
简介
背景
- 1982 年,美国 AT&T 公司贝尔实验室的 Bjarne Stroustrup 博士在 c 语言的基础上引入并扩充了面向对象的概念,发明了一种新的程序语言。为了表达该语言与 c 语言的渊源关系,它被命名为
C++。而 Bjarne Stroustrup(本贾尼·斯特劳斯特卢普)博士被尊称为C++语言之父。
历史
- 在“C with Class”阶段,研制者在 C 语言的基础上加进去的特征主要有:类及派生类、共有和私有成员的区分、类的构造函数和析构函数、友元、内联函数、赋值运算符的重载等。
- 1985 年公布的
C++语言 1.0 版的内容中又添加了一些重要特征:虚函数的概念、函数和运算符的重载、引用、常量(constant)等。 - 1989 年推出的 2.0 版形成了更加完善的支持面向对象程序设计的
C++语言,新增加的内容包括:类的保护成员、多重继承、对象的初始化与赋值的递归机制、抽象类、静态成员函数、const 成员函数等。 - 1993 年的
C++语言 3.0 版本是C++语言的进一步完善,其中最重要的新特征是模板(template),此外解决了多重继承产生的二义性问题和相应的构造函数与析构函数的处理等。 - 1998 年
C++标准(ISO/IEC14882 Standard for the C++ Programming Language)得到了国际标准化组织(ISO)和美国标准化协会(ANSI)的批准,标准C++语言及其标准库更体现了C++语言设计的初衷。名字空间的概念、标准模板库(STL)中增加的标准容器类、通用算法类和字符串类型等使得C++语言更为实用。此后C++是具有国际标准的编程语言,该标准通常简称ANSI C++或ISO C++ 98标准,以后每 5 年视实际需要更新一次标准。 - 后来又在 2003 年通过了
C++标准第二版(ISO/IEC 14882:2003):这个新版本是一次技术性修订,对第一版进行了整理——修订错误、减少多义性等,但没有改变语言特性。这个版本常被称为C++03。 - 此后,新的标准草案叫做
C++ 0x。对于C++ 0x标准草案的最终国际投票已于 2011 年 8 月 10 日结束,并且所有国家都投出了赞成票,C++0x已经毫无异议地成为正式国际标准。先前被临时命名为C++0x的新标准正式定名为 ISO/IEC 14882:2011,简称ISO C++11标准。C++ 11标准将取代现行的C++标准C++98和C++03。国际标准化组织于 2011 年 9 月 1 日出版发布《ISO/IEC 14882:2011》,名称是:Information technology -- Programming languages -- C++ Edition: 3。 C++标准第四版,2014年8月18日发布。正式名称为ISO/IEC 14882:2014。C++14是C++11的增量更新,主要是支持普通函数的返回类型推演,泛型 lambda,扩展的 lambda 捕获,对 constexpr 函数限制的修订,constexpr变量模板化等。C++17C++20
内容
C++语言的名字,如果看作 c 的基本语法,是由操作数 c 和运算符后++构成。C++是本身这门语言先是 c,是完全兼容 c.然后在此基础上++。这个++包含三大部分,c++对 c的基础语法的扩展,面向对像(继承,封装,多态),STL 等
C++对C的扩展(Externsion)
类型增强
- 类型检查更严格
- 比如,把一个 const 类型的指针赋给非 const 类型的指针。c 语言中可以通的过,但是在
c++中则编不过去。
- 比如,把一个 const 类型的指针赋给非 const 类型的指针。c 语言中可以通的过,但是在
int main() |
-
布尔类型(bool)
- c 语言的逻辑真假用 0 和非 0 来表示。而
c++中有了具体的类型。
- c 语言的逻辑真假用 0 和非 0 来表示。而
-
真正的枚举(enum)
- c 语言中枚举本质就是整型,枚举变量可以用任意整型赋值。而 c++中枚举变量,只能用被枚举出来的元素初始化。
enum season {SPR,SUM,AUT,WIN}; |
- 表达式的值可被赋值
- c 语言中表达式通常不能作为左值的,即不可被赋值,
c++中某些表达式是可以赋值的。
- c 语言中表达式通常不能作为左值的,即不可被赋值,
int a,b = 5; |
宽字符
|
动态获取数据类型
- typeid是关键字
|
可变参数
- 类型一致
|
- 类型不一致
|
- 使用c++可变参数模板实现printf/scanf
|
auto
- 自动推理数据类型
auto str=L"asdf"; |
decltype
- 根据一个变量获取类型,auto自适应变量,但是无法创建指针数组等变量
bool a=1; |
数组初始化
- 两种数组初始化方法
int a[5]{1,2,3,4,5}; |
nullptr
c语言NULL,会被误认为整数c++使用nullptr可以自动识别对应的类型
new/delete
- 堆、栈、静态区
| 存储区 | 说明 |
|---|---|
| 堆区 | free释放后仍可以强制指定内存地址覆盖重写 |
| 栈区 | 可以覆盖重写,但是free后无法再次使用 |
| 静态区 | 可以覆盖重写,但是free后无法再次使用 |
char str[1024] = {0};//内存静态区 |
- 重载:
new,new[],delete,delete[] - new执行顺序:
局部new -> 全局new -> malloc -> 构造函数 - delete执行顺序:
析构函数 -> 局部delete -> 全局delete -> free
//局部重载 |
typedef在cpp中的替代
typedef只能处理c语言风格的别名,在cpp中:命名空间、类模板、template都无法使用。- 一般情况使用using代替typedef
typedef double DB; |
namespace run{ |
|
输入与输出(cin /cout)
cin && cout
- cin 和 cout 是
C++的标准输入流和输出流。他们在头文件 iostream 中定义。cin是类对象,>>流输入运算符,重载。
| 流名 | 含义 | 隐含设备 | 流名 | 含义 | 隐含设备 |
|---|---|---|---|---|---|
| cin | 标准输入 | 键盘 | cerr | 标准错误输出 | 屏幕 |
| cout | 标准输出 | 屏幕 | clog | cerr 的缓冲输出 | 屏幕 |
格式化
设置域宽及位数
- 对于实型,cout 默认输出六位有效数据,setprecision(2) 可以设置有效位数,
setprecision(n)<<setiosflags(ios::fixed)合用,可以设置小数点右边的位数。
|
按进制输出
- 输出十进制,十六进制,八进制。默认输出十进制的数据。
int i = 123; |
设置填充符
- 还可以设置域宽的同时,设置左右对齐及填充字符。
int main() |
函数重载(function overload)
重载规则
- 重载规则:
- 函数名相同。
- 参数个数不同,参数的类型不同,参数顺序不同,均可构成重载。
- 返回值类型不同则不可以构成重载。
- 有的函数虽然有返回值类型,但不与参数表达式运算,而作一条单独的语句。
匹配原则
-
匹配原则:
- 严格匹配,找到则调用。
- 通过隐式转换寻求一个匹配,找到则调用。
-
C++允许,int 到 long 和 double,double 到 int 和 float 隐式类型转换。遇到这种情型,则会引起二义性。
原理
C++利用 name mangling(倾轧)技术,来改名函数名,区分参数不同的同名函数。- 实现原理:用 v-c- i-f- l- d 表示 void char int float long double 及其引用。
操作符重载(operator overload)
c++认为一切操作符都是函数,而函数是可以重载的。
struct COMP |
- 示例中重载了一个全局的操作符+号用于实现将两个自定义结构体类型相加。本质是
operator+函数的调用。
extern “C”
- name mangling 发生在两个阶段,.cpp 编译阶段,和.h 的声明阶段。只有两个阶段同时进行,才能匹配调用。
- c++ 完全兼容 c 语言,那就面临着,完全兼容 c 的类库。由.c 文件的类库文件中函数名,并没有发生 name mangling 行为,而我们在包含.c 文件所对应的.h 文件时,.h 文件要发生name manling 行为,因而会发生在链接的时候的错误。
C++为了避免上述错误的发生,重载了关键字 extern。只需要,要避免 name manling的函数前,加 extern “C” 如有多个,则 extern “C”{}
|
默认参数(default parameters)
- 通常情况下,函数在调用时,形参从实参那里取得值。对于多次调用用一函数同一实参时,
C++给出了更简单的处理办法。给形参以默认值,这样就不用从实参那里取值了。
float volume(float length, float weight = 4,float high = 5){ |
- 规则
- 默认的顺序,是从右向左,不能跳跃。(参数进栈的方式:从右向左)
- 函数声明和定义一体时,默认认参数在定义(声明)处。声明在前,定义在后,默认参数在声明处。
- 一个函数,不能既作重载,又作默认参数的函数。当你少写一个参数时,系统无法确认是重载还是默认参数。
引用(Reference)
- 变量名,本身是一段内存的引用,即别名(alias)。此处引入的引用,是为己有变量起一个别名。
- 引用是一种声明关系,声明时必须初始化,引用不开辟空间。
- 引用使用指针进行管理
int a; |
规则
- 引用没有定义,是一种关系型声明。声明它和原有某一变量(实体)的关系。故而类型与原类型保持一致,且不分配内存。与被引用的变量有相同的地址。
- 声明的时候必须初始化,一经声明,不可变更。
- 可对引用,再次引用。多次引用的结果,是某一变量具有多个别名。
- &符号前有数据类型时,是引用。其它皆为取地址。(变量前面的&是取地址:&a)
int a,b; |
引用的本质
- 引用的本质是指针,
C++对裸露的内存地址(指针)作了一次包装。又取得的指针的优良特性。所以再对引用取地址,建立引用的指针没有意义。 - 引用的本质是,是对常指针 type * const p 的再次包装。
char &rc == *pc double &rd == *pd
int * func1(){ |
注意点
- 可以定义指针的引用,但不能定义引用的引用。
int a; |
- 可以定义指针的指针(二级指针),但不能定义引用的指针。
int a; |
- 可以定义指针数组,但不能定义引用数组,可以定义数组引用。
int a, b, c; |
- 常引用:const 引用有较多使用。它可以防止对象的值被随意修改。因而具有一些特性。
- const 对象的引用必须是 const 的,将普通引用绑定到 const 对象是不合法的。 这个原因比较简单。既然对象是 const 的,表示不能被修改,引用当然也不能修改,必须使用 const 引用。实际上,const int a=1; int &b=a;这种写法是不合法的,编译不过。
- const 引用可使用相关类型的对象(常量,非同类型的变量或表达式)初始化。这个是const 引用与普通引用最大的区别。const int &a=2;是合法的。double x=3.14; const int&b=a;也是合法的。
- 常引用原理:const 引用的目的是,禁止通过修改引用值来改变被引用的对象。const 引用的初始化特性较为微妙,可通过如下代码说明:
double val = 3.14; |
- 上述输出结果为 3 3.14 和 3 4.14。因为 ref 是 const 的,在初始化的过程中已经给定值,不允许修改。而被引用的对象是 val,是非 const 的,所以 val 的修改并未影响 ref的值,而 ref2 的值发生了相应的改变。那么,为什么非 const 的引用不能使用相关类型初始化呢?实际上,const 引用使用相关类型对象初始化时发生了如下过程:
int temp = val;const int &ref = temp;如果 ref 不是 const 的,那么改变 ref 值,修改的是 temp,而不是 val。期望对 ref 的赋值会修改 val 的程序员会发现 val 实际并未修改。
int i=5; |
- 尽可能使用 const:原因如下:
- 使用 const 可以避免无意修改数据的编程错误。
- 使用 const 可以处理 const 和非 const 实参。否则将只能接受非 const 数据。
- 使用 const 引用,可使函数能够正确的生成并使用临时变量(如果实参与引用参数不匹配,就会生成临时变量)
左值/右值引用
int a(4); |
函数指针
函数指针数组
|
引用函数指针
- 函数指针的作用:改变代码的行为。函数指针的返回值是函数指针。
- 在c中改变函数指针需要二级指针,在cpp中可以直接引用
|
new/delete Operator
- c 语言中提供了 malloc 和 free 两个系统函数(库:stdlib.h),完成对堆内存的申请和释放。而
c++则提供了两关键字 new 和 delete ;
new/new[]用法:
- 开辟单变量地址空间
int *p = new int; //开辟大小为 sizeof(int)空间 |
- 开辟数组空间
一维: int *a = new int[100]{0};开辟一个大小为 100 的整型数组空间 |
delete /delete[]用法:
- delete和free对于基本数据类型基本一致
- delete和
delete[]在基本数据类型处理也一致。但复合类型两者不同,delete只释放一次,delete[]检测数组结束符,循环释放
//1. int *a = new int; |
- 返回值
//c 语言版本 |
注意事项
- new/delete 是关键字,效率高于 malloc 和 free.
- 配对使用,避免内存泄漏和多重释放。
- 避免交叉使用。比如new申请的类空间,free后不会自动调用析构函数。 malloc申请的类空间,不会调用构造函数。
内联函数(inline function)
- c 语言中有宏函数的概念。宏函数的特点是内嵌到调用代码中去,避免了函数调用的开销。但是由于宏函数的处理发生在预处理阶段,缺失了语法检测和有可能带来的语意差错。例如传入
i++。 C++提供了 inline 关键字,实现了真正的内嵌。
//宏优点:内嵌代码,辟免压栈与出栈的开销 |
- 内联的优缺点
- 优点:避免调用时的额外开销(入栈与出栈操作)
- 代价:由于内联函数的函数体在代码段中会出现多个“副本”,因此会增加代码段的空间。
- 本质:以牺牲代码段空间为代价,提高程序的运行时间的效率。
- 适用场景:函数体很“小”,且被“频繁”调用
- 编译器会根据内联函数的代码数量,决定是否内联;但是不声明内联的函数不会自动内联。
类型强转(type cast)
- 类型转换有 c 风格的,当然还有
c++风格的。c 风格的转换的格式很简单(TYPE EXPRESSION),但是 c 风格的类型转换有不少的缺点,有的时候用 c 风格的转换是不合适的,因为它可以在任意类型之间转换,比如你可以把一个指向 const 对象的指针转换成指向非const 对象的指针,把一个指向基类对象的指针转换成指向一个派生类对象的指针,这两种转换之间的差别是巨大的,但是传统的 c 语言风格的类型转换没有区分这些。还有一个缺点就是,c 风格的转换不容易查找,他由一个括号加上一个标识符组成,而这样的东西在c++程序里一大堆。所以c++为了克服这些缺点,引进了新的类型转换操作符
静态类型转换
- 语法格式:
static_cast<目标类型> (标识符) - 转化规则:在一个方向上可以作隐式转换,在另外一个方向上就可以作静态转换。
int a = 10; |
重解释类型转换
- 语法格式:
reinterpret_cast<目标类型> (标识符) - 转化规则:“通常为操作数的位模式提供较低层的重新解释”也就是说将数据以二进制存在形式的重新解释,在双方向上都不可以隐式类型转换的,则需要重解释类型转换。
char *p; int *q; |
(脱)常类型转换
- 语法格式:
const_cast<目标类型> (标识符),目标类类型只能是指针或引用 - 转化规则:用来移除对象的常量性(cast away the constness)使用 const_cast 去除 const 限定的目的不是为了修改它的内容,而通常是为了函数能够接受这个实际参数。
- 可以改变 const 自定义类的成员变量,但是对于内置数据类型,却表现未定义行为。
CSDN:Depending on the type of the referenced object, a write operation through the resulting pointer, reference, or pointer to data member might produce undefined behavior.
//应用场景 1: |
//脱掉 const 后的引用或指针可以改吗?const变量一定不能改 |
- const补充:宏在预处理阶段替换了所有宏,而const变量是在编译阶段替换了所有变量。const永远不去改变。
动态类型转换
- 语法格式:
dynamic_cast<目标类型> (标识符) - 转化规则:用于多态中的父子类之间的强制转化
命名空间(namespace scope)
- 命名空间为了大型项目开发,而引入的一种避免命名冲突的一种机制。比如说,在一个大型项目中,要用到多家软件开发商提供的类库。在事先没有约定的情况下,两套类库可能在存在同名的函数或是全局变量而产生冲突。项目越大,用到的类库越多,开发人员越多,这种冲突就会越明显。
默认NameSpace
- 全局
Global scope是一个程序中最大的 scope。也是引起命名冲突的根源。C 语言没有从语言层面提供这种机制来解决。也算是 C 语言的硬伤了。Global scope是无名的命名空间,命名空间为空。c++的作用域运算符:::。所以全局的命名空间直接用::即可表示。 - 局部
Function scope就是函数作用域,就没有命名空间的概念了。直接使用函数内声明的变量即可。
int a = 10; |
语法
- NameSpace 是对全局(Global scope)区域的再次划分
声明
namespace NAMESPACE空间名称 |
使用
- 直接指定 命名空间:
Space::a = 5;,直接调用 - 使用 using+命名空间+空间元素:
using Space::a; a = 2000;,取出其中一个 - 使用 using +namespace+命名空间:
using namespace Space;,都取出来
全取出来虽然方便,但是可能会与局部的同名变量发生冲突。
支持嵌套
namespace MySpace |
协作开发
- 同名命名空间自动合并,对于一个命名空间中的类,要包含声明和实现。
inline namespace
namespace std{ |
系统 string 类
- 除了使用字符数组来处理字符串以外,c++引入了字符串类型。可以定义字符串变量。
- 在
<iostream>std命名空间中
定义及初始化
string str; |
类型大小
string str; |
常用运算
| 操作 | 示例 |
|---|---|
| 赋值 | string str3 = str2; |
| 加法 | string combine = str + str2; |
| 大小 | str3.size() |
| 关系 | string s1 = "abcdeg";string s2 = "12345";if(s1>s2)cout<<"s1>s2"<<endl; |
| 减法没有重载 | string s3 = s1-s2; // error |
常见的成员函数
| 操作 | 示例 | 说明 |
|---|---|---|
| 下标操作 | char & operator[](int n) ; |
|
| 求串大小 | int size(); |
|
| 返回 c 串 | char *c_str(); |
与字符数组之间操作,需要返回c串 |
| 查找 | int find(char c, int pos = 0);int find(char * s, int pos = 0); |
返回下标值,没有找到返回-1,默认从 0 下标开找 |
| 删除 | string &erase(int idx=0,int n = npos); |
作用是删除从 idx 开始,往后数 n 位的字符串。 |
| 交换 swap | void swap(stirng &s2); |
string 类型数组
- string 数组是高效的,如果用二维数组来存入字符串数组的话,则容易浪费空间,此时列数是由最长的字符串决定。如果用二级指针申请堆空间,依据大小申请相应的空间,虽然解决了内存浪费的问题,但是操作麻烦。用 string 数组存储,字符串数组的话,效率即高又灵活。
string sArray[10] = { |
vector类
- 使用
char**、string、vector三种方式,打印文件中的内容
File *fp = fopen("a.txt","r+"); |
结构体数组
|
多元数组
- 存取不同数据类型
|
多线程
初步
|
传递参数
|
原子变量互斥锁
- 多线程冲突
|
lambda与多线程
|
lambda
auto fun = []{cout<<"fun"<<endl;}; |
- 引入外部变量
| 符号 | 说明 |
|---|---|
| [=] | 引入外部变量,只读 |
| [&] | 引入外部变量,可读写 |
| =mutable | 副本机制 |
| [&a,b,c] | 引入外部变量a,b,c,其中a可读写 |
int num1=0,num2=1; |
函数包装器funtion
|
const
- c语言const类型无法直接更改,但可以间接更改
|
c++编译器优化,将const类型直接define替换,但是变量无法替换,可以间接更改
|
- const标识
const int *p; //地址可以改,内容不能改 |
C++面向对象
封装(Encapsulation)
- 概念:当单一变量无法完成描述需求的时候,结构体类型解决了这一问题。可以将多个类型打 包成一体,形成新的类型。但是,新类型并不包含,对数据类的操作。所的有操作都是通过函数的方式,去其进行封装。
定义封装
- 封装,可以达到,对外提供接口,屏蔽数据,对内开放数据。
- struct 中所有行为和属性都是 public 的(默认)。C++中的 class 可以指定行为和属性的访问方式,默认为 pirvate。
| 访问属性 | 属性 | 对象内部 | 对象外部 |
|---|---|---|---|
| public | 公有 | 可访问 | 可访问 |
| protected | 保护 | 可访问 | 不可访问 |
| private | 私有 | 可访问 | 不可访问 |
用class去封装带行为的类
- class 封装的本质,在于将数据和行为,绑定在一起然后通过对象来完成操作。
类与对象(Class &&object)
构造器(Constructor)
- 构造器名与类名相同。
- 在类对象创建时,自动调用,完成类对象的初始化。尤其是动态堆内存的申请。
- 规则:
- 在对象创建时自动调用,完成初始化相关工作。
- 无返回值,与类名同,
- 可以重载,可默认参数。
- 默认无参空体,一经实现,默认不复存在。
定义
class 类名 |
参数初始化表
class A { |
- 注意点
- 此格式只能用于类的构造函数。
- 初始化列表中的初始化顺序,与声明顺序有关,与前后赋值顺序无关。
- 必须用此格式来初始化非静态 const 数据成员(c++98)。
- 必须用此格式来实始化引用数据。
析造器(Destructor)
- 析构函数的作用,并不是删除对象,而在对象销毁前完成的一些清理工作。
- 栈对象离开其作用域。
- 堆对象被手动 delete.
析构器的定义及意义
class 类名{ |
- 在类对像销毁时,自动调用,完成对象的销毁。尤其是类中己申请的堆内存的释放.
- 规则:
- 对象销毁时,自动调用。完成销毁的善后工作。
- 无返值,与类名同,无参。不可以重载与默认参数。
- 系统提供默认空析构器,一经实现,不复存在。
拷贝构造(Copy contructor)
- 由己存在的对象,创建新对象。也就是说新对象,不由构造器来构造,而是由拷贝构造器来完成。拷贝构造器的格式是固定的。
定义
class 类名 |
- 规则:
- 系统提供默认的拷贝构造器。一经实现,不复存在。
- 系统提供的时等位拷贝,也就是所谓的浅浅的拷贝。
- 要实现深拷贝,必须要自定义。
拷贝构造发生的时机
- 制作对象的副本。
- 以对象作为参数和返回值。
深拷贝与浅拷贝
- 系统提供默认的拷贝构造器,一经定义不再提供。但系统提供的默认拷贝构造器是等位拷贝,也就是通常意义上的浅拷贝。如果类中包含的数据元素全部在栈上,浅拷贝也可以满足需求的。但如果堆上的数据,则会发生多次析构行为。
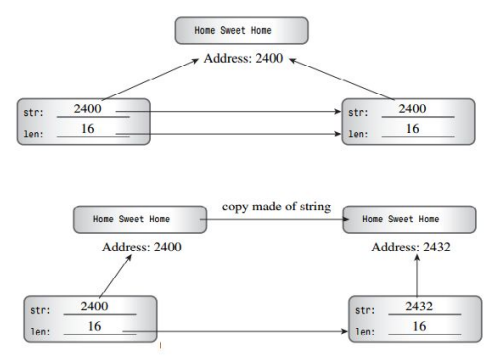
this 指针
- 系统在创建对象时,默认生成的指向当前对象的指针。这样作的目的,就是为了带来方便。
作用
- 避免构造器的入参与成员名相同。
- 基于 this 指针的自身引用还被广泛地应用于那些支持多重串联调用的函数中。比如连续赋值。
赋值运算符重载(Operator=)
- 用一个己有对象,给另外一个己有对象赋值。两个对象均己创建结束后,发生的赋值行为。
- 系统提供默认的赋值运算符重载,一经实现,不复存在。
- 系统提供的也是等位拷贝,也就浅拷贝,会造成内存泄漏,重析构。
- 要实现深深的赋值,必须自定义。
- 自定义面临的问题有三个:1、自赋值;2;内存泄漏、3,重析构
- 返回引用,且不能用 const 修饰。
a = b = c => (a+b) = c
定义
类名 |
类和对象
返回栈上引用与对象
c语言返回栈变量
- 为了解决函数调用完就释放空间的问题,在函数返回的过程产生了”中间变量”作为纽带。
- 不管是返回指针还是返回值,return将return之后的值存到
eax寄存器中,回到父函数再将返回的值赋给变量。
int func(){ |
c++返回栈对象
class A { |
C++的操作方式时,函数有返回值时,在main函数开辟一个临时空间,并将临时空间的地址隐式传递到调用的函数,再把函数内的变量拷贝到指定地址。
c++返回栈对象引用
- 返回栈对象的引用,多用于产生串联应用。比如连等式。
- 栈对象是不可以返回引用的。除非,函数的调用者返回自身对象。
- 这是由于返回后自身对象并未析构,但是如果是函数内创建的对象,在返回给主函数引用地址前,对象已经析构,可能会造成不可预知的错误。
MyString & MyString::operator=(const MyString & another){ |
栈和堆上的对象及对象数组
- 注意无参构造器的建立,因为如果生成对象数组,没有初始化则必调用无参构造器,或者手动调用带参构造器。
class Stu{ |
成员函数的存储方式
- 用类去定义对象时,系统会为每一个对象分配存储空间。如果一个类包括了数据和函数,要分别为数据分配存储空间,而函数则会创建公用的函数代码。这样做会大大节约存储空间。
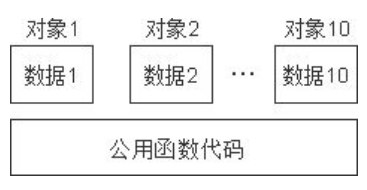
- 调用的原理:调用函数时,会通过this指针,找到对应对象的空间,操作不同的变量。
修饰符
const修饰符
const常量类的成员
- const 修饰类的成员变量,表示成员常量,不能被修改,同时它只能在初始化参数列表中赋值(c11 中支持类中初始化)。
- 可被 const 和非 const 成员函数调用,而不可以修改。
class A { |
const常量类的成员函数
- 承诺在本函数内部不会修改类内的数据成员,不会调用其它非 const 成员函数。
- const 修饰函数放在,声明之后,实现体之前,大概也没有别的地方可以放了。
void dis() const{} |
- const 构成函数重载
- 如果 const 构成函数重载,const 对象只能调用 const 函数,非 const 对象优先调用非 const 函数,若无则调用const成员函数。
- const 函数只能调用 const 函数。非 const 函数可以调用 const 函数。
- 类体外定义的 const 成员函数,在定义和声明处都需要 const 修饰符
const常量类对象
- const 对象,只能调用 const 成员函数。
- 可访问 const 或非 const 数据成员,不能修改。
constexpr
- 标志返回值是常数
//int get(){ |
static修饰符
- 在 C++中,静态成员是属于整个类的而不是某个对象,静态成员变量只存储一份供所有对象共用。所以在所有对象中都可以共享它。
- 使用静态成员变量实现多个对象之间的数据共享不会破坏隐藏(相比全局变量的优点)的原则,保证了安全性还可以节省内存。
- 类的静态成员,属于类,也属于对象,但终归属于类。
static的类成员
- 使用静态类成员
- static 成员变量实现了同簇类对象间信息共享。
- static 成员类外存储,求类大小,并不包含在内。
- static 成员是命名空间属于类的全局变量,存储在 data 区 rw 段。
- static 成员使用时必须实始化,且只能类外初始化。
- 可以通过类名访问(无对象生成时亦可),也可以通过对象访问。
- static 成员在类声明的时候就开辟空间并初始化了,而普通类成员在类构造时才开辟空间并初始化;
- 声明:
static 数据类型 成员变量; //在类的内部 - 初始化:必须在类的外部
数据类型 类名::静态数据成员 = 初值; //没有static修饰 - 调用:
类名::静态数据成员;类对象.静态数据成员
static的类成员函数
- 使用静态类成员函数
- 静态成员函数的意义,不在于信息共享,数据沟通,而在于管理静态数据成员,完成对静态数据成员的封装。
- 静态成员函数只能访问静态数据成员。原因:非静态成员函数,在调用时 this指针时被当作参数传进。而静态成员函数属于类,而不属于对象,没有 this 指针。
- 声明:
static 函数声明 - 调用:
类名::函数调用;类对象.函数调用
static const 类成员
- 如果一个类的成员,既要实现共享,又要实现不可改变,那就用 static const 修饰。修饰成员函数,格式并无二异,修饰数据成员。
- 必须要类内部实始化。
指向类成员的指针
- 在 C++语言中,可以定义一个指针,使其指向类成员或成员函数,然后通过指针来访问类的成员。这包括指向属性成员的指针和指向成员函数的指针。
指向类数据成员的指针
- 定义:
<成员数据类型><类名>::*<指针名> - 赋值&初始化:
<成员数据类型><类名>::*<指针名>[=&<类名>::<非静态数据成员>]- 指向非静态数据成员的指针在定义时必须和类相关联,在使用时必须和具体的对象关联。实际保存的是某个对象成员相对于这个类生成对象其实地址的偏移量,所以可以适用任意对象。
- 解用引:由于类不是运行时 存在的对象。因此,在使用这类指针时,需要首先指定类的一个对象,然后,通过对象来引用指针所指向的成员。
<类对象名>.*<指向非静态数据成员的指针>
<类对象指针>->*<指向非静态数据成员的指针>
Student s("zhangsan",1002); |
指向类成员函数的指针
- 一个指向非静态成员函数的指针必须在三个方面与其指向的成员函数保持一致:参数列表要相同、返回类型要相同、所属的类型要相同
- 定义:
<数据类型>(<类名>::*<指针名>)(<参数列表>) - 赋值&初始化:
<数据类型>(<类名>::*<指针名>)(<参数列表>)[=&<类名>::<非静态成员函数>] - 解用引由于类不是运行时存在的对象。因此,在使用这类指针时,需要首先指定类的一个对象,然后,通过对象来引用指针所指向的成员。
(<类对象名>.*<指向非静态成员函数的指针>)(<参数列表>);(<类对象指针>->*<指向非静态成员函数的指针>)(<参数列表>)
Student s("zhangsan",1002); |
指向类静态成员的指针
- 类静态数据成员的指针:指向静态数据成员的指针的定义和使用与普通指针相同,在定义时无须和类相关联,在使用时也无须和具体的对象相关联。
- 指向类静态成员函数的指针:向静态成员函数的指针和普通指针相同,在定义时无须和类相关联,在使用时也无须和具体的对象相关联。
class A{ |
小结
- 与普通意义上的指针不一样。存放的是偏移量。指向非静态成员函数时,必须用类名作限定符,使用时则必须用类的实例作限定符。指向静态成员函数时,则不需要使用类名作限定符。
//适用类成员函数指针实现内部函数选择调用 |
友元(Friend)
-
采用类的机制后实现了数据的隐藏与封装,类的数据成员一般定义为私有成员,成员函数一般定义为公有的,依此提供类与外界间的通信接口。但是,有时需要定义一些函数,这些函数不是类的一部分,但又需要频繁地访问类的数据成员,这时可以将这些函数定义为该类的友元函数。除了友元函数外,还有友元类,两者统称为友元。友元的作用是提高了程序的运行效率(即减少了类型和安全性检查及调用的时间开销),但它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。
-
可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类。
-
友元目的本质,是让其它不属于本类的成员(全局函数,其它类的成员函数),成为类的成员而具备了本类成员的属性。
友元使用
声明位置
- 友元声明以关键字friend开始,它只能出现在类定义中。因为友元不是授权类的成员,所以它不受其所在类的声明区域 public private 和 protected 的影响。通常我们选择把所有友元声明组织在一起并放在类头之后.
友元的利弊
- 友元不是类成员,但是它可以访问类中的私有成员。友元的作用在于提高程序的运行效率,但是,它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。不过,类的访问权限确实在某些应用场合显得有些呆板,从而容忍了友元这一特别语法现象。
注意事项
- 友元关系不能被继承。
- 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
- 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明
友元函数
-
友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以声明,声明时只需在友元的名称前加上关键字friend:
friend 类型 函数名(形式参数);,一个函数可以是多个类的友元函数,只需要在各个类中分别声明。 -
全局函数作友元函数
class Point{ |
- 类成员函数作友元函数
class Point; // 前向声明类Point,否则ManagerPoint声明时无法编译通过 |
- 前向声明,是一种不完全型(forward declaration)声明,即只需提供类名(无需提供类实现)即可。正因为是(incomplete type)功能也很有限:
- 不能定义类的对象。
- 可以用于定义指向这个类型的指针或引用。
- 用于声明(不是定义),使用该类型作为形参类型或者函数的返回值类型。
友元类
- 友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。
- 当希望一个类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。
class A { |
运算符重载(Operator OverLoad)
- 运算符重载的本质是函数重载。
语法格式
返值类型 operator 运算符名称(形参表列) { |
- operator 运算符名称 在一起构成了新的函数名。
- 比如
const Complex operator+(const Complex &c1,const Complex &c2);我们会说,operator+ 重载了重载了运算符+。
友元重载和成员重载
class Complex{ |
- 重载运算符不能破坏语意。
- 关于返回值
int a = 3;int b = 4; |
重载规则
-
1、
C++不允许用户自己定义新的运算符,只能对已有的C++运算符进行重载。- 例如,有人觉得 BASIC 中用
**作为幂运算符很方便,也想在C++中将**定义为幂运算符,用3**5表示3^5,这是不行的
- 例如,有人觉得 BASIC 中用
-
2、
C++中绝大部分运算符都是可以被重载的
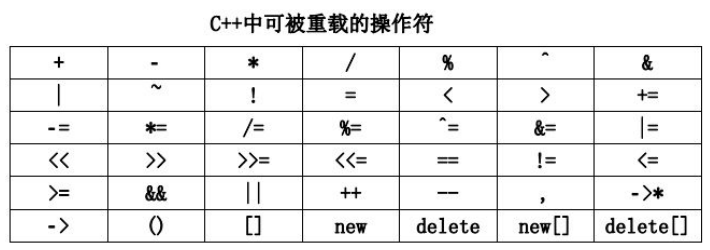
- 不能重载的运算符只有 4 个,前两个运算符不能重载是为了保证访问成员的功能不能被改变,域运算符合sizeof运算符的运算对象是类型而不是变量或一般表达式,不具备重载的特征。
| 不可重载 | 运算符 |
|---|---|
. |
成员运算符 |
.* |
成员对象选择符 |
:: |
域解析运算符 |
?: |
条件运算符,三目运算符 |
sizeof |
类型大小运算符 |
- 只能重载为成员函数的运算符
| 不可重载 | 运算符 |
|---|---|
= |
赋值运算符 |
[] |
下标运算符 |
() |
函数运算符 |
-> |
间接成员访问 |
->* |
间接取值访问 |
- 3、重载不能改变运算符运算对象(即操作数)的个数。
- 如关系运算符“>”和“<”等是双目运算符,重载后仍为双目运算符,需要两个参数。运算符
+,-,*,&等既可以作为单目运算符,也可以作为双目运算符,可以分别将它们重载为单目运算符或双目运算符。
- 如关系运算符“>”和“<”等是双目运算符,重载后仍为双目运算符,需要两个参数。运算符
- 4、重载不能改变运算符的优先级别。
- 例如
*和/优先级高于+和-,不论怎样进行重载,各运算符之间的优先级不会改变。有时在程序中希望改变某运算符的优先级,也只能使用加括号的方法强制改变重载运算符的运算顺序。
- 例如
- 5、重载不能改变运算符的结合性。
- 如复制运算符”=“是右结合性(自右至左),重载后仍为右结合性。
- 6、重载运算符的函数不能有默认的参数
- 否则就改变了运算符参数的个数,与前面第3点矛盾。
- 7、重载运算符的运算中至少有一个操作数是自定义类。
- 重载的运算符必须和用户定义的自定义类型的对象一起使用,其参数至少应有一个是类对象(或类对象的引用)。也就是说,参数不能全部是 C++的标准类型,以防止用户修改用于标准类型数据成员的运算符的性质,如下面这样是不对的:
int operator + (int a,int b){return(a-b);}
- 原来运算符+的作用是对两个数相加,现在企图通过重载使它的作用改为两个数相减。如果允许这样重载的话,如果有表达式 4+3,它的结果是 7 还是 1 呢?显然,这是绝对要禁止的。
- 8、不必重载的运算符(= &)
- 用于类对象的运算符一般必须重载,但有两个例外,运算符”=“和运算符”&“不必用户重载。
- 复制运算符”=“可以用于每一个类对象,可以用它在同类对象之间相互赋值。因为系统已为每一个新声明的类重载了一个赋值运算符,它的作用是逐个复制类中的数据成员
- 地址运算符&也不必重载,它能返回类对象在内存中的起始地址。
- 9、对运算符的重载,不应该失去其原有的意义
- 应当使重载运算符的功能类似于该运算符作用于标准类型数据时候时所实现的功能。
- 例如,我们会去重载”+“以实现对象的相加,而不会去重载”+“以实现对象相减的功能,因为这样不符合我们对”+“原来的认知。
双目运算符重载
- 形式:
L#R - 全局函数:
operator#(L,R); - 成员函数:
L.operator#(R) - 实现重载+=
class Complex{ |
单目运算符重载
- 形式:
#M 或 M# - 全局函数:
operator#(M) - 成员函数:
M.operator#() - 重载-运算符
class Complex{ |
重载格式
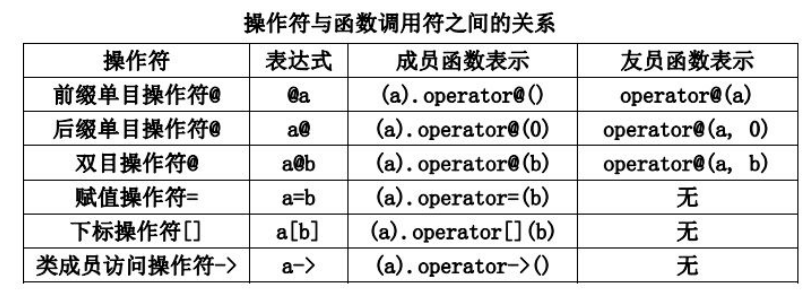
- 建议
| 运算符 | 建议使用 |
|---|---|
| 所有的一元运算符 | 成员 |
+= -= /= *= ^= &= != %= >>= <<= |
成员 |
| 其它二员运算符 | 非成员 |
- 友元还是成员
- 一个操作符的左右操作数不一定是相同类型的对象,这就涉及到将该操作符函数定义为谁的友元,谁的成员问题。
- 一个操作符函数,被声明为哪个类的成员,取决于该函数的调用对象(通常是左操作数)。
使用重载完成类型转换
标准类型间转换
- 隐式类型转换:
5/8 5.0/8 - 显式类型转换:
static_cast<float>(5)/8或者(float)5/8
用类型转换构造函数进行类型转换
- 实现其它类型到本类类型的转化。可用于构造和传参(也是构造,赋值)。
class 目标类{ |
- 转换构造函数,本质是一个构造函数。是只有一个参数的构造函数。如有多个参数,只能称为构造函数,而不是转换函数。
class Point3D{ |
- explicit 关键字:以显式的方式完成转化 static_cast<目标类> (源类对象),否则会报错。
- implicit 关键字:以隐式的方式完成转化
explicit Point3D(Point2D &p) //注:explicit 是个仅用于声明的关键字{ |
用类型转换操作符函数进行转换
- 类型转化函数:转换函数必须是类方法,转换函数无参数,无返回。
class 源类{ |
- 举例
class Point2D |
重载的高级用法
函数操作符()—仿函数
- 把类对象像函数名一样使用。仿函数(functor),就是使一个类的使用看上去象一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了。
class 类名{ |
- 举例
class Pow |
堆内存操作符 (new delete)
- 适用于极个别情况需要定制的时候才用的到。注: operator new 中 size_t 参数是编译器自动计算传递的。
void *operator new(size_t); |
- 全局重载
void * operator new (size_t size){return malloc(size);} |
- 类中重载
class A { |
解引用与智能指针(-> /*)
- 常规意义上讲,new 或是 malloc 出来的堆上的空间,都需要手动 delete 和 free 的。但在其它高级语言中,只需申请无需释放的功能是存在的。
- 智能指针,被auto_ptr托管以后,不需要关心delete问题,他会在ptr离开其栈空间的时候发生。
|
- 使用重载实现
class PMA |
智能指针
auto_ptr:自动内存释放
- 可以拷贝构造,负值重载,引用计数
- 原则已经不推荐使用了
auto_ptr<double>p(1); |
unique_ptr
- 检测到不调用,则不会分配内存;
- 不可以拷贝构造、负值重载,独享内存,其他指针不能拥有,但可以move
unique_ptr<double>p(1); |
shared_ptr
- 引用计数
- 使用智能指针在编译的时候,会在编译内内部的堆先测试一下,有用才编译;
shared_ptr<int> pint(new int[1024]); |
继承与派生(Inherit&&Derive)
- 继承和派生实际描述的是一件事,只不过被描述对象不同,父类派生出子类,子类继承于父类。基类派生出派生类,派生类继承于基类。
语法
- 一个派生类可以同时有多个基类,这种情况称为多重继承,派生类只有一个基类,称为单继承。
- 默认继承方式是private
class 派生类名:[继承方式] 基类名{ |
派生类的组成
- 派生类中的成员,包含两大部分,一类是从基类继承过来的,一类是自己增加的成员。从基类继承过过来的表现其共性,而新增的成员体现了其个性。
- 全盘接收,除了构造器与析构器。基类有可能会造成派生类的成员冗余,所以说基类是需设计的。
- 派生类有了自己的个性,使派生类有了意义。
派生类的构造
- 派生类中由基类继承而来的成员的初始化工作还是由基类的构造函数完成,然后派生类中新增的成员在派生类的构造函数中初始化
语法
- 构造函数的初始化顺序是根据声明的顺序初始化。
- 如果基类中没有默认构造函数(无参),那么在派生类的构造函数中必须显示调用基类构造函数,以初始化基类成员。
派生类名::派生类名(参数总表):基类名(参数表),内嵌子对象(参数表){ |
- 如果父类没有空参构造函数或者默认值构造函数,那么子类必须要使用参数列表的方式,显是的调用父类的构造器,否则无法完成父类的初始化。
//-----------父类------------- |
-
派生类构造函数执行的次序:基类–>成员中的类对象–>子类–>孙类
- 调用基类构造函数,调用顺序按照它们被继承时声明的顺序(从左到右);
- 调用内嵌成员对象的构造函数,调用顺序按照它们在类中声明的顺序;
- 派生类的构造函数体中的内容
-
子类构造器中,要么显示的调用父类的构造器(传参),要么隐式的调用。
-
发生隐式调用时,父类要有无参构造器或是可以包含无参构造器的默认参数函数。子类对象亦然。
派生类的拷贝构造
- 派生类中的默认拷贝构造器会调用父类中默认或自实现拷贝构造器,若子类中自实现拷贝构造器,则必须显示的调用父类的拷贝构造器。
- 格式
派生类::派生类(const 派生类& another) |
//----------父类---------------- |
派生类的赋值运算符重载
- 赋值运算符函数不是构造器,所以可以继承,语法上就没有构造器的严格一些。
- 派生类的默认赋值运算符重载函数,会调用父类的默认或自实现函数。派生类若自实现,则不会发生调用行为,也不报错(区别拷贝),赋值错误,若要正确,需要显式的调用父类的构造器
- 格式
子类& 子类::operator=(const 子类& another){ |
Graduate & Graduate::operator=(const Graduate & another){ |
- 对于父类和子类的成员重名的方法(即使返回值和参数不同,只要函数名相同),类似上面的父类的赋值运算函数,则需要使用
::到父类的命名空间就可以了。
派生类友元函数
- 由于友元函数并非类成员,因引不能被继承,在某种需求下,可能希望派生类的友元函数能够使用基类中的友元函数。为此可以通过强制类型转换,将派生类的指针或是引用强转为其类的引用或是指针,然后使用转换后的引用或是指针来调用基类中的友元函数。
class Student{ |
派生类析构函数的语法
- 派生类的析构函数的功能是在该对象消亡之前进行一些必要的清理工作,析构函数没有类型,也没有参数。析构函数的执行顺序与构造函数相反。
- 析构顺序:子类->成员->基类
- 无需指明析构关系。why? 析构函数只有一种,无重载,无默参。
派生类成员的标识和访问
作用域分辨符
- 格式:
基类名::成员名;基类名::成员名(参数表); - 如果某派生类的多个基类拥有同名的成员,同时,派生类又新增这样的同名成员,在这种情况下,派生类成员将
shadow(隐藏)所有基类的同名成员。这就需要这样的调用方式才能调用基类的同名成员。
d.Base::func(3); //访问基类成员 |
| 重载和隐藏的区别 | |
|---|---|
| 重载overload | 同一作用域 ,函数同名不同参(个数,类型,顺序) |
| 隐藏shadow | 父子类中,标识符(函数,变量)相同,无关乎返值和参数(函数),或声明类 型(变量) |
继承方式
-
派生类成员属性划分为四种:
- 公有成员
- 保护成员
- 私有成员
- 不可见的成员
-
继承方式规定了如何访问基类继承的成员。继承方式有 public, private, protected。继承方式不影响派生类的访问权限,影响了从基类继承来的成员的访问权限,包括派生类内的访问权限和派生类对象。
-
pretected 对于外界访问属性来说,等同于私有,但可以派生类中可见。
| 继承方式 | 基类成员方式 | 派生类内部访问 | 派生类对象访问 |
|---|---|---|---|
| 公有继承 | public protected private |
public protected inaccess |
public inaccess inaccess |
| 保护继承 | public protected private |
protected protected inaccess |
inaccess inaccess inaccess |
| 私有继承 | public protected private |
private private inaccess |
inaccess inaccess inaccess |
-
public 公有继承
- 当类的继承方式为公有继承时,基类的公有和保护成员的访问属性在派生类中不变,而基类的私有成员不可访问。即基类的公有成员和保护成员被继承到派生类中仍作为派生类的公有成员和保护成员。派生类的其他成员可以直接访问它们。无论派生类的成员还是派生类的对象都无法访问基类的私有成员。
-
private 私有继承
- 当类的继承方式为私有继承时,基类中的公有成员和保护成员都以私有成员身份出现在派生类中,而基类的私有成员在派生类中不可访问。基类的公有成员和保护成员被继承后作为派生类的私有成员,派生类的其他成员可以直接访问它们,但是在类外部通过派生类的对象无法访问。无论是派生类的成员还是通过派生类的对象,都无法访问从基类继承的私有成员。通过多次私有继承后,对于基类的成员都会成为不可访问。因此私有继承比较少用。
-
protected 保护继承
- 保护继承中,基类的公有成员和私有成员都以保护成员的身份出现在派生类中,而基类的私有成员不可访问。派生类的其他成员可以直接访问从基类继承来的公有和保护成员,但是类外部通过派生类的对象无法访问它们,无论派生类的成员还是派生类的对象,都无法访问基类的私有成员。
-
public作用:传承接口 间接的传承了数据(protected)
-
protected作用:传承数据,间接封杀了对外接口
-
private统杀了数据和接口
- 只要是私有成员到派生类中,均不可访问. 正是体现的数据隐蔽性.其私有成员仅可被本类的成员函数访问
- 如果多级派生当中,均采用 public,直到最后一级,派生类中均可访问基类的public,protected 成员. 兼顾了数据的隐蔽性和接口传承和数据传递
- 如果多级派生当中,均采用 private,直到最后一级,派生类中基类的所有成员均变为不可见. 只兼顾了数据的隐蔽性
- 如果多级派生当中,均采用 protected,直到最后一级,派生类的基类的所有成员即使可见,也均不可被类外调用只兼顾了数据的隐蔽性和数据传递
多继承
- 从继承类别上分,继承可分为单继承和多继承,前面讲的都是单继承。
继承语法
派生类名::派生类名(参数总表):基类名 1(参数表 1),基类名(参数名 2)....基类名 n(参数名 n),内嵌子对象 1(参数表 1),内嵌子对象 2(参数表 2)....内嵌子对象 n(参数表 n) { |
三角问题(二义性问题)
- 多个父类中重名的成员,继承到子类中后,为了避免冲突,携带了各父类的作用域信息, 子类中要访问继承下来的重名成员,则会产生二义性,为了避免冲突,访问时需要还有父类的作用域信息。
虚继承
- 在多继承中,保存共同基类的多份同名成员,虽然有时是必要的,可以在不同的数据成员中分别存放不同的数据,但在大多数情况下,是我们不希望出现的。因为保留多份数据成员的拷贝,不仅占有较多的存储空间,还增加了访问的困难。
- 为此,c++提供了,虚基类和虚继承机制,实现了在多继承中只保留一份共同成员。 虚基类,需要设计和抽象,虚继承,是一种继承的扩展。
- M 类称为虚基类(virtual base class ),是抽象和设计的结果。
- 虚继承语法:
class 派生类名:virtual 继承方式 基类 - 虚基类及间接类的实始化
class A{A(int i){}}; |
多态(PolyMorphism)
- C++中所谓的多态(polymorphism)是指,由继承而产生的相关的不同的类,其对象对同一消息会作出不同的响应。
- 多态性是面向对象程序设计的一个重要特征,能增加程序的灵活性。可以减轻系统升级,维 护,调试的工作量和复杂度
赋值兼容(多态实现的前提)
- 子类对象(引用或指针)可以赋值给父类对象(引用和指针),并且是隐式的拷贝,子类的新成员父类无法获取。
- 赋值兼容规则是指在需要基类对象的任何地方都可以使用公有派生类的对象来替代。赋值兼容是一种默认行为,不需要任何的显示的转化步骤。
- 赋值兼容规则中所指的替代包括以下的情况:
- 派生类的对象可以赋值给基类对象。
- 派生类的对象可以初始化基类的引用。
- 派生类对象的地址可以赋给指向基类的指针。
- 只发生在共有派生的父子关系中。
- 在替代之后,派生类对象就可以作为基类的对象使用,但只能使用从基类继承的成员。
- 父类也可以通过强转的方式转化为子类。 父类对象强转为子类对象后,访问从父类继承下来的部分是可以的,但访问子类的部分,则会发生越界的风险,越界的结果是未知的。
class Shape{ |
多态的形成
静多态
- 前面学习的函数重载,也是一种多态现象,通过命名倾轧在编译阶段决定,故称为静多态。
void func(int a,float b); // func_i_f |
动多态
- 动多态是在运行阶段决定,故称为动多态。动多态行成的
- 条件如下:
- 父类中有虚函数。
- 子类 override(覆写)父类中的虚函数。
- 通过己被子类对象赋值的父类指针或引用,调用共用接口。
class Shape{ |
虚函数
- 只有类的成员函数才能声明为虚函数
- 虚函数仅适用于有继承关系的类对象,所以普通函数不能声明为虚函数。
- 静态成员函数不能是虚函数
- 静态成员函数不受对象的捆绑,只有类的信息。
- 内联函数不能是虚函数
- 构造函数不能是虚函数
- 构造时,对象的创建尚未完成。构造完成后,才能算一个名符其实的对象。
- 析构函数可以是虚函数且通常声明为虚函数。
虚函数的声明
- 格式:
class 类名{virtual 函数声明; } - 虚函数要点
- 在基类中用 virual 声明成员函数为虚函数。类外实现虚函数时,不必再加 virtual.
- 在派生类中重新定义此函数称为覆写,要求函数名,返值类型,函数参数个数及类型全部匹配。并根据派生类的需要重新定义函数体。
- 当一个成员函数被声明为虚函数后,其派生类中完全相同的函数(显示的写出)也为虚函数。 可以在其前加 virtual 以示清晰。
- 定义一个指基类对象的指针,并使其指向其子类的对象,通过该指针调用虚函数,此时调用的就是指针变量指向对象的同名函数。
- 子类中的覆写的函数,可以为任意访问类型,依子类需求决定。
覆写override
| 重载、隐藏、覆写的区别 | |
|---|---|
| 重载overload | 同一作用域 ,函数同名不同参(个数,类型,顺序) |
| 隐藏shadow | 父子类中,标识符(函数,变量)相同,无关乎返值和参数(函数),或声明类 型(变量) |
| 覆写override | 父子类中含有virtual声明的同名、同参、同返回的虚函数,子类将其重写 |
纯虚函数
- 要点
- 含有纯虚函数的类,称为抽象基类,不可实列化。即不能创建对象,存在的意义就是被继承,提供族类的公共接口,java 中称为 interface。
- 纯虚函数只有声明,没有实现,被“初始化”为 0。
- 如果一个类中声明了纯虚函数,而在派生类中没有对该函数定义,则该虚函数在派生类中仍然为纯虚函数,派生类仍然为纯虚基类。
- 格式:
class 类名{virtual 函数声明 = 0;}0只是纯虚函数的格式,没有实现体 - 例举
//------------Shape 类中 |
含有虚函数的析构
- 含有虚函数的类,析构函数也应该声明为虚函数。在 delete 父类指针的时候,会调用子类的析构函数,实现完整析构。
class Shape{ |
运行时类型信息(RTTI)
- typeid、dynamic_cast是C++运行时类型信息RTTI(run time type identificaiton)重要组成部分。运行时信息,来自于多态,所以只用于基于多态的继承体系中。
typeid
- 运算符 typeid 返回包含操作数数据类型信息的 type_info 对象的一个引用,信息中包括数据类型的名称,要使用 typeid,程序中需要包含头文件
<typeinfo>。 - 其中 type_info 重载了操作符==, !=,分别用来比较是否相等、不等,函数 name()返回类型名称。type_info 的拷贝和赋值均是私有的,故不可拷贝和赋值。
- 常用于返回检查,调试之用。
typedef void (*Func)(); |
- 多态下使用 typeid 时要注意的问题:
- 确保基类定义了至少一个虚函数(虚析构也算)。
- 不要将 typeid 作用于指针,应该作用于引用,或解引用的指针。
- typeid 是一个运算符,而不是函数。
- typeid 运算符返回的 type_info 类型,其拷贝构造函数和赋值运算函数都声明为private 了,这意味着其不能用于 stl 容器,所以我们一般不能不直接保存 type_info 信息,而保存 type_info 的 name 信息
typecast
static_cast
- 在一个方向上可以作隐式转换的,在另外一个方向上可以作静态转换。发生在编译阶段,不保证后序使用的正确性。
reinterpreter_cast
- 既不在编译器期也不在运行期进行检查,安全性完全由程序员决定。
dynamic_cast
- dynamic_cast 一种运行时的类型转化方式,所以要在运行时作转换判断。检查指针所指类型,然后判断这一类型是否与正在转换成的类型有一种 “is a”的关系,如果是,dynamic_cast 返回对象地址。如果不是,dynamic_cast 返回 NULL。
- dynamic_cast 常用多态继承中,判断父类指针的真实指向。
class A {public:virtual ~A(){}}; |
多态实现原理
虚函数表
- C++的多态是通过一张虚函数表(Virtual Table)来实现的,简称为 V-Table。在这个表中,主是要一个类的虚函数的地址表,这张表解决了继承、覆写的问题,保证其真实反应实际的函数。
- 这样,在有虚函数的类的实例中这个表被分配在了这个实例的内存中,所以,当我们用父类的指针来操作一个子类的时候,这张虚函数表就显得由为重要了,它就像一个地图一样,指明了实际所应该调用的函数。
- 虚函数表是在构造函数中生成的,所以构造函数不能为虚函数。同时,子类构造时,由于先进行主类构造,构造调用子类重写的虚函数是不成功的,因为虚函数表没有生成,所以就近调用自己的函数。还有析构时,子类优先析构,主类调用时也无法获得虚函数表,也会就近调用自己的虚函数。
- 这里我们着重看一下这张虚函数表。C++的编译器应该是保证虚函数表的指针存在于对象实例中最前面的位置(这是为了保证取到虚函数表的有最高的性能——如果有多层继承或是多重继承的情况下)。 这意味着我们通过对象实例的地址得到这张虚函数表,然后就可以遍历其中函数指针,并调用相应的函数。
class Base { |
- 通过这个示例,我们可以看到,我们可以通过强行把&b 转成
int *,取得虚函数表的地址,然后,再次取址就可以得到第一个虚函数的地址了,也就是 Base::f(),这在上面的程序中得到了验证(把 int* 强制转成了函数指针)。通过这个示例,我们就可以知道如果要调用Base::g()和 Base::h(),其代码如下:
(Fun)*((int**)*(int*)(&b)+0); // Base::f() |
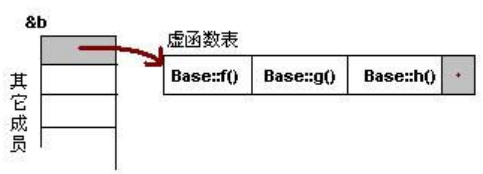
- 在对象首地址指向的虚函数表的最后有一个结点,这是虚函数表的结束结点,就像字符串的结束符“/0”一样,其标志了虚函数表的结束。这个结束标志的值在不同的编译器下是不同的。
无虚函数覆写继承
- 假设有下面父类和子类,在这个继承关系中,子类没有重载任何父类的函数。
class Base { |
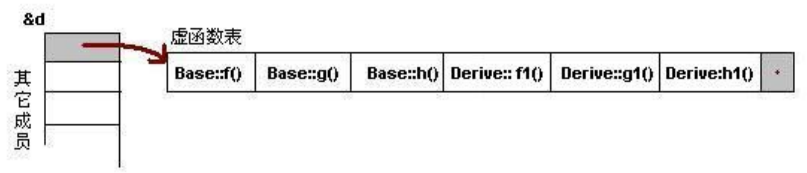
- 则派生类的实例中,其虚函数表如下所示
- 虚函数按照其声明顺序放于表中。
- 父类的虚函数在子类的虚函数前面
有虚函数覆写继承
- 在这个继承关系中,子类覆盖了父类的一个函数:f()。
class Base { |

- 可以看出
- 覆写的 f()函数被放到了虚表中原来父类虚函数的位置。
- 没有被覆盖的函数依旧。
Base *b = new Derive(); |
- 由 b 所指的内存中的虚函数表的 f()的位置已经被 Derive::f()函数地址所取代,于是在实际调用发生时,是 Derive::f()被调用了。这就实现了多态。
- 静态代码执行过程:当编译器看到这段代码的时候,并不知道 b 真实身份。编译器能作的就是用一段代码代替这段语句。
- 明确 b 类型。
- 然后通过指针虚函数表的指针 vptr 和偏移量,匹配虚函数的入口。
- 根据入口地址调用虚函数。
C++高级
数据结构
双链表
|
模板(Templates)
- 泛型(Generic Programming)即是指具有在多种数据类型上皆可操作的含意。泛型编程的代表作品 STL 是一种高效、泛型、可交互操作的软件组件。
- 泛型编程最初诞生于
C++中,目的是为了实现C++的 STL(标准模板库)。其语言支持机制就是模板(Templates)。模板的精神其实很简单:参数化类型。换句话说,把一个原本特定于某个类型的算法或类当中的类型信息抽掉,抽出来做成模板参数 T。
函数模板
函数重载实现的泛型
void swap(int& a,int& b){} |
函数模板的引入
- 函数模板,只适用于函数的参数个数相同而类型不同,且函数体相同的情况。如果个数不同,则不能用函数模板。
- 语法格式
template<typename/class 类型参数表> |
- template 是语义是模板的意思,尖括号中先写关键字 typename 或是 class ,后面跟一个类型 T,此类即是虚拟的类型。至于为什么用 T,用的人多了,也就是 T 了。
template<typename T> |
类模板
- 由类模板,会生成对应的类,再生成类对象。
- 类模板语法
//---------类模板定义 |
模板别名
template<class T> using t=T;//模板别名 |
模板元
- 用于代码递归加速,把运行耗费的时间改为编译中处理
|
IO 流
- 在
C++中cin和cout充当了scanf和printf的功能。但他们并不是函数。而是类对象。
- 特点
- IO对象不可复制或赋值
- IO对象是缓冲的,下面几种情况会导致刷缓冲
- 程序正常结束,作为 main 函数结束的一部分,将清空所有缓冲区。
- 缓冲区满,则会刷缓冲。
- endl, flush 也会刷缓冲。
- 在每次输出操作执行完后,用 unitbuf 操作符设置流的内部状态,从而清空缓冲区。
- 重载了<< 和 >>运算符
输入输出 IO 流
标准输出
- C++提供的输出流对象有:
- cout:输出基本类型数据时,不必考虑数据是什么类型,系统会自动判断,选择相应的重载函数;输出用户自己定义的类型数据时,要重载<<运算符。
- cerr:是在屏幕上显示出错信息,与 cout 用法类似,不同的是只能在屏幕上,而不能在磁盘文件上输出错误信息;
- clog:用法与 cerr 类似,不同点是它带有缓冲区。
引用流算子iomanip
- 系统自带了一些格式化方法,不过设置很麻烦
cout.unsetf(ios::dec); //取消10进制 |
- 引用流算子
| 控制符 | 功能 | 举例 |
|---|---|---|
| dec hex oct |
十进制数输出 十六进制输出 八进制数输出 |
cout<<"十进制 :"<<n<<endl;cout<<"十六进制:"<<hex<<n<<endl;cout<<"八进制 :"<<oct<<n<<endl; |
| setfill© | 在给定的输出域宽度内填充字符 c,需要与 setw(n)合用 | cout<<setfill('*')<<setw(5)<<x<<endl; |
| setprecison(n) | 设显示小数精度为 n 位,自动四舍五入 | cout<<setprecision(2)<<dd<<endl; |
| setw(n) | 设域宽为 n 个字符 | cout<<setw(10)<<m<<endl; |
| setiosflags(ios::fixed) | 固定的浮点显示,此时精度域表示小数位数 | cout<<setiosflags(ios::fixed)<<dd<<endl; |
| setiosflags(ios::scientific) | 指数显示,科学记数法,此时精度域表示小数位数 | cout<<setiosflags(ios::scientific)<<dd<<endl; |
| setiosflags(ios::left) | 左对齐 | cout<<setiosflags(ios::left)<<setw(10)<<y<<endl; |
| setiosflags(ios::right) | 右对齐 | |
| setiosflags(ios::showpoint) | 强制显示小数点和尾 | cout<<setiosflags(ios::showpoint)<<d1<<endl; |
| setiosflags(ios::showpos) | 强制显示符号 | cout<<setiosflags(ios::showpos)<<d2<<endl; |
| setiosflags(ios::skipws) | 忽略前导空白 | |
| setiosflags(ios::uppercase) | 十六进制数大写输出 | cout<<"以大写方式输出进制数: "<<setiosflags(ios::uppercase)<<hex<<num<<endl; |
| setiosflags(ios::lowercase) | 十六进制数小写输出 | cout<<"16 进制数(默认:小写方式):"<<hex<<num<<endl; |
| setiosflags(ios::showbase) | 当按十六进制输出数据时,前面显示前导符 0x;当按八进制输出数据时,前面显示前导符 0 | |
| endl | 输入一个换行符并刷新流 | |
| resetiosflags |
标准输入 cin
- 在 C++中,默认的标准输入设备是键盘,在 iostream 文件中定义了 cin 输入流对象。
- cin 对象与提取运算符>>、变量名或数组名一起构成输入语句,形式为 C++的格式化输入。
- cin>>…>>…>>…;,能够连续输入多项内容。只要是基本数据类型,不管是 int、double、float,还是
char、char *等,都可以写成这种形式,这给用户提供了很大的方便。如果要输入用户自己定义的类型数据,就要用友元方式重载>>运算符;
成员函数
| 控制符 | 功能 | 举例 |
|---|---|---|
char get() |
读入一个字符并返回(包括回车、tab、空格等空白字符),遇到ctrl+z才结束 | |
istream& get(char &) |
读入一个字符,如果读取成功则返回非 0 值(真),如失败(遇到文件结束符),则函数返回 0 值(假)。 | |
istream& get(char *, int ,char ) |
istream& get(字符数组,字符个数 n,终止字符) istream & get(字符指针,字符个数 n,终止字符)从输入流中读取 n-1 字符,赋给字符数组或字符指针所指向的数组。如果在读取 n-1 个字符之前遇到终止字符,则提前结束。如果成功则返回非 0,失败 则返回 0。会清空 char*指向的空间,未读到 n-1 个字符或中止符,则会阻塞。不会越过中止符。 |
|
istream& getline(char *, int , char) |
与带三个参数的 get()功能类似,从输入流中读取 n-1 字符,赋给字符数组或字符指针所指向的空间。如果在读取 n-1 个字符之前遇到终止字符(如果不写,默认为’\n’),则提前结束。会清空 char*指向的空间,未读到 n-1 个字符或中止符,则会阻塞。会越过中止符 |
|
istream&ignore(streamsize n = 1, int delim= EOF); |
跳过流中的 n 个字符,或遇到终止字符为止(包含), 默认参数忽略一个字符。 | |
int peek(); |
窥视 当前指针未发生移动 | |
istream& putback (char c); |
回推 插入当前指针位置 |
- get 和 getline 最大的区别就是,get 遇到界定符时,停止执行,但并不从流中提取界定符,再次调用会遇到同一个界定符,函数将立即返回,不会提取输入。getline 则不同,它将从输入流中提供界定符,但不会把它放到缓冲区中。
文件 IO 流
- 指程序与数据的交互是以流的形式进行的.进行 C 语言文件的存取时,都会先进行“打开文件”操作,这个操作就是在打开数据流,而“关闭文件”操作就是关闭数据流。
缓冲区(Buffer)
-
指在程序执行时,所提供的额外内存,可用来暂时存放做准备执行的数据.它的设置是为了提高存取效率,因为内存的存取速度比磁盘驱动器快得多. C++ 语言中带缓冲区的文件处理:
-
C++ 语言的文件处理功能依据系统是否设置“缓冲区”分为两种:
- 一种是设置缓冲区
- 另一种是不设置缓冲区
-
当使用标准 I/O 函数(包含在头文件 cstdio 中)时,系统会自动设置缓冲区,并通过数据流来读写文件. 当进行文件读取时,不会直接对磁盘进行读取,而是先打开数据流,将磁盘上的文件信息拷贝到缓冲区内,然后程序再从缓冲区中读取所需数据,如下图所示:
-
文件类型分为文本文件和二进制文件两种.
-
文件存取方式:包括顺序存取方式和随机存取方式两种.
- 顺序读取:也就是从上往下,一笔一笔读取文件的内容.保存数据时,将数据附加在文件的末尾.这种存取方式常用于文本文件,而被存取的文件则称为顺序文件.
- 随机存取:多半以二进制文件为主.它会以一个完整的单位来进行数据的读取和写入,通常以结构为单位.
借助文件指针读写文件
- 我们如果要访问文件,要借助于文本变量,即文件指针
FILE *才可以完成。文件在进行读写操作之前要先打开,使用完毕要关闭.所谓打开文件,实际上是建立文件的各种有关信息,并使文件指针指向该文件,以便进行其它操作.关闭文件则断开指针与文件之间的联系,也就禁止再对该文件进行操作。
文件流类与文件流对象
- 对文件的操作是由文件流类完成的。文件流类在流与文件间建立连接。由于文件流分为三种:文件输入流、文件输出流、文件输入/输出流,所以相应的必须将文件流说明为 ifstream、ofstream 和 fstream 类的对象,然后利用文件流的对象对文件进行操作。
- 对文件的操作过程可按照一下四步进行:即定义文件流类的对象、打开文件、对文件进行读写操作、关闭文件。
文件的打开和关闭
定义流对象
| 流类 | 流对象 |
|---|---|
| ifstream ifile; | 定义一个文件输入流对象 |
| ofstream ofile; | 定义一个文件输出流对象 |
| fstream iofile; | 定义一个文件输出/输入流对象 |
打开文件
- 定义了文件流对象后,就可以利用其成员函数 open()打开需要操作的文件,该成员函数的函数原型为:
void open(const unsigned char *filename,int mode,int access=filebuf:openprot);其中:filename 是一个字符型指针,指定了要打开的文件名;mode 指定了文件的打开方式,其值如下表所示;access 指定了文件的系统属性:
| 文件打开方式 | 值 | 含 义 |
|---|---|---|
| ios::in | 0x01 | 以输入(读)方式打开文件,若文件不存在则报错。 |
| ios::out | 0x02 | 以输出(写)方式打开文件, 若文件不存则创建。 |
| ios::app | 0x08 | 打开一个文件使新的内容始终添加在文件的末尾,若文件不存在,则报错。 |
| ios::trunc | 0x10 | 若文件存在,则清除文件所有内容;若文件不存在,则创建新文件。 |
| ios::binary | 0x80 | 以二进制方式打开文件,缺省时以文本方式打开文件。 |
| ios::nocreate | 0x20 | 打开一个已有文件,若该文件不存在,则打开失败。 |
| ios::noreplace | 0x40 | 若打开的文件已经存在,则打开失败。 |
- 说明:
- 在实际使用过程中,可以根据需要将以上打开文件的方式用“|”组合起来。如:
ios::in|ios::out 表示以读/写方式打开文件 |
- 如果未指明以二进制方式打开文件,则默认是以文本方式打开文件。
- 对于 ifstream 流, mode 参数的默认值为 ios::in,
- 对于 ofstream 流,mode 的默 认值为 ios::out|ios::trunc,
- 对于 fstream 流, mode 的默认值为 ios::int|ios::out|ios::app
- 也可以通过,构造函数打开文件。
- 出错处理是通过,对类对象进行判断的。若文件打开成功,返回 1,否则返回 0
文件的关闭
- 在文件操作结束(即读、写完毕)时应及时调用成员函数 close()来关闭文件。该函数比较简单,没有参数和返回值。
ifstream ifs("xxx.txt",ios::in); |
流文件状态与判断
- 系统为了标识当前文件操作的状态,提供了标识位和检查标识位的函数。
- 标识位:
ios_base.h
| 函数 | 说明 |
|---|---|
| eof() | 如果读文件到达文件末尾,返回 true。 |
| bad() | 如果在读写过程中出错,返回 true 。例如:当我们要对一个不是打开为写状态的文件进行写入时,或者我们要写入的设备没有剩余空间的时候。 |
| fail() | 除了与 bad() 同样的情况下会返回 true 以外,加上格式错误时也返回 true ,例如当想要读入一个整数,而获得了一个字母的时候。或是遇到 eof。 |
| good() | 这是最通用的:如果调用以上任何一个函数返回 true 的话,此函数返回 false 。 |
| clear() | 标识位一旦被置位,这些标志将不会被改变,要想重置以上成员函数所检查的状态标志,你可以使用成员函数 clear(),没有参数。比如:通过函数移动文件指针,并不会使 eofbit |
| 自动重置。 |
文件的读写操作
- 在打开文件后就可以对文件进行读写操作了。从一个文件中读出数据,可以使用文件流类的 get、getline、read 成员函数以及运算符“>>”;
- 而向一个文件写入数据,可以使用其 put、write 函数以及插入符“<<”,如下表所示:
流状态的查询和控制
- 可以如下管理输入操作
- 这个循环不断读入 cin,直到到达文件结束符或者发生不可恢复的读取错误为止。循环条件使用了逗号操作符。回顾逗号操作符的求解过程:首先计算它的每一个操作数,然后返回最右边操作数作为整个操作的结果。因此,循环条件只读入 cin 而忽略了其结果。该条件的结果是 !cin.eof() 的值。如果 cin 到达文件结束符,条件则为假,退出循环。如果 cin没有到达文件结束符,则不管在读取时是否发生了其他可能遇到的错误,都进入循环在循环中,首先检查流是否已破坏。如果是的放,抛出异常并退出循环。如果输入无效,则输出警告并清除 failbit 状态。在本例中,执行 continue 语句,回到 while 的开头,读入另一个值 ival。如果没有出现任何错误,那么循环体中余下的部分则可以很安全地使用ival
读写文件本文件
- 读出:
- operator>>
- int get();
- istream& get(int);
- istream & get(char*,int n, char deli ) istream& getline(char * ,int n);
- 写入:
- operator<<
- osream put(int)
读写二进制文件
ostream & write(const char * buffer,int len); |
随机读写函数
- 与文件指针相关的函数如下:
| 成员函数 | 作用 |
|---|---|
| tellg(); | 返回当前指针位置 //输入流操作 |
| seekg(绝对位置); | 绝对移动, |
| seekg(相对位置,参照位置); | 相对操作 |
| seekp(绝对位置); | 绝对移动, //输出流操作 |
| seekp(相对位置,参照位置); | 相对操作 |
| tellp(); | 返回当前指针位置 |
- 用于输入的函数。p 代表 put 的意思,用于输出函数。如果是既可输入又可输出的文件,则任意使用。
| 参照位置成员 | 意义 |
|---|---|
| ios::beg = 0 | 相对于文件头 |
| ios::cur = 1 | 相对于当前位置 |
| ios::end = 2 | 相对于文件尾 |
- 代码示例:
infile.seekg(100); //输入文件中的指针向前移到 100 个字节的位置 |
异常(Exception)
-
c 语言中错误的处理,通常采用返回值的方式或是置位全局变量的方式。这就存在两个问题。如果返回值正是我们需要的数据,且返回数据同出错数据容错差不高。全局变量,在多线程中易引发竞争。而且,当错误发生时,上级函数要出错处理,层层上报,造成过多的出错处理代码,且传递的效率低下。为此 c++提供了异常。
-
数组的异常捕获
try{ |
异常语法
-
异常使用
- 把可能发生异常的语句放在 try 语句声当中。try 原有语句的执行流程。
- 若未发生异常,catch 子语句并不起作用。程序会流转到 catch 子句的后面执行。
- 若 try 块中发生异常,则通过 throw 抛出异常。throw 抛出异常后,程序立即离开本函数,转到上一级函数。所以 triangle 函数中的 return 语句不会执行。
- throw 抛出数据,类型不限。既可以是基本数据类型,也可以是构造数据类型。
- 程序流转到 main 函数以后,try 语句块中 抛出进行匹配。匹配成功,执行 catch 语句,catch 语句执行完毕后。继续执行后面的语句。如无匹配,系统调用 terminate 终止程序。
-
语法格式
try{ |
- 语法要点:
- 被检语句必须放在 try 块中,否则不起作用。
- try catch 中花括号不可省。
- 一个 try-catch 结构中,只能有一个 try 块,catch 块却可以有多个。以便与不同的类型信息匹配。
- throw 抛出的类型,既可以是系统预定义的标准类型也可以是自定义类型。从抛出到catch 是一次复制拷贝的过程。如果有自定义类型,要考虑自定义类型的拷贝问题。
- 如果 catch 语句没有匹配异常类型信息,就可以用(…)表示可以捕获任何异常类型的信息。
- try-catch 结构可以与 throw 在同一个函中数中,也可以不在同一个函数中,throw 抛出异常后,先在本函数内寻找与之匹配的 catch 块,找不到与之匹配的就转到上一层,如果上一层也没有,则转到更上一层的 catch 块。如果最终找不到与之匹配的 catch 块,系统则会调有生个系统函数,terminate,使程序终止。
|
抛出类型声明
- 为了加强程序的可读性,可以在函数声明中列出可能抛出的所有异常类型。例如:
void func() throw (A, B, C , D);这个函数 func()能够且只能抛出类型 A B C D及其子类型的异常。 - 如果在函数声明中没有包含异常接口声明,则函数可以抛掷任何类型的异常,例如:
void func(); - 一个不抛掷任何类型异常的函数可以声明为:
void func() throw(); - 如果一个函数抛出了它的异常接口声明所不允许抛出的异常,unexpected 函数会被 调用,该函数默认行为调用 terminate 函数中止程序。
栈自旋
- 异常被抛出后,从进入 try 块起,到异常被抛掷前,这期间在栈上的构造的所有对象,都会被自动析构。析构的顺序与构造的顺序相反。这一过程称为栈的解旋(unwinding)。而堆上的空间,则会泄漏。
STL
C11
Boost
GPU
- amp
|