法向量的特征:α,ϕ,θ,一共k2个信息
- 以三维角度作为数据,每个角度有B个bin格子,建立B3的立方体的直方图,将k2的信息放入直方图
- 复杂度:O(nk2)
-
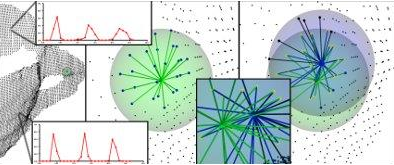
只对某个点和邻域的点组合,不再两两组合,同样得到三元组SPFH:α,ϕ,θ
-
再与每个邻居的SPFH加权求和
- FPFH(pq)=SPFH(pq)+k1∑i=1kwk⋅SPFH(pk)
- 其中:wk=∥pq−pk∥21
-
以每个角度为数据,B个bin格子,建立3个直方图,然后进行拼接,得到3B宽度的直方图
-
复杂度:O(nk)
-
直方图3B
SHOT
- 使用加权的协方差矩阵做特征值分解,得到局部坐标系LRF
- M=∑i:di≤R(R−di)1∑i:di≤R(R−di)(pi−p)(pi−p)T
- 其中:di=∥pi−p∥2
- 计算三个特征向量作为坐标系:x+,y+,z+,x−,y−,z−
- 正负判断的标准是看哪边的点多:
- Sx+={i:di≤R∧(pi−p)⋅x+≥0}
- Sx−={i:di≤R∧(pi−p)⋅x−>0}
- x={x+,x−,∥Sx+∥≥∥Sx−∥otherwise
- z轴通过叉乘求得
- 按照这个局部坐标系把邻域分成一些小块
- 用法向量来计算每个小块中直方图的特征
- 使用插值实现软投票,解决boundary effect
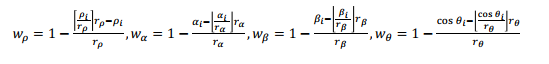
3DMatch
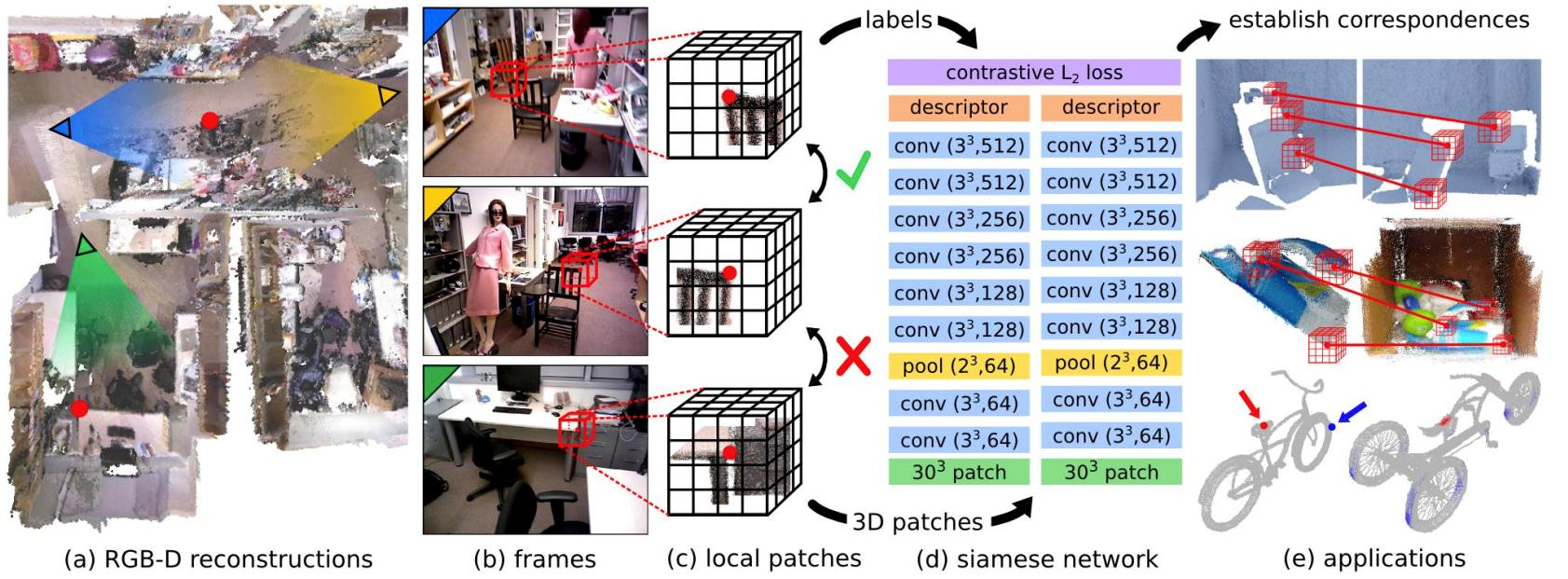
- 在特征点周围建立局部的voxel,然后放到神经网络里面
- 在不同视角下的相同点,做同样操作,得到positive的feature
- 在不同点得到negative的feature
- 用feature的距离代表相似程度
- 使得negative的feature距离大,positive的feature距离近
- Contrastive Loss:L=N1∑n=1Nyijdij2+(1−yij)max(τ−dij,0)2,dij=∥f(xi)−f(xj)∥2
局限
- 对旋转过于敏感
- loss约束过于强
改进
1)建立局部坐标系,对于旋转是稳定的,然后在局部坐标系中简历voxel
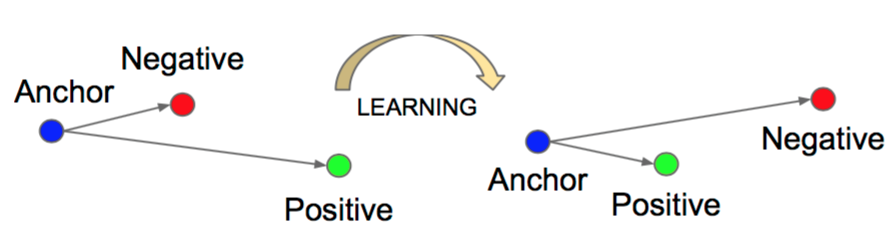
2)使用 triplet loss,如何找到难度适中的三元组。
- L=∑i=1Nmax(di(a,p)−di(a,n)+γ,0)
- 其中:γ是margin,把positive和negative拉的相对远一些,同时positive可以不那么重合
Perfect Match
- 使用PCA建立局部坐标系LRF
- ΣS^=∑∥S∥(R−di)1∑p∈S(pi−p)(pi−p)T
- 根据点的数量确定正方向
- 使用triplet loss
PPFNet

- PPFNet结合了全局信息和局部信息,考虑了patch对patch的triplet loss

- PFH包含四个信息:
- ψ12=(∥d∥2,∠(n1,d),∠(n2,d),∠(n1,n2))
- ∠(n1,n2)=atan2(∥v1×v2∥,v1⋅v2)

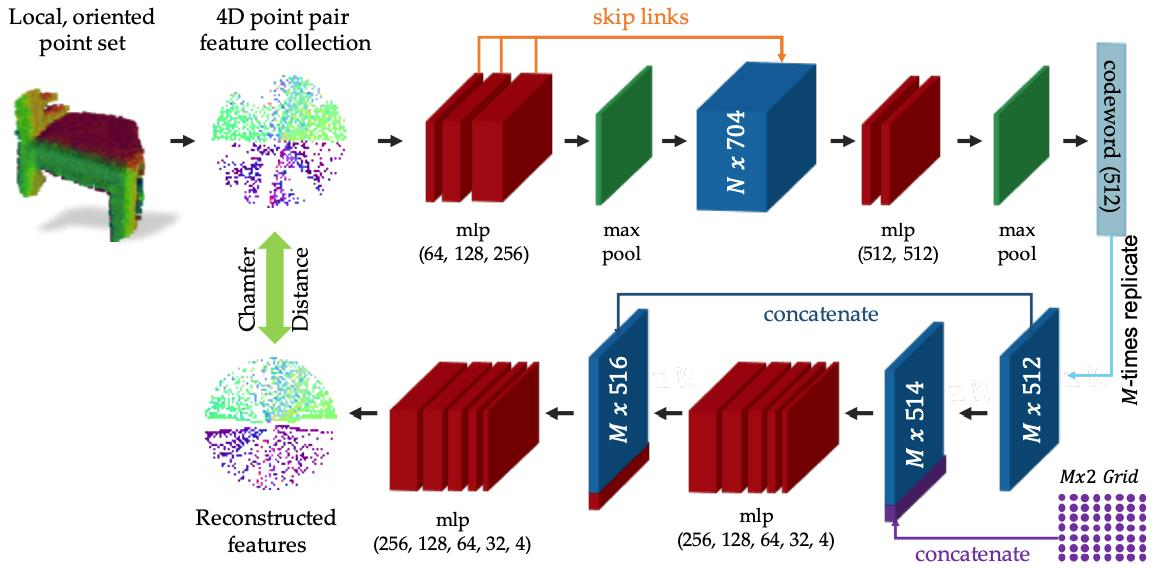
PPF-FoldNet
- PPF-FoldNet使用了autoencoder
- decoder-encoder
Registration
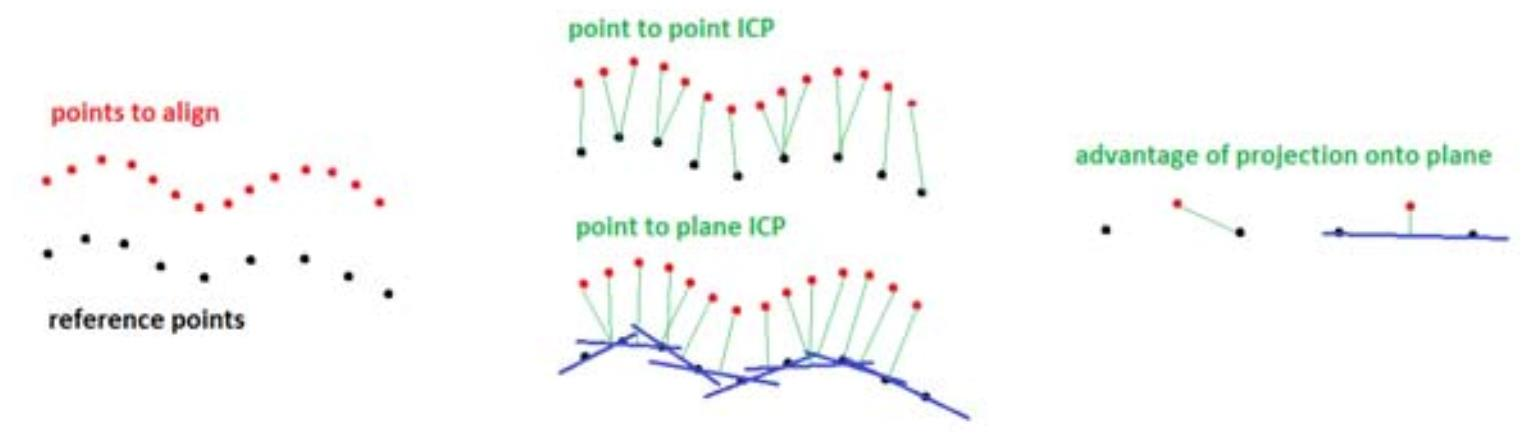
ICP
- correspondence是根据两个点的距离计算。
- 简单,但是需要初始化𝑅, 𝑡
步骤
- Given two corresponding point sets:
- 𝑃 = {𝑝1, ⋯ , 𝑝𝑁}, 𝑝𝑖 ∈ ℝ3, we are transforming 𝑃 (source)
- 𝑄 = {𝑞1, ⋯ , 𝑞𝑁}, 𝑞𝑖 ∈ ℝ3, assume 𝑄 is fixed (target)
- Data association: 𝑁 correspondences
- For each point 𝑝𝑖 find the nearest neighbor in 𝑄
- Remove outlier pairs, e.g., ||𝑝𝑖 − 𝑞𝑖|| too large
- R,t=R,targminminE(R,t)=R,targminN1∑i=1N∥qi−Rpi−t∥2
- Compute center μp=N1∑i=1Nqi
- P′={pi−μp},Q′={qi−μq}
- Q′P′T=UΣVT
- R=UVT,t=μq−Rμp
- Check converge.
- Evaluate convergence criteria
- E(R,t)small enough
- 𝛥𝑅, 𝛥𝑡 small enough
- If not converged,
- 𝑃 ← 𝑅𝑃 + 𝑡
- repeat Step 1-3
ICP 缺点
- 找最近对应点的计算开销较大
- 只考虑了点与点距离,缺少对点云结构信息的利用
改进
- 选取一部分点做ICP,减少计算复杂度
- Random Sample
- Voxel Grid Sample
- Normal Space Sampling (NSS)
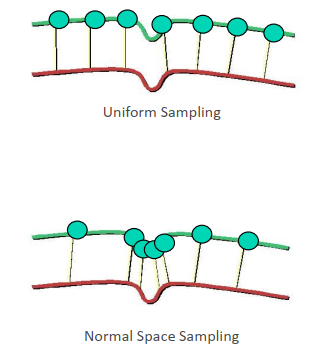
- Feature detection
- 数据关联
- Nearest neighbor – kd-tree/octree for acceleration
- Normal shooting:投影其法向量最短的点,作为关联
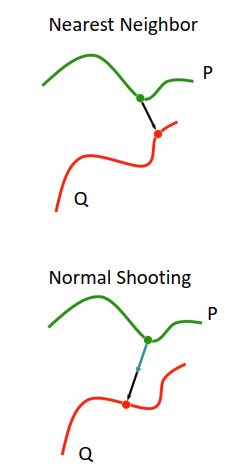
- Projection:只能在RGBD中做,通过2维坐标找关联
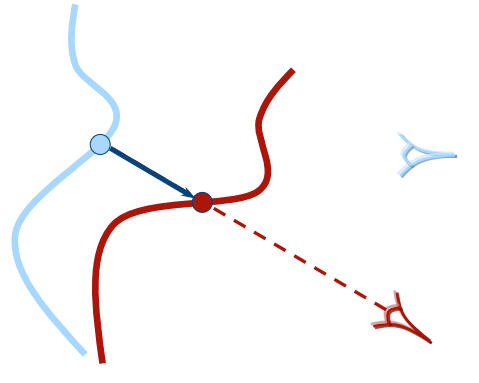
- Feature descriptor matching (compatible point)
- 去除异常值
- Remove correspondence with high distance
- Remove worst x% of correspondences
- Loss function
Point-to-Plane步骤
- Given two corresponding point sets:
- 𝑃 = {𝑝1, ⋯ , 𝑝𝑁}, 𝑝𝑖 ∈ ℝ3, we are transforming 𝑃 (source)
- 𝑄 = {𝑞1, ⋯ , 𝑞𝑁}, 𝑞𝑖 ∈ ℝ3, assume 𝑄 is fixed (target)
- Data association: 𝑁 correspondences
- For each point 𝑝𝑖 find the nearest neighbor in 𝑄
- Remove outlier pairs, e.g., ||𝑝𝑖 − 𝑞𝑖|| too large
- R,t=R,targminminE(R,t)=R,targminN1∑i=1N((Rpi+t−qi)Tni)2
- x^=xargminE(x)=∥Ax−b∥2=(ATA)−1ATb
- x^=[α,β,γ,tx,ty,tz]T
- compute R,t from x^
- Check converge.
- Evaluate convergence criteria
- E(R,t)small enough
- 𝛥𝑅, 𝛥𝑡 small enough
- If not converged,
- 𝑃 ← 𝑅𝑃 + 𝑡
- repeat Step 1-3
NDT
- Normal Distribution Transform

- 建立voxel,每个grid使用高斯模型来建模。如果一个格子中的点过于少就丢掉,认为格子是空的,无法建立高斯模型。
- μ=m1∑k=1myk
- Σ=m−11∑k=1m(yk−μ)(yk−μ)T
- 建立出三维的高斯分布

- 将source中的点,通过RT转到target frame中,然后用1)中建立的概率构建最大似然估计
- 使用mixture prob来代替高斯分布,使得对外点鲁棒
- 用高斯分布模拟最大似然中的-log函数
- 使用牛顿法来求解高斯分布的极值,从而完成优化。可以求出NDT中牛顿法的解析解,所以很快。
Feature Based Registration