
VGGNet
VGGNet
- VGGNet2015,K. Simonyan and A. Zisserman提出,是2014 年ILSVRC竞赛分类任务的第二名(第一名是GoogLeNet)和定位任务的第一名。
- 泛化能力强,适合迁移学习
网络改进
- 对卷积核和池化大小进行了统一: 3×3卷积和2×2最大池化操作
- 采用卷积层堆叠的策略,将多个连续的卷积层构成卷积层组
- 采用小的卷积滤波器,网络更深(16/19层)
- 不采用LRN(Local Response Normalization)
网络结构
- VGG-16有16个卷积层或全连接层,包括五组卷积层和3个全连接层,即: 16=2+2+3+3+3+3。

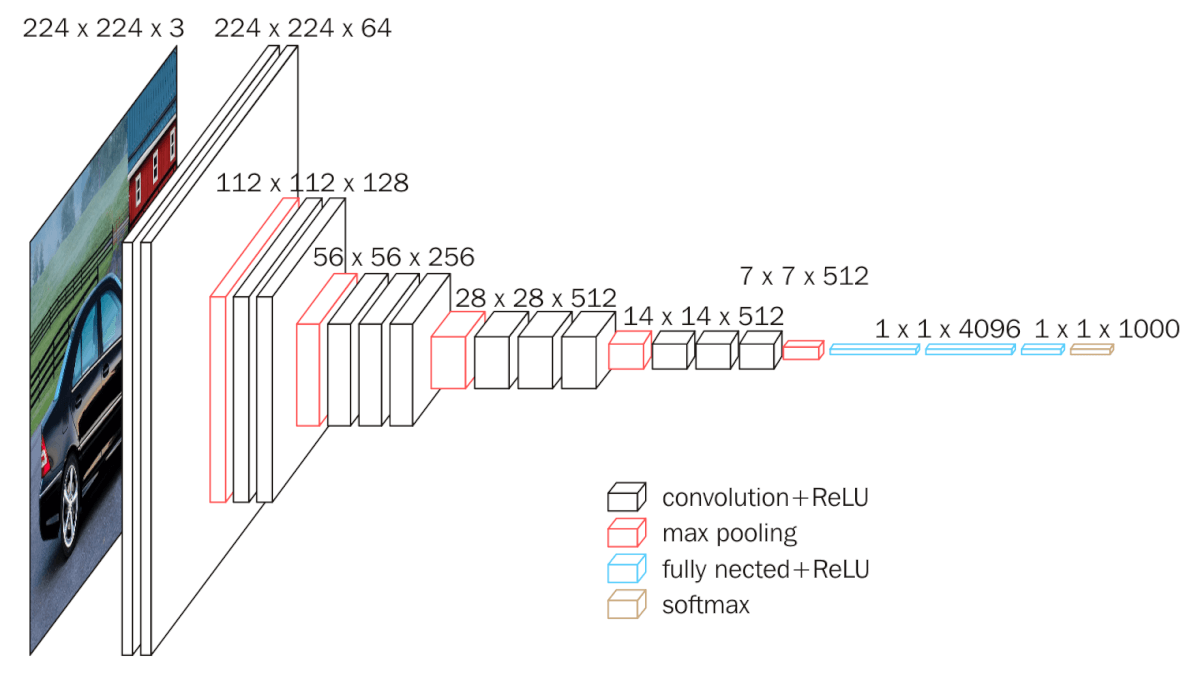
- 网络包含5组卷积操作,每组内的卷积层具有相同的结构,每组包含1~3个连续的卷积层,每两个卷积层之间为ReLU层。
- VGG的卷积层,特征图的空间分辨率单调递减,特征图的通道数单调递增。使得输入图像在维度上流畅地转换到分类向量。AlexNet的通道数无此规律,VGGNet后续的GoogLeNet和ResNet均遵循此维度变化的规律。
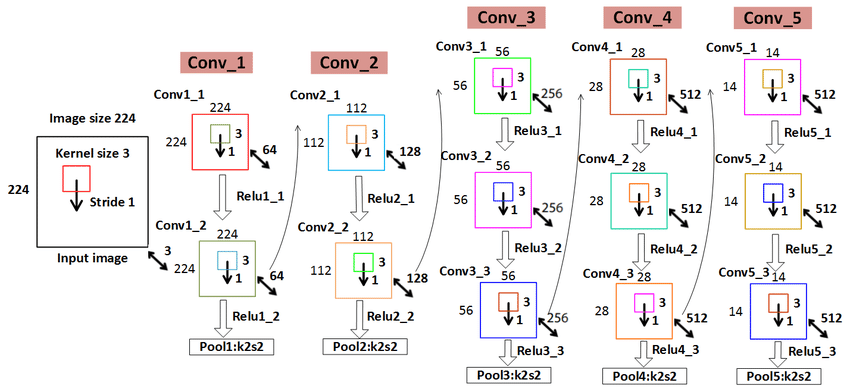
卷积堆叠
- 与单个卷积层相比,卷积堆叠可以增加感受野,增强网络的学习能力和特征表达能力
- 与具有较大核的卷积层相比,采用多个具有小卷积核的卷积层串联的方式能够减少网络参数
- 在每层卷积之后进行ReLU非线性操作可提升网络的特征学习能力

- 感受野计算公式:
- 其中:为第i层感受野
- 第i层步距
- 卷积核或池化核尺寸
训练
-
训练是通过使用带有动量的小批次梯度下降的反向传播来优化多类别逻辑回归目标
-
批次大小设置为256,动量为0.9。 通过权重衰减正则化(L2惩罚因子设置为5 × 10−4)和前两个全连接层的丢弃(丢弃率设置为0.5)对训练进行正则化。
-
学习率初始设定为10−2, 然后当验证集准确率度停止改善时,学习率降低10倍
-
单尺度训练:训练图像大小裁剪为固定大小
224*224(s=224)或384*384(s=384) -
多尺度训练:尺度抖动,训练图像大小随机在
s∈[256,512]的范围中 -
训练时,将不同尺寸的s,随机裁剪为
224*224的训练样本 -
测试时,将图像缩放到固定尺寸Q=s或0.5(256+512),对网络最后的卷积层使用滑动窗口进行分类预测,对不同的窗口分类结果取平均。
多剪裁
- Multi-Crop evaluation: 从测试图像中剪切出一大批
224*224的小块图像,在输出时取平均得到一个1000维的平均结果。
密集评估
- Dense evaluation: 测试图像的尺寸不作任何变化,将最后一个卷积层和全连接层看成为一个卷积操作,然后对所作的结果进行平均。 全卷积网络因为没有全连接的限制,因而可以接收任意宽或高的输入
- 首先将全连接的层转换为卷积层(第一个FC层转换到7×7卷积层,最后两个FC层转换到1×1转换层)。 然后将得到的全卷积网络应用于整个(未剪切的)图像。
- 比如,对于训练图像其大小为
224*224,经过最后一个卷积得到7×7×m的特征图,然后输出为1000个结点。这是训练好的网络。 - 对于一个
448*448的测试图像,经过训练好的网络的映射,最后会输出2*2*1000大小的结果,将2*2里面的内容进行平均,即得到1000维向量